
web master : nau_maz@yahoo.com
A Research Paper on
DATA WAREHOUSING
by:
Nauman Mazhar, Ammar Sohail, M. Arshad Mughal, Aqsa Khursheed, Aqil Bajwa
students of B.SC(hons), PUCIT
Characteristics of Data warehouses
Components/Basic
elements of a data warehouses
11
Steps To Successful Data Warehousing
Data Warehousing-Database/Hardware Selection
Microsoft
Data Warehousing Framework
DATA WAREHOUSING AND DATA MINING
Data warehousing has
become very popular among organizations seeking to utilize information
technology to gain a competitive advantage. Moreover, many vendors, having
noticed this trend, have begun to manufacture various kinds of hardware,
software, and tools to help data warehouses function more effectively. Despite
the increasing attention to data warehousing, little empirical research has been
published. This study uncovered 456 articles on data warehousing, almost all of
which were in trade journals. In this research paper, we summarize the
development and basic terminologies necessary to understand data warehousing and
present the results of a literature comparative analysis. The study classifies
the data warehousing literature and identifies the advantages and disadvantages
encountered while developing data warehouses.
|
|
|
|
|
|
The
query able source of data in the enterprise.
The
data warehouse is nothing more than the union of all the constituent data marts.
A data warehouse is fed from the data staging area. The data warehouse manager
is responsible both for the data warehouse and the data staging area.
Specifically,
the data warehouse is the query able presentation resource for an enterprise's
data and this presentation resource must not be organized around an
entity-relation model because, if one use entity-relation modeling, he will lose
understandability and performance. Also, the data warehouse is frequently
updated on a controlled load basis as data is corrected, snapshots are
accumulated, and statuses and labels are changed. Finally, the data warehouse is
precisely the union of its constituent data marts.
Characteristic
|
Description of Characteristic
|
Subject
oriented
|
Data are organized by how users refer to it
|
|
Integrated |
Inconsistencies are removed in both nomenclature and
conflicting information. That is, the data are 'clean'
|
|
Non-volatile |
Read only data. Data do not change over time. |
|
Time series |
Data are time series not current status
|
|
Summarized |
Operational data mapped into decision usable form
|
|
Larger |
Keeping time series implies much more data is retained. |
|
Not normalized |
DSS data can be redundant
|
|
Metadata |
Metadata =data about the data. |
|
Input |
Un-integrated, operational environment ('legacy systems') |
Who
Uses Data Warehouses?
Companies
use data warehouses to store information for marketing, sales and manufacturing
to help managers get a feel for the data and run the business more effectively.
Managers use sales data to improve forecasting and planning for brands, product
lines and business areas. Retail purchasing managers use warehouses to track
fast-moving lines and to ensure an adequate supply of high-demand products.
Financial analysts use warehouses to manage currency and exchange exposures,
oversee cash flow and monitor capital expenditures.
|
|
|
|
|
|
Basic
elements
Source System
An
operational system of record whose function it is to capture the transactions of
the business. A
source system is often called a
"legacy system" in a mainframe environment. This definition is
applicable even if, strictly speaking, the source system is not a modern OLTP
(on-line transaction processing) system. In any event, the main priorities of
the source system are uptime and availability. Queries against source systems
are narrow, "account-based" queries that are part of the normal
transaction flow and severely restricted in their demands on the legacy system.
We assume that the source systems maintain little historical data and that
management reporting from source systems is a burden on these systems. We make
the strong assumption that source systems are not queried in the broad and
unexpected ways that data warehouses are typically queried. We also assume that
each source system is a natural stovepipe, where little or no investment has
been made to conform basic dimensions such as product, customer, geography, or
calendar to other legacy systems in the organization. Source systems may well
have embedded notions of keys that make certain things, like product keys or
customer keys, unique. We call these source system keys production keys, and we
treat them as attributes, just like any other textual description of something.
We never use the production keys as the keys within our data warehouse.
Data Staging Area
A
storage area and a set of processes that clean, transform, combine,
de-duplicate, household, archive, and prepare source data for use in the data
warehouse. The
data staging area is everything in between the source system and the data
presentation server. Although it would be nice if the data staging area were a
single centralized facility on one piece of hardware, it is far more likely that
the data staging area is spread over a number of machines. The data staging area
is dominated by the simple activities of sorting and sequential processing and,
in some cases that the data staging area does not need to be based on relational
technology. After you check your data for conformance with all the one-to-one
and many-to-one business rules you have defined, it may be pointless to take the
final step of building a full blown entity-relation based physical database
design.
However,
there are many cases where the data arrives at the doorstep of the data staging
area in a third normal form relational database. In other cases, the managers of
the data staging area are more comfortable organizing their cleaning,
transforming, and combining steps around a set of normalized structures. In
these cases, a normalized structure for the data staging storage is certainly
acceptable. The key defining restriction on the data staging area is that it
does not provide query and presentation services. As soon as a system provides
query and presentation services, it must be categorized as a presentation
server, which is described next.
Presentation Server
The
target physical machine on which the data warehouse data is organized and stored
for direct querying by end users, report writers, and other applications. In our
opinion, three very different systems are required for a data warehouse to
function: the source system, the data staging area, and the presentation server.
The source system should be thought of as outside the data warehouse, since we
assume we have no control over the content and format of the data in the legacy
system. We have described the data staging area as the initial storage and
cleaning system for data that is moving toward the presentation server, and we
made the point that the data staging area may well consist of a system of flat
files. It is the presentation server where we insist that the data be presented
and stored in a dimensional framework. If the presentation server is based on a
relational database, then the tables will be organized as star schemas. If the
presentation server is based on non-relational
on-line
analytic processing (OLAP)
technology, then the data will still have
recognizable dimensions, most of the large data marts (greater than a few
gigabytes) are implemented on relational databases. Thus most of the specific
discussions surrounding the presentation server are couched in terms of
relational databases.
Dimensional Model
A
specific discipline for modeling data that is an alternative to
entity-relationship (E/R) modeling.
A dimensional
model contains the same information as an E/R model but packages the data in a
symmetric format whose design goals are user understandability, query
performance, and resilience to change.
This
discipline (dimensional modeling) is encouraging because too many data
warehouses fail due to overly complex E/R designs. This technique of dimensional
modeling is successfully employed over the last 15 years in hundreds of design
situations.
The
main components of a dimensional model are fact tables and dimension tables,
which are briefly discussed below
Fact
TableC
A fact table is
the primary table in each dimensional model that is meant to contain
measurements of the business. The most useful facts (fact tables) are numeric
and additive. Every fact table represents a many-to-many relationship and every
fact table contains a set of two or more foreign keys that join to their
respective dimension tables.
Dimension
TableC
A dimension table
is one of a set of companion tables to a fact table. Its primary key that serves
as the basis for referential integrity with any given fact table to which it is
joined defines each dimension. Most dimension tables contain many textual
attributes (fields) that are the basis for constraining and grouping within data
warehouse queries.
Business Process
A
coherent set of business activities that make sense to the business users of our
data warehouses.
This
definition is purposefully a little vague. A business process is usually a set
of activities like "order processing" or "customer pipeline
management," but business processes can overlap, and certainly the
definition of an individual business process will evolve over time. Assume that
a business process is a useful grouping of information resources with a coherent
theme. In many cases, one or more data marts for each business process will be
implemented.
Data Mart
A
logical subset of the complete data warehouse. A
data mart is a complete "pie-wedge"
of the overall data warehouse pie. A data mart represents a project that can be
brought to completion rather than being an impossible galactic undertaking. A
data warehouse is made up of the union of all its data marts. Beyond this rather
simple logical definition, we often view the data mart as the restriction of the
data warehouse to a single business process or to a group of related business
processes targeted toward a particular business group. The data mart is probably
sponsored by and built by a single part of the business and a data mart is
usually organized around a single business process.
Every
data mart is imposed with some very specific design requirements. Every data
mart must be represented by a dimensional model and, within a single data
warehouse, all such data marts be built from conformed dimensions and conformed
facts. This is the basis of the data warehouse bus architecture. Without
conformed dimensions and conformed facts, a data mart is a stovepipe. Stovepipes
are the bane of the data warehouse movement. If one has any hope of building a
data warehouse that is robust and resilient in the facing of continuously
evolving requirements, one must adhere to the data mart definition recommended.
when data marts have been designed with conformed dimensions and conformed
facts, they can be combined and used together.
We do
not believe that there are two "contrasting" points of view about
top-down vs. bottom-up data warehouses. The extreme top-down perspective is that
a completely centralized, tightly designed master database must be completed
before parts of it are summarized and published as individual data marts. The
extreme bottom-up perspective is that an enterprise data warehouse can be
assembled from disparate and unrelated data marts. Neither approach taken to
these limits is feasible. In both cases, the only workable solution is a blend
of the two approaches, where we put in place a proper architecture that guides
the design of all the separate pieces.
When
all the pieces of all the data marts are broken down to individual physical
tables on various database servers, as they must ultimately be, then the only
physical way to combine the data from these separate tables and achieve an
integrated enterprise data warehouse is if the dimensions of the data mean the
same thing across these tables. These are called conformed dimensions. This data
warehouse bus architecture is a fundamental driver for this book.
Finally,
we do not adhere to the old data mart definition that a data mart is comprised
of summary data. Data marts are based on granular data and may or may not
contain performance enhancing summaries, which we call "aggregates".
Operational
Data Store (ODS)
The
ODS is currently defined by various authors to be a kind of kitchen sink for a
diverse and incompatible set of business requirements that include querying very
current volatile data, cleaning data from legacy systems, and using
enterprise
resource planning (ERP).
The lack of a single, usable definition of
the ODS suggests that this concept should be
revised or eliminated from vocabulary. The operational data store was originally
defined as a frequently updated, volatile, integrated copy of data from
operational systems that is meant to be accessed by "clerks and
executives." This original ODS was specifically defined to lack
performance-enhancing aggregations and to lack supporting time histories of
prior data. In our opinion, this definition is filled with contradictions and is
no longer useful. Data warehousing has matured to the point where a separate
copy of operational data that is not the data warehouse is an unnecessary
distraction. The operational data is a full participant in the data warehouse
and enjoys the advantages of performance-enhancing aggregations and associated
time histories. Additionally, we have done away with the need to design a
separate data pipeline feeding an isolated ODS.
Because
we don't think the ODS is anything more than the front edge of the kind of data
warehouses we design.
OLAP (On-Line Analytic Processing)
The
general activity of querying and presenting text and number data from data
warehouses, as well as a specifically dimensional style of querying and
presenting that is exemplified by a number of "OLAP vendors." The
OLAP vendors' technology is non-relational and is almost always based on
an explicit multidimensional cube of data. OLAP databases are also known as
multidimensional databases, or MDDBs. OLAP installations are classified as
small, individual data marts when viewed against the full range of data
warehouse applications. We believe that OLAP style data marts can be full
participants on the data warehouse bus if they are designed around conformed
dimensions and conformed facts.
ROLAP
(Relational OLAP) C A
set of user interfaces and applications that give a relational database a
dimensional flavor.
MOLAP (Multidimensional OLAP)
C
A
set of user interfaces, applications, and proprietary database technologies that
have a strongly dimensional flavor.
Figure 1:
The three types of
multidimensional data found in OLAP applications. Data from external sources
(represented by the blue cylinder) is copied into the small red marble cube,
which represents input multidimensional data; pre-calculated, stored results
derived from it are shown by the multi-colored brick cube built around it; and
the large wooden stack represents on-the-fly results, calculated as required at
run-time, but not stored in a database.
Figure2:
 |
End User Application
A
collection of tools that query, analyze, and present information targeted to
support a business need. A
minimal set of such
tools would consist of an end user data access tool, a spreadsheet, a graphics
package, and a user interface facility for eliciting prompts and simplifying the
screen presentations to end users.
End User Data Access Tool
A
client of the data warehouse. In
a relational data warehouse, such a client maintains a session with the presentation
server, sending a stream of separate SQL requests to the server. Eventually the
end user data access tool is done with the SQL session and turns around to
present a screen of data or a report, a graph, or some other higher form of
analysis to the user. An end user data access tool can be as simple as an ad hoc
query tool, or can be as complex as a sophisticated data mining or modeling
application. A few of the more sophisticated data access tools like modeling or
forecasting tools may actually upload their results into special areas of the
data warehouse.
Ad Hoc Query Tool
A
specific kind of end user data access tool that invites the user to form their
own queries by directly manipulating relational tables and their joins.
Ad hoc
query tools, as powerful as they are, can only be effectively used and
understood by about 10 percent of all the potential end users of a data
warehouse. The remaining 90 percent of the potential users must be served
by pre-built applications that are much more finished "templates" that
do not require the end user to construct a relational query directly. The very
best ROLAP-oriented ad hoc tools improve the 10 percent number to perhaps 20
percent.
Modeling Applications
A
sophisticated kind of data warehouse client with analytic capabilities that
transform or digest the output from the data warehouse.
Modeling applications include:
þ
Forecasting models that try to
predict the future
þ
Behavior scoring models that
cluster and classify customer purchase behavior or customer credit behavior
þ
Allocation models that take cost
data from the data warehouse and spread the costs across product groupings or
customer groupings
þ
Most data mining tools
Metadata
Basic
Processes of the Data Warehouse
Data
staging C
is a major process
that includes the following sub processes: extracting, transforming, loading and
indexing, and quality assurance checking.
Extracting
C
the extract step
is the first step of getting data into the data warehouse environment. We use
this term more narrowly than some consultants. Extracting means reading and
understanding the source data, and copying the parts that are needed to the data
staging area for further work.
Transforming
C
once the data is
extracted into the data staging area, there are many possible transformation
steps, including
þ
Cleaning the data by correcting
misspellings, resolving domain conflicts (such as a city name that is
incompatible with a postal code), dealing with missing data elements, and
parsing into standard formats
þ
Purging selected fields from the
legacy data that are not useful for the data warehouse
þ
Combining data sources, by
matching exactly on key values or by performing fuzzy matches on non-key
attributes, including looking up textual equivalents of legacy system codes
þ
Building aggregates for boosting
the performance of common queries
þ
Creating surrogate keys for each
dimension record in order to avoid a dependence on legacy defined keys, where
the surrogate key generation process enforces referential integrity between the
dimension tables and the fact tables
Loading
and Indexing C
At the end of the
transformation process, the data is in the form of load record images. Loading
in the data warehouse environment usually takes the form of replicating the
dimension tables and fact tables and presenting these tables to the bulk loading
facilities of each recipient data mart. Bulk loading is a very important
capability that is to be contrasted with record-at-a-time loading, which is far
slower. The target data mart must then index the newly arrived data for query
performance, if it has not already done so.
Quality
Assurance Checking C
When each data
mart has been loaded and indexed and supplied with appropriate aggregates, the
last step before publishing is the quality assurance step. Running a
comprehensive exception report over the entire set of newly loaded data can
check quality assurance. All the reporting categories must be present, and all
the counts and totals must be satisfactory. All reported values must be
consistent with the time series of similar values that preceded them. The
exception report is probably built with the data mart's end user report writing
facility.
Release/Publishing
C
When each data mart has been freshly
loaded and quality assured, the user community must be notified that the new
data is ready. Publishing also communicates the nature of any changes that have
occurred in the underlying dimensions and new assumptions that have been
introduced into the measured or calculated facts.
Updating
C
Contrary to the
original religion of the data warehouse, modern data marts may well be updated,
sometimes frequently. Incorrect data should obviously be corrected. Changes in
labels, changes in hierarchies, changes in status, and changes in corporate
ownership often trigger necessary changes in the original data stored in the
data marts that comprise the data warehouse, but in general these are
"managed load updates," not transactional updates.
Querying
C
Querying is a
broad term that encompasses all the activities of requesting data from a data
mart, including ad hoc querying by end users, report writing, complex decision
support applications, requests from models, and full-fledged data mining.
Querying never takes place in the data staging area. By definition, querying
takes place on a data warehouse presentation server. Querying, obviously, is the
whole point of using the data warehouse.
Data
Feedback/Feeding in Reverse C
There are two important places where
data flows "uphill" in the opposite direction from the traditional
flow. First, we may upload a cleaned dimension description from the data staging
area to a legacy system. This is desirable when the legacy system recognizes the
value of the improved data. Second, we may upload the results of a complex query
or a model run or a data mining analysis back into a data mart. This would be a
natural way to capture the value of a complex query that takes the form of many
rows and columns that the user wants to save.
Auditing
C
At times it is
critically important to know where the data came from and what were the
calculations performed. A technique id used for creating special audit records
during the extract and transformation steps in the data staging area. These
audit records are linked directly to the real data in such a way that a user can
ask for the audit record (the lineage) of the data at any time.
Securing
C
Every data
warehouse has an exquisite dilemma: How to publish the data widely to as many
users as possible with the easiest-to-use interfaces, but at the same time how
to protect the valuable sensitive data from hackers, snoopers, and industrial
spies. The development of the Internet has drastically amplified this dilemma.
The data warehouse team must now include a new senior member: the data warehouse
security architect. Data warehouse security must be managed centrally, from a
single console. Users must be able to access all the constituent data marts of
the data warehouse with a single sign-on.
Data warehousing components
þ
A data warehouse always consists
of a number of components, which can include:
þ
Operational
data sources
þ
Design/development
tools
þ
Data
extraction and transformation tools
þ
Database
management system
þ
Data
access and analysis tools
þ
System
management tools
Several years ago,
Microsoft recognized the crucial need for a set of integrating technologies that
allows these many vendors' products to work together easily. This recognition
led to the creation of the Microsoft Data Warehousing Framework, a roadmap not
only for the development of Microsoft products such as SQL Server 7.0, but also
the technologies necessary to integrate products from many other vendors,
including both Microsoft business partners and competitors.

|
|
|
|
|
|
þ
Operational
Database / External Database Layer
þ
Information
Access Layer
þ
Data
Access Layer
þ
Data
Directory (Metadata) Layer
þ
Process
Management Layer
þ
Application
Messaging Layer
þ
Data
Warehouse Layer
þ
Data
Staging Layer

Data Warehouse Architecture
1)
Operational Database / External Database Layer
Operational systems
process data to support critical operational needs. This difficulty in accessing
operational data is amplified by the fact that many operational systems are
often 10 to 15 years old. The age of some of these systems means that the data
access technology available to obtain operational data is itself dated.
Increasingly, large
organizations are acquiring additional data from outside databases. The
so-called "information superhighway" is providing access to more data
resources every day.
2)
Information Access Layer
The Information Access
layer of the Data Warehouse Architecture is the layer that the end-user deals
with directly.
3)
Data Access Layer
The Data Access Layer
of the Data Warehouse Architecture is involved with allowing the Information
Access Layer to talk to the Operational Layer. The Data Access Layer not only
spans different DBMSs and file systems on the same hardware, it spans
manufacturers and network protocols as well. One of the keys to a Data
Warehousing strategy is to provide end-users with "universal data
access". The Data Access Layer then is responsible for interfacing between
Information Access tools and Operational Databases.
In order to provide for
universal data access, it is absolutely necessary to maintain some form of data
directory or repository of meta-data information. Meta-data is the data about
data within the enterprise. Record descriptions in a COBOL program are
meta-data. The information in an ERA diagram is also meta-data.
In order to have a
fully functional warehouse, it is necessary to have a variety of meta-data
available, data about the end-user views of data and data about the operational
databases. Ideally, end-users should be able to access data from the data
warehouse (or from the operational databases) without having to know where that
data resides or the form in which it is stored.
5)
Process Management Layer
The Process Management
Layer is involved in scheduling the various tasks that must be accomplished to
build and maintain the data warehouse and data directory information.
6)
Application Messaging Layer
Application Messaging
in the transport system underlying the Data Warehouse.
7)
Data Warehouse (Physical) Layer
The (core) Data
Warehouse is where the actual data used primarily for informational uses occurs.
In some cases, one can think of the Data Warehouse simply as a logical or
virtual view of data. In many instances, the data warehouse may not actually
involve storing data.
8)
Data Staging Layer
The final component of
the Data Warehouse Architecture is Data Staging. Data Staging is also called
copy management or replication management, but in fact, it includes all of the
processes necessary to select, edit, summarize, combine and load data warehouse
and information access data from operational and/or external databases.
Data Staging often involves complex programming, but increasingly data warehousing tools are being created that help in this process.
Building
a Data Warehouse
Building a Data Warehouse
involves extracting data from various operational databases and populating a
specialized Data Warehouse database which users can then access without
impacting the operational systems. An extensive effort is required to select,
map and transform the data that goes into the warehouse, as well as a powerful
front-end tool that allows users to easily retrieve and analyze the newly
available information.
The first step is to access the appropriate operational data from the variety of
legacy databases that exist across the corporation's diverse computing
environments. Once accessed, extraction tools transform the data into a
consistent, integrated form. This process involves cleaning, reconciling,
de-normalizing, and summarizing data, and then loading the data into logical
views that can be surfaced into a variety of analytical and reporting
applications. Once this data is in the warehouse, business analysts can use
business intelligence tools to exploit the data for effective decision-making.
Many organizations opt to set up a framework
that provides an enterprise-wide solution using components such as
extraction/transformation tools, a relational database, data access and
reporting tools, OLAP EIS (Executive Information System) tools, the Internet,
data mining tools, and development tools and utilities. When the Data Warehouse
becomes too complex, there are middleware products which help to make the Data
Warehouse easy to use and manage.

|
|
|
|
|
|
More
and more companies are using data warehousing as a strategy tool to help them
win new customers, develop new products, and lower costs. Searching through
mountains of data generated by corporate transaction systems can provide
insights and highlight critical facts that can significantly improve business
performance.
Until
recently, data warehousing has been an option mostly for big companies, but the
reduced costs of warehousing technology make it practical -- often even a
competitive requirement for -- smaller companies as well. Turnkey integrated
analytical solutions are reducing the cost, time, and risk involved in data
warehouse implementations. While access to the warehouse was previously limited
to highly trained analytical specialists, corporate portals now make it possible
to grant data access to hundreds or thousands of employees.
Following are some steps to consider in implementing your data warehousing
solution.
1.
Recognize that the job is probably harder than you expect.
2.
Understand the data in your existing systems.
3.Be
sure to recognize equivalent entities.
4. Use
metadata to support data quality.
5.
Select the right data transformation tools.
6.
Take advantage of external resources.
7.
Use new information distribution methods.
8.
Focus on high-payback marketing applications.
9.
Emphasize early wins to build support throughout the organization.
10.
Don't underestimate hardware requirements.
11.
Consider outsourcing your data warehouse development and maintenance.
Data
Warehousing - Database/Hardware Selection
In making selection for
the database/hardware platform, there are several items that need to be
carefully considered:
Scalability C
How can the
system grow as your data storage needs grow? Which RDBMS and hardware platform
can handle large sets of data most efficiently? To get an idea of this, one
needs to determine the approximate amount of data that is to be kept in the data
warehouse system once it's mature, and base any testing numbers from there.
Parallel Processing Support C The days of multi-million dollar supercomputers with one single CPU are gone, and nowadays the most powerful computers all use multiple CPUs, where each processor can perform a part of the task, all at the same time. Parallel computing is gaining popularity now, although a little slower than one originally thought.
Popular relational
databases
þ
Oracle
þ
IBM
DB2
þ
Sybase
Popular hardware
platforms
þ
Sun
þ
IBM
COST:
Data warehouses are not
cheap. Multimillion-dollar costs are common. Their design and implementation is
still an art and they require considerable time to create.
SIZE:
Being designed for the
enterprise so that everyone has a common data set, they are large and increase
in size with time. Typical storage sizes run from 50 gigabytes to over a
terabyte.
Because of the large
size, some firms are using parallel computing to speed data retrieval.
|
|
|
|
|
The
goal of the Data Warehouse Framework is to simplify the design, implementation,
and management of data warehousing solutions. This framework has been designed
to provide:
þ An open architecture that is integrated easily with and extended by third party vendors
þ
Heterogeneous data import, export,
validation and cleansing services with optional data lineage
þ
Integrated metadata for warehouse
design, data extraction/transformation, server management, and end-user analysis
tools
þ
Core management services for
scheduling, storage management, performance monitoring, alerts/events, and
notification
The Microsoft Data
Warehousing Framework is the roadmap for product development and integration on
the Microsoft platform.

The Data Warehousing
Framework has been designed from the ground up to provide an open architecture
that can be extended easily by Microsoft customers and business partners using
industry standard technology. This allows organizations to choose best of breed
components and still be assured of integration.
Ease-of-use is a
compelling reason for customers and independent software vendors to choose the
Microsoft Data Warehousing Framework. Microsoft provides an object-oriented set
of components that are designed to manage information in the distributed
environment. Microsoft is also providing both entry-level and best-of-breed
products to address the many steps in the data warehousing The process.
|
|
|
|
|
|
The difficulties information technology managers face when
they tackle this task have been chronicled many times. A recent study by the
Data Warehousing Institute of Gaithersburg, Md., for instance, found that almost
one-third of IT managers surveyed indicated that their efforts to collect data
did not meet expectations.
More often than not, projects failed simply because the data
that IT departments want to collect from legacy sources is inaccurate,
inconsistent or difficult to acquire in its original form.
This guide focuses on commercial data warehouse tools that
perform the data extraction, transformation and loading (ETL) functions.
Industry analysts typically define extraction as the process
of identifying and retrieving a set of data from an operational system.
Transformation tools play a key role as IT managers integrate data from multiple
sources. They permit a system administrator to develop rules for integrating
data from different sources and tables to form a single table or entity.
Just as crucial is the process of formatting the output from
the transformation process into a form acceptable to the target database’s
load utility. This typically includes the use of a scheduling mechanism to
trigger the loading process.
All of these functions usually are performed by a single set
of tools. The tool sets also often support a metadata repository and a
scheduling engine.
IT managers facing the prospect of integrating data from
multiple sources into a single repository traditionally have had to start by
grappling with the build-or-buy question.
There are excellent reasons to build your own ETL system.
First, your in-house programming staff is invariably better acquainted with the
legacy database and operating environment than any vendor could be. Second, few
IT department personnel have the free time to evaluate, compare, select and
install commercial tools, let alone learn to properly use them. And finally, few
IT budgets today can afford the additional capital expense of the tools,
especially for a first-time, proof-of-concept project.
Despite the valid arguments for building your own system,
vendors have over the past few years made a convincing case for buying one
instead.
The learning curve issue is a good example. Vendors have
dramatically shortened the time it takes a developer to get up to speed with an
ETL tool by integrating highly graphical and wizard-driven interfaces that guide
developers through the implementation process.
Today, developers can construct data flow diagrams to
visually model a task and automatically extract, transform, validate and load
data without writing a single line of code. And highly intuitive interfaces are
simplifying the task of mapping such things as complex enterprise resource
planning data to a target database.
At the same time, vendors are extending the scope of their
tool sets and putting an end to the days when developers had to write code to
string together different functions. Products such as Oracle Warehouse Builder,
for example, replace a bevy of individual point tools with a single common
environment capable of modeling and design, data extraction, loading,
aggregation and warehouse administration.
|
|
In addition, many
tools such as Warehouse Builder, IBM’s Visual Warehouse, Computer Associates
International Inc.’s DecisionBase and others add extensive metadata management
capabilities.
Tool performance isn’t taking a backseat, either. Many
vendors have recently added enhanced loading capabilities for the leading target
databases. New loaders in Hummingbird Ltd.’s Genio Suite, for instance,
significantly reduce the time required to manage large volumes of transactions.
Other products, like Formation from Informix Software Inc.,
integrate parallelism into their architectures to take advantage of all
available CPUs. By automatically segmenting a job across multiple CPUs, such
tools boost performance while making more efficient use of enterprise resources.
Users can even specify parallel settings on individual operators or groups of
operators.
Meanwhile, companies have introduced new techniques to help
reduce the data processing workload, a particularly crucial consideration as
warehouses sag under mountains of data and an escalating number of transactions.
Products such as ChangeDataMove from BMC Software Inc. lets
designers almost instantly reflect in the data warehouse incremental updates and
changes in the operational transaction processing environment.
By tracking the changed records during the input/output
operation, the tool captures changes virtually as soon as they occur. That not
only keeps target databases more current and consistent with source databases
than they have been in the past, but it also allows the tool set to transform
and transport to the target database only the data that has changed, thereby
reducing the workload.
When purchasing an ETL tool, a number of issues are worth
considering. Will the tool support the key legacy databases and data types your
application requires? Will the tool support performance levels that could easily
reach hundreds of transactions per second without adversely affecting
traditional operational performance?
Take a close look at the architecture of the tool as well.
Tools that offer reusable modules, for instance, often can save considerable
development time and effort. If you have already designed a custom in-house
process and are looking to replace it, examine where the current commercial
product can improve efficiency. Will the purchase of this tool force you to
revamp an established process? And if so, what are the costs involved?
At the same time, look for tools that offer performance
enhancements, such as loading files into memory for lookup or adding parallelism
to maximize performance.
One way to prevent the learning curve from undermining your
project is to ask the vendor, as a condition of the sale, to provide someone who
understands how to design with the tool. Such a consultant will come at a high
price, but the investment will be worth it if it guarantees success.
Factor this
Although
vendors continually have enhanced their products, a number of factors in your
legacy systems will affect how well a tool extracts, transforms or loads data.
The availability of network bandwidth, for example, is one issue. Bandwidth
bottlenecks can easily slow down the performance of the most optimized tool.
The volume of data to be moved and collected in a project
also is crucial. With the rise of the Web and electronic commerce, businesses
are continually surprised at how much data they can collect in a short period of
time. Yet the larger the prospective data warehouse, the longer and more complex
the process of extracting, transforming and loading data.
Other issues such as hardware configurations—the amount of
memory and speed of disk performance on the source and target systems—also can
influence the speed of the process, as will the type of interconnect used to
access source and target data. Will the system have native access or use Open
Database Connectivity or some other interface?
Finally, the construction of the target database itself also
will have a major impact on data transfer. Are there constraints in the data
warehouse in terms of the complexity of the data structure or number of indices?
And has the database been tuned to maximize performance?
The task of extracting, transforming and loading the data
from legacy sources into a central repository doesn’t grow any simpler as the
amount of data you collect skyrockets.
But the good news is that there is a wider choice of more
capable and comprehensive tools today than there ever has been.
The key to selecting the right tools will lie in your own
understanding of your operating environment and the unique requirements you face
as you build your data warehouse.
Any
of these 14 tools can help to extract, validate and load data
![]()
|
Vendor |
Product |
Platform
support |
Legacy
data sources |
Targets
supported |
Comments |
Price |
|
|
BMC
Software Inc. |
ChangeDataMove |
NT,
Unix, OS/390 |
IMS,
IMS fast path, CICS/VSAM, VSAM batch, DB2 |
Oracle,
DB2 UDB, Sybase, SQL Server |
Non-intrusive change capture
tool; supports near-real- time transaction-based change data propagation
to enable fast and complete synchronization of data |
$20,000
up |
|
|
Computer
Associates International Inc. |
Decision
Base |
NT,
Unix |
IMS,
VSAM, physical sequential files, DB2, ADABASE, CA-IDMS, enterprise
resource planning systems |
DB2,
OS/390, OS/2 DB2/400, Informix, SQL Server, Oracle, Red Brick, Sybase |
Integrates data transformation
with enterprise repository; includes metadata management capabilities |
$200,000 |
|
|
Constellar
Corp. |
Warehouse
Integrator |
Client:
Win95, NT; Server: NT, HP-UX, Solaris, AIX |
All
major RDBMSes, other data types through Constellar Hub product |
Oracle,
Informix, SQL Server, Sybase, CA Ingres, Red Brick ESSbase, PaBLO, Micro
Strategy DSSAgent, SQL/MP, ODBC |
Dimension reference model
supports management of many types of data warehouses across different
MOLAP and ROLAP platforms; new version adds native support for Oracle
Express and metadata auditing |
$100,000
up |
|
|
Decisionism
Inc. |
Aclue
Decision Support ware Version 2.4 |
Client:
Win95, NT; Server: NT, Solaris AIX |
Flat
files, all major RDBMSes, ODBC |
Oracle
Financial Analyzer, Oracle Express, Hyperion Essbase, SQL Server 7.0 OLAP
Services, all major RDBMSes |
Supports three OLAP platforms;
includes comprehensive audit trail and drill-back capabilities, and
advanced time-server management |
$37,500
up |
|
|
Evolutionary
Technologies International Inc. |
ETI*Extract |
Client:
Win95, NT; Server: NT, AIX, Solaris, HP-UX |
Flat
files, IMS, VSAM, Oracle, Sybase, Teradata, SQL Server, Informix, SAS,
TurboI, IDMS, DB2, SAP R/3 |
Most
major relational databases |
Manages batch, legacy,
near-real-time and clickstream data; latest release adds ability to
control user access to objects in MetaStore, improved administration
metadata audit trail |
$100,000
up |
|
|
Hummingbird
Ltd. |
Genio
Suite 4.0 |
Client:
Win95, NT; Server: NT, Win 2000, Solaris, AIX, HP-UX |
All
major file formats, relational databases and ERP products |
Oracle
Express, Hyperion Essbase |
Provides universal data exchange;
latest version adds views of third-party metadata repositories including
Business Objects' Universes and Cognos' Catalogs; also adds enhanced
loading capabilities for Oracle8 and NCR teradata databases |
Genio
engine: $50,000 for NT, $75,000 for Unix; $20,000 for design tools |
|
|
IBM
Corp. |
Visual
Warehouse |
AIX,
Solaris |
DB2,
Oracle, Informix, SQL Server, CICS/VSAM, IMS |
DB2,
Hyperion Essbase |
Program for large and small
businesses provides a managed OLAP environment and Web-enabled
infrastructure; comes bundled with DB2 UDB |
$36,950
up |
|
|
Informatica
Corp. |
Power
Mart 4.6 |
Client:
Win95, NT; Server: NT, HP-UX, AIX, Solaris |
DB2,
flat files, IMS, Informix, SQL Server, Access, Oracle Sybase, VSA, ODBC |
Flat
files, Informix, SQL Server Access, Oracle, PeopleSoft ERP, SAP Business
Info Warehouse, Sybase |
Integrated suite of products
includes a deploy folder wizard to guide developers, source-extraction
mapping templates, flat-file acceleration, advanced session management and
multilevel security |
$45,375
up for NT $66,000 up for Unix platforms |
|
|
Informix
Software Inc. |
Formation |
NT,
Solaris, HP-UX |
Informix,
Oracle, SQL Server, ODBC, text files, EBCDIC files, binary files |
Informix,
Oracle, SQL Server, ODBC to others |
Integrated autoparallelism
automatically segments jobs across multiple CPUs; includes
user-specifiable parallel settings and native loaders for Informix,
Oracle, SQL Server |
$7,500
up per processor |
|
|
Data
Stage |
NT,
Unix |
Flat
files, VSAM, SQL Server |
SQL
Server |
Former Ardent Software product
provides an automated workflow environment with reusable components |
$47,500
up |
||
|
Oracle
Corp. |
Warehouse
Builder |
Client:
NT; Server: Oracle8i |
Oracle,
DB2 via gateway, ODBC, flat files, IMS, VSAM, Oracle ERP, SAP R/3 |
Oracle8i,
8i Catalog, Discoverer and Express |
Integrates modeling and design,
data extraction, movement and loading, aggregation, metadata management
and tool integration into single solution; has a wizard-driven interface
and is tightly integrated with Oracle8i; integrates metadata via Common
Warehouse Model |
$25
per Universal Power Unit (for UPU, multiply MHz speed of Intel chip by 1;
multiply speed of RISC chip by 1.5) |
|
|
SAS
Institute Inc. |
SAS/Access |
NT,
Unix |
DB2,
SQL Server, Oracle Teradata, SAP R/3, Baan, flat files, text files, binary
files |
Most
file structures |
Supports a variety of file
structures |
$31,664
up for server license with OLAP tool |
|
|
Taurus
Software Inc. |
Data
Bridge |
Client:
Win95, NT; Server: NT, HP-UX, AIX, Solaris, UnixWare, SGI |
MPE,
Oracle, Image, KSAM, Allbase, fixed files, flat files, text files, CSV
files, freeze files |
Unix,
Oracle, fixed files, flat files, text files, CSV files, Freeze files, DB2,
Informix, SQL Server |
ETL tool with portable scripting
language and a GUI that simplifies script development |
$29,000
to $79,000 |
|
|
Bridge
Ware |
Same |
MPE,
Oracle, Image, KSAM, Allbase, fixed files, flat files, text files, CSV
files, freeze files |
Unix,
Oracle, fixed files, flat files, text files, CSV files, Freeze files, DB2,
Informix, SQL Server |
Adds real-time, change detect
component |
|
|
|
|
|
|
|
|
|
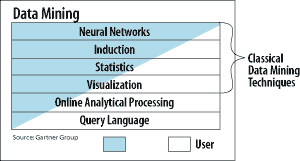 |
Data
mining is usually used for four main purposes:
þ
To improve customer acquisition
and retention;
þ
To reduce fraud;
þ
To identify internal
inefficiencies and then revamp operations;
þ
To map the unexplored terrain of
the Internet. The primary types of tools used in data mining are:
Neural
networks, decision trees, rule induction, and data visualization.
The
link between data mining and data warehousing is explained as follows:
Data Warehousing is the strategy of ensuring that the data used in an organization is available in a consistent and accurate form wherever it is needed. Often this involves the replication of the contents of departmental computers in a centralized site, where it can be ensured that common data definitions are in the departmental computers in a centralized site, where it can be ensured that the common data definitions are in use… The reason Data Warehousing is closely connected with Data Mining is that when data about the organization’s processes becomes readily available, it becomes easy and therefore economical to mine it for new and profitable relationships.
Thus,
data warehousing introduces greater efficiencies to the data mining exercise.
“Without the pool of validated and scrubbed data that a data warehouse
provides, the data mining process requires considerable additional effort to
pre-process the data. Notwithstanding, it is also possible for companies to
obtain data from other sources via the Internet, mine the data, and then convey
the findings and new relationships internally within the company via an
Intranet. There are four stages in the data warehousing process:
þ
The first stage is the
acquisition of data from multiple internal and external sources and platforms.
þ
The second stage is the management of the acquired data in a
central, integrated repository.
þ
Stage three is the provision of
flexible access, reporting and analysis tools to interpret selected data.
þ
Stage four is the production of
timely and accurate corporate reports to support managerial and decision-making
processes.
Though
the term data mining is relatively new, the technology is not. Many of the
techniques used in data mining originated in the artificial intelligence
research of the 80s and 90s. It is only more recently that these tools have been
applied to large databases. Why then are data mining and data warehousing
mushrooming now? IBM has identified six factors that have brought data mining to
the attention of the business world:
þ
A general recognition that there
is untapped value in large databases;
þ
A consolidation of database
records tending toward a single customer view;
þ
A consolidation of databases,
including the concept of an information warehouse;
þ
A reduction in the cost of data
storage and processing, providing for the ability to collect and accumulate
data;
þ
Intense competition for a
customer’s attention in an increasingly saturated marketplace;
þ
The movement toward the de-massification
of business practices.
With
reference to point six above, “de-massification” is a term originated by
Alvin Toffler. It refers to the shift from mass manufacturing, mass advertising
and mass marketing that began during the industrial revolution, to customized
manufacturing, advertising and marketing targeted to small segments of the
population.
Data
mining usually yields five types of information: associations, sequences,
classifications, clusters, and forecasting:
Associations
happen when occurrences are linked in a single event. For example, a study of
supermarket baskets might reveal that when corn chips are purchased, 65% of the
time cola is also purchased, unless there is a promotion, in which case cola is
purchased 85% of the time.
In
sequences, events are linked over time. [For example][ I]f a house is bought,
then 45% of the time a new oven will be bought within one month and 60% of the
time a new refrigerator will be bought within two weeks.
Classification
is probably the most common data mining activity today… Classification can
help you discover the characteristics of customers who are likely to leave and
provide[s] a model that can be used to predict who they are. It can also help
you determine which kinds of promotions have been effective in keeping which
types of customers, so that you spend only as much money as necessary to retain
a customer.
Using
clustering, the data mining tool discovers different groupings with the data.
This can be applied to problems as diverse as detecting defects in manufacturing
or finding affinity groups for bank cards.
All
of these applications may involve predictions, such as whether a customer will
renew a subscription … [f]orecasting, is a different form of prediction. It
estimates the future value of continuous variables — like sales figures —
based on patterns within the data.17
Generally
then, applications of data mining can generate outputs such as:
þ
Buying patterns of customers;
associations among customer demographic characteristics; predictions on which
customers will respond to which mailings;
þ
Patterns of fraudulent credit
card usage; identities of “loyal” customers; credit card spending by
customer groups; predictions of customers who are likely to change their credit
card affiliation;
þ
Predictions on which customers
will buy new insurance policies; behavior patterns of risky customers;
expectations of fraudulent behavior;
|
|
|
Data
Warehousing is such a new field that it is difficult to estimate what new
developments are likely to most affects it. Clearly, the development of parallel
DB servers with improved query engines is likely to be one of the most
important. Parallel servers will make it possible to access huge databases in
much less time.
Another
new technology in data warehouses that allow for the mixing of traditional
numbers, text and multi-media. The availability of improved tools for data
visualization (business intelligence) will allow user to see things that could
never be seen before.
|
|
|
|
|
|
þ
www.datawarehousingonline.com
þ
www.datawarehousing.ittoolbox.com
þ
Olap solutions: Building Multidimensional
Information Systems, Eric Thomson, John Wiley.
þ
Planning and Designing the Data Warehouse,
Roman Barquin and Herb Edelstein.
