
The pre-OO thinking was that a system should be a series of black boxes with clearly defined inputs and outputs ("wires"). These wires carried relatively simple signals between the various black boxes of the system. The complexity was in the black boxes, not in the wires.
However, OO thinking tends to complicate the wires. In fact in OO the wires themselves tend to become black boxes. In pre-OO thinking the wires were usually simple data like numbers, strings, and occasionally arrays and tables (or handles/pointers to them).
In OO the inputs and outputs are often complex OO classes which often have complex behavior attached to them. Thus, the wires in OO are actually no different from black boxes themselves.
But why is a bunch of tightly interconnected boxes bad? Mostly because it is tougher to comprehend each black box in isolation. A given black box will often depend on the behavior of one or more of it's inputs and outputs (parameters) in OO thinking.
For example, take a typical Java statement:
data = new DataInputStream(new BufferedInputStream(astream));
You are feeding behavior (classes) in as parameters here. "BufferedInputStream" and "astream" are tied to OO classes with behavior attached to them. You are passing the equivalent of a black box into another black box here.
Thus, to know what DataInputStream does in this case, you may have to know what BufferedInputStream does. And to know what BufferedInputStream does, you have to know what InputStream does (class of "astream").
(Note that although Java has shortcuts in some cases, feeding behavior in as parameters is still common practice.)
In many cases you can simply copy the pattern without having to understand all the classes involved. However, if you need something outside the same pattern, you will probably have to understand each input class in fair detail.
To really know how something is going to act, you often have to know how all the inputs and outputs act together. When you pass behaviors instead of just data as parameters, you are essentially making the black box bigger and more complicated because you are losing the "unit of independent comprehension" that you had in the old model.
Although OOP's version of black boxes may still be black to the user of them (programmer), they are essentially gray boxes to *other* boxes, and thus the programmer is forced to consider the *combined* behavior.
You may have to even follow a long chain of classes to sufficiently understand the original module or method. It is perhaps possible that you may have to understand an entire OO system just to fully comprehend the behavior (or results) of a single piece of code. OO may give the illusion of simple, independent pieces; but is actually building one or a few very large, complicated black boxes instead.
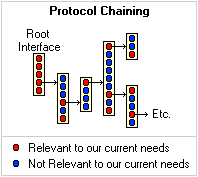
It strongly reminds me of going to just about any government office to get something done. One form leads to another form (or visit), which leads to another. They may only need a small piece of information from any given form, but the form is their official way to obtain such.
There is more to simplicity than simply hiding the implementation from the component or class user. Just because a protocol hides the implementation does not mean that one is off the hook from keeping things understandable and interchangeable as individual units. Protocol coupling can be just as bad as all the other "coupling sins" of software engineering. One can "couple" (tie) things together by forcing them to share common data and/or making them dependant on implementation details, but things can also be coupled by making them dependant on a particular protocol(s) {class(es)}.
I came to this tentative conclusion while building examples to prove to others that P/R (procedural/relational paradigm) can factor just as well as OOP in order to make generic or type-independent modules. However, in order to do this I had to pass behavior (in the form of code blocks or expressions) as parameters in the P/R version.
At first an OO fan complained that this was silly and confusing. After pondering their comments for a while, I concluded that the OOP version was doing almost the exact same thing. The only difference is that such a practice is more integrated into OOP languages. (That is the main reason for more built-in protection in many OOP languages.)
Passing behavior as parameters is admittedly a powerful concept. It is tough to make highly generic modules without it. However, it does create dependencies between the passer and passee that can be hard to comprehend as single interacting units. (Inheritance can create a similar comprehension dependency chain because one may have to comprehend many or all of a class's ancestors in order to get a decent feel for a single class.)
In my opinion, it is a concept that should be used with care. However, many languages and OOP fans have gotten carried away with the idea. As a rule of thumb, only use it when the "skinny wire" approach does not work. Don't use it simply because it is in style or because some book told you it was good.
Coupling Needed for Reuse?
Some OOP proponents suggest that protocol coupling
is a key to OO
reuse.
It allows one protocol to "reuse"
another, the claim goes. Does this mean that reuse
and understandability are in conflict?
The real issue is exposing the guts
to the component/protocol user. A component/protocol
does not necessarily have to force the
user to choose or see what other parts/protocols
it uses to get its job done. You don't have
to expose reuse in order to have reuse.
One useful technique is to give the component user the optional choice of picking another sub-part if needed; however, have a default in place.
foo(a, b, c) // use default driverX
Versus
foo(a, b, c, driverX=bar) // select alternative
Here an optional parameter (a "named parameter") is
used to "tuck away" the choice of driverX. A
well-chosen default is used if not explicitly selected.
(This is essentially a
Strategy Pattern, but
with a default strategy. In an OOP version, one would
override the parent's strategy only if needed.)
We don't have to overwhelm the component user with
all the possible choices. One should not "expose
the internal bureaucracy", except as lower-level
options for "power users".
Types of 'Wires'
Based on our above discussion of
"wire types" in black boxes, here is a list of
possible individual parameter types in
rough order of increasing complexity:
A file handle is just a memory or slot address that only has meaning during the time a given program process is active. On the other hand, a file name can be used by different processes between runs. Thus, it makes a more flexible and interchangeable "wire" than a handle.
Passing data collection/tables is easier to understand
than passing behaviors, at least in my opinion. This is
because you can quickly look at the data or the structure
layout and know what you are passing. It is just
easier to "grok" structured data than algorithms
in most cases, even if only the protocol is visible. (See also
control panel analogy.)
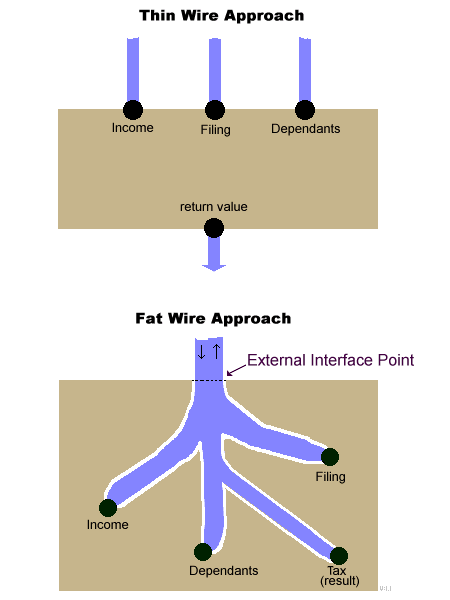
A Closer Look at Fat Wires
There are at least two problems with fat wires:
For the tying criticism, let's look at a simplified tax example:
//---- Fat Wire Approach ----
module taxPerson_A( aperson: personClass)
declare taxable: decimal
taxable = aperson.income
if aperson.filing = "w2"
taxable = taxable * 0.8
else
taxable = taxable * 0.9
end if
taxable = taxable - (2000 * aperson.dependants)
aperson.tax = taxable
end module
//------- Thin Wire Approach --------
module taxPerson_B(income: decimal, _
filing: string, _
dependants: int)
// income: gross income
// filing: filing status, "w2" or "1099"
// dependants: number of dependants
declare taxable: decimal
taxable = income
if filing = "w2"
taxable = taxable * 0.8
else
taxable = taxable * 0.9
end if
taxable = taxable - (2000 * dependants)
return taxable
end module
In the first approach, we pass an object of type personClass. (The names
are only illustrative, and not meant to demonstrate good nomenclature.)
The taxPerson_A module presumes that the passed object will have
certain interfaces. In this case these interfaces include "income", "filing",
and "dependants". (In some OO languages, responding to these protocol
names is sufficient. In others, the inheritance tree is checked to make sure
the passed object is of the proper pedigree.)
If personClass is changed such that "income" is removed and replaced with "netIncome" (because gross can be calculated rather than explicitly stored), then module taxPerson_A will not work without modification. However, taxPerson_B will continue to work without internal modification. (Perhaps some of the calls to taxPersion_B may need to be altered, but no changes are needed to the module itself.)
taxPerson_B can also be reused in a different application with more ease. If we copied/moved taxPerson_A, we would have to re-create personClass on the new system also. This may not be desirable. For example, the new system may already have it's version of personClass that has different names mapped in different ways. For example, the new system may store/reference the filing type in a completely different class.
Thus, the fat wire approach has coupled two modules together in ways that the skinny wire approach has not.
In the above example, "personClass" is fairly easy to understand and comprehend conceptually. It represents a "person." However, real world classes or structures are not always that direct.
For example, I was once trying to scale JPEG images in Java for catalog thumbnails. The API's I found to do this needed a MediaObserver object. I then had to go digging to find out how to create and satisfy a MediaObserver object. A skinny-wire approach would look more like:
if getURL(urlPath, tempfile, timeoutSeconds) then
scaleImg(tempfile, resultfile, width, _
height, true, "jpg")
else
errorMsg("could not get it")
end if
The "true" parameter tells it to keep the same image aspect ratio. Thus, the height and width are the upper bounds in size. Function getURL copies the contents at the given URL path to a file. Function scaleImg then reads that file and generates a new file with the scaled image.This approach uses nothing but base types of strings and numbers. (file and URL paths are strings.) The interface of getURL and scaleImage are quite easy to understand by themselves. One does not have to "satisfy" and learn other complex or obtuse classes in order to perform the needed task.
Thin wire interfaces tend to ask for "what is needed and only what is needed to get the job done". The entire personClass is not needed to calculate tax. The fat wire approach drags with it more than what is minimally needed.
I agree that classes like MediaObserver may have some powerful features in some cases, but at the expense of losing plug-and-play understandability and reuse at the module level. Java's API's have a certain "culture" that once one gets the hang of after perhaps years of use, start to provide powerful and flexible ways to do things.
But, this power is not free. Like I said elsewhere, it boils down to nothing more than the age-old tradeoff of integration versus independence. There are benefits and drawbacks to both low and high protocol coupling. Taking advantage of high protocol coupling often requires a system-wide familiarity, or at least a familiarity of several components. Thus, it may require more training and lower employee turnover, for example (assuming there are many custom Classes being used).
Note that OOP is not the only way to get fat wires. For example, the Java MediaObserver class allows one to get progress information about data transfers, such as to display a percent progress bar. Our GetUrl function could allow the same by having a callback routine as one of it's parameters. (Such a parameter would probably be a function name {as string} in a scripting language, or a function pointer {yuck!} in C.) There are some additional approaches to implementing the Observer pattern in non-OO languages. One is to include a stub routine that can be left empty or filled with custom behavior. For example, the ScaleImage() routine could come with an ObserveScaleImage() stub. You either fill it in or leave as is. This is less flexible than passing a routine name, but simpler. It may also depend on if the language supports module-scope routines or not.Also note that this article focuses mostly on "external" protocol coupling, as apposed to internal protocol coupling. Internal protocol coupling hides the routine or method calls inside of the unit. Since both paradigms rely on this roughly equally, internal coupling is not discussed. The stub method (above) perhaps could be considered internal coupling. But, this is debatable because the user of the unit must know about it to use it.
I once asked a Smalltalk programmer why there were so many Set and Get methods in a sample RDBMS connectivity example. The reply was that he was creating an interface to a database entity, so that the programmer did not have to deal with the "raw" table and SQL data.
I thought it odd that he used the word "raw." An SQL/RDBMS interface is already an interface. Thus, he was essentially creating an interface to an interface. In other words, doubling up. There is something wrong here.
I am not against abstraction layers, per se; but each layer should contribute something significant to the process. His approach was mostly converting one paradigm into another, not providing any real, additional abstraction benefit or detail hiding.
Most SQL database systems are anything but "raw." They have "views" to present simplified or cleaned up versions of tables, including abstract (artificial) tables derived from multiple other tables or special queries. RDBMS also provide many forms of protection via referential integrity rules, triggers, stored procedures, and so on.
I agree that there are some rough spots with RDBMS and SQL. But at least it is partially standardized and can share the same data with multiple paradigms and languages without having to re-create the abstractions and protection mentioned for each language. If there are problems with SQL and RDBMS, then deal with them in the open rather than tossing it all out and replacing or re-creating it in your favorite paradigm.
Let's not get interface-happy without looking around first. Deal?
Frankly, I have not found the direct field access approach of most procedural/relational (p/r) programming to be a large, or even medium problem in this regard. Having to change a field into a function for a bunch of field references is not a common operation in my experience. I admittedly cannot explain exactly why, but I will share some observations that may help explain the pattern.
First, calculations tend to be all-or-nothing in nature. Either you perform a lot of lookups, calculations, and cross-references, or you simply read from fields. The calculations tend to be "entity related". For example, one might have a calc_invoice() routine for a billing system or an update_bid() routine for an auction item in an auction system. Both of these may be rather involved operations, so one does not want to execute them for every read operation.
For example, the update_bid routine may have to look at all competing bids to see which is the highest. Doing this for say every read of an individual's bid status could get expensive. It might even trigger an endless update loop where reading bidder A's record triggers a re-calculation of the highest bid. This would entail reading bidder B's record, which would again require reading bidder A's record. This is because B's status depends on A's status, and visa verse. (A and B are both bidders for the same given item in this example.) I am sure there are ways to fix such recursive escalations in OOP, but such calculations cannot be taken lightly regardless.
Second, one still has control over when a recalculation is needed in p/r. In our auction example, a routine that displays a given bidder's status can perform an update_bid call just before displaying a given bidder's status if needed and only if needed. If you make the update automatic based on OOP set/get methods, then you may have less control over when and how often a calculation happens. What if the set/get calculation grows too expensive because a virtual attribute is referenced more often than you anticipated? Sure, there are OO solutions, but they are not always simple. The p/r approach is simple: call the Update routine if needed, else just read the fields. (True, it puts more burden on the programmer to keep things fresh, but well worth the tradeoff in my opinion.) In other words, the famed "information hiding" of OO may hide the fact that a calculation is expensive.
Third, one can build a subroutine to calculate needed information if it is known in advance that a raw field by itself is not sufficient.
Further, many RDBMS allow "views", "triggers", and/or "calculated fields", which can create virtual fields and/or update existing fields. These kind of overlap with the functionality of set/gets. (See "Double Dipping" above). In practice, the need for these does not seem that common for the reasons already given.
However, the usage frequency often depend on the design philosophy of the developer(s). Although my designs tend not to use a lot of triggers and so forth, other developers may make heavy use of them. Such designs tend to make some tasks easier and other tasks harder, in my opinion. It may be mostly subjective. There are multiple legitimate ways to skin a cat, and the final choice may simply depend on which tools and styles a developer is more comfortable with either by prior experience an/or "brain configuration".Further, the set/gets can result in bloated and cluttered code. Having such mindless, repetitious echoing of set/get references can hide the real business logic. In other words, it hides the code that actually does something meaningful and/or different. It is easier to find the needle if the haystack is smaller or non-existent.One problem with many existing RDBMS is that they don't give much language choice for writing triggers and stored procedures. This now seems to be changing, although unfortunately, Java is at the top of their list.
Also note that it is possible to have procedural languages that can "trigger" actions upon reads or writes to variables. Interactive debuggers, for example, can be told to stop upon value changes and/or references. Sometimes the user can change the value at such points. It is only a little extrapolation to implement similar features in the language syntax itself. Whether it is a good idea or not is another issue. One can envision potential "spaghetti triggers" where seemingly simple variable reads and writes trigger all kinds of unexpected behavior. OOP set/gets may also be susceptible to such under the knife of sloppy OOP programmers.
This "swappable implementation" claim of OOP seems to be yet another sound-good-on-paper claim of OO that does not really hold up in real applications.
The OO philosophy is that OOP classes place an interface or wrapper around data that is "housed" within the class. "Within the class" is the key. Data is usually housed within a paradigm-neutral, or at least a language-neutral repository (DB) regardless of paradigm (for biz apps). Although an OOP language can restrict access to classes, it usually cannot restrict access to the data store itself (using the same OOP mechanisms).
class X
// map class to DB entity (not all langs support this)
DBmapping map = DBmapping("entityA", sysStuff)
[interface to entityA]
end class
....
class Y
DBmapping map = DBmapping("entityA", sysStuff)
....
method Clobber()
map.deleteEntity
end method
end class
Here, a programmer may think that class X is
the proper or official interface to entity A.
When in fact, class Y also can access, and
clobber, entity A.
Ignoring this issue, the access/protection philosophy of both paradigms is very different. OO tends to have an "additive" approach, while relational tends to have a "subtractive" approach. Relational tends to by default allow access to all kinds of features to entities. If you don't want someone or something to have access to a feature (and/or errors if they try), then you manually add the restrictions via ACL's (access control lists), triggers, referential integrity, etc. ACL's are superior to nested-based protection because sets are more general-purpose in scope. (But, they are in turn more complex.)
I liken relational to giving the user (code or person) a mansion to start out. If you don't want them fiddling in certain rooms, you lock doors to specific rooms or put guards to sections of the mansion.
In OOP, on the other hand, you tend to start out with nothing, but add rooms (build or install) as needed. I wont say that one approach is better than another for every circumstance. However, in my opinion the relational approach is better at rapid application development because you have all the relational features instantly at your disposal. You don't have to build them, or at least install them one at a time. It is easier to lock a door than to build one.
This view of relational features allowing "easy access" to a wide array of features and arrangements is a common theme of my writing. You can also see it in my view of GOF patterns. I view such patterns as little more than transient views created by a few lines of relational algebra or Boolean expressions, and not something that need be built up in physical code brick-by-brick. It is "formulaic programming" as opposed to "structure-based programming" of typical OO designs. (Not to be confused with "structured programming".)Further, there are other ways besides OOP to make data users (such as application and report developers) have to go through an API-like interface, which is more or less what OOP methods give you. Stored procedures are one approach. (Direct access to the base tables might require a password not given to the app developers.) Thus, this is not really an OO versus non-OO issue, but an issue of whether to tightly wrap data or not. Procedural/relational can give you both approaches as needed.
The advantage of stored procedures over many OO approaches is that they can be relatively easily referenced by multiple languages and paradigms. Perhaps OODBMS could offer something similar, but in concept they would probably resemble stored procedures (maybe called "stored methods"?). One complaint about stored procedures is that they allegedly limit which language you can make them in. This, however, is a generally vendor-specific problem and not a born-in paradigm problem.
Related to the above, OO fans often say that "encapsulation hides and packages the details" of the guts of an entity (noun). One of the biggest faults of this in practice is that one interface does NOT fit all. Different operations have different "pre- conditioning" needs. Thus, you either have to guess the correct interface needs up front, add new interface or variations of interfaces all the time, or spend a lot of time re-arranging code (a.k.a. "refactoring" in Buzzword Land).
A typical p/r approach is to have a liaison layer that buffers any entity changes from tasks. (Tasks are the primary grouping arrangement for p/r code.) A liaison layer is often in the form of an SQL statement that joins and relates the various entities into a "flat" namespace. Result fields can even be re-named. The rest of the task does not have to know or care where these values came from. The liaison layer hides these details from the using code.
It is true that any given entity change may require changes to the liaison layers in many tasks, but this is true of any change in interface. OO may talk about protecting the outside world from changes in implementation, but offers nothing built-in to protect from interface changes, such as schema or noun object changes. (Subroutines can also hide the innards of implementation, by the way.)
It is often claimed by OOP fans that OO makes the software easier and safer to maintain. This is certainly unproven. Further, it often turns out that the chosen OOP abstractions do not fit the future changes very well, and that a less "tied" solution would be more flexible at adapting to how the changes actually are turning out.
All OOP classes and abstractions make certain assumptions about where future changes, maintenance, and growth will likely happen.
Some get lucky (perhaps by trial and error) and make abstractions that fit well with the future.
However, if you are too far off, then OOP's abstractions are often worse than procedural approaches because OOP abstractions are usually bound tighter together. Something that is bound tightly is harder to pull apart and rewire.
Perhaps the bottom-line tradeoff is this:
If you guess right, then OOP abstractions produce a better system than what procedural programming would. (These are the ones people use for showcase projects.) But, if you guess wrong, then OOP abstractions produce worse systems.
Inheritance is probably the best example of this. If the future grows along your inheritance tree, then you are fat and happy. However, if the future grows in a nonhierarchical way, or in a way that does not match your particular hierarchy very well, then you end up with a bigger mess than if you had picked a flatter or graph-like approach to begin with.
OOP fans tend to focus on the ideal, and in hindsight often imagine what would happen if they picked the right horse after things go wrong. This makes OOP seem like the correct path if "one just knows how to plan properly." It is a scaled-down version of gambling addiction: "If I just had done it a little different, I would be rich." It is the continuing feeling that you are just one little step away from the jackpot.
It is in essence a psychological addiction to idealism. OO does not necessarily reach this idealism, it just magnifies the rewards and punishments of playing with idealism.
The reality is that planning for and predicting the future is tough; and that in reality one will be wrong more often than one hopes.
Procedural: v(h, p) or verb(handle, parameters) OOP: h.v(p) or handle.verb(parameters)Instead of "handles", OOP calls them "objects".
There are some differences, however. For one, OOP makes it easier to polymorph the verb. If by chance the same package needs the same verb, then one can use "soft" verbs:
package("verbname", handle, parameters)
This is a little more verbiage than the OO method, but I have not
seen a use for such that often.
If different packages need to use the same name under the earlier setup, then either some sort of package resolution can be used, or a simple convention like this:
package_verb(handle, parameter)This, again is a little more wordy than the OOP approach because the "package" is part of the handle type in OO. However, if it is used often, then you can simply make a new function with a shorter name that references the same one. (Some languages have function alias abilities.)
If one uses table fields or dictionary (associative) arrays to store attributes, then referencing most attributes does not require an explicit routine call. The table/query-set handle or array can be a local name, very similar to object instance naming. Thus, you may only need to reference a function name for specific actions. A common pattern of component usage is a series of attribute assignments (setup) followed by a final action. In database API's, the action often comes first. Either way, I find that the ratio of attribute/field setting/reading to action statements is roughly 6-to-1. Thus, the action statements (procedure calls) are not a major source of bloat if by chance they do turn out to be longer.
// Phone Number Parse Example (pseudo-code)
var ph[] // declare associative array
ph.text = "(123) 456 - 7890 x1234 ask for Sandi"
ph.country = "USA"
parsePhone(ph) // action
if ph.status == "ok"
println ph.areacode // result: 123
println ph.middle // result: 456
println ph.suffix // result: 7890
else
println "** Bad Phone Number"
end if
// Now for another country
ph.text = "12-43422-12341-123"
ph.country = "Tablonia" // hypothetical country
parsePhone(ph)
println ph.raznic // result: 12
println ph.fisbin // result: 34422
etc...
Associative arrays (dictionary arrays)
that use dot syntax can provide many
of the features that made "dot syntax components" popular.
If one can dynamically execute program code or function
pointers/references stored in associative
arrays, one can even get very method-like behavior.
However, I find the above approach usually
sufficient.
One problem in many OOP languages when using DB components is that there is no way to separate field names from actions or settings without introducing code bloat. For example, you may potentially have a field named "moveNext", which may conflict with the "moveNext" method. (This is not common, but still must be dealt with syntactically.) One poor solution often used to prevent such naming conflicts is to have an intermediate "field" object: "x.field.moveNext" or "x.field('moveNext')", but this creates code bloat because fields are frequently referenced in business applications. It doesn't make sense to keep stating "field" over and over again. Common patterns like that should be factored out and/or simplified. Using functions in conjunction with associative arrays (or anything else with the dot syntax) seems to reduce this problem. Fans of manually-written set/get methods would have an easy solution to this issue, but create their own brand of bloat in exchange. Microsoft solved this in some VB dialects by using "!" for fields and "." for commands, although I think it should be the other way around. Some approaches, such as PHP API's, use one dictionary array for the record-set handle, and another separate dictionary for iterating/grabbing the records (field set). Although it avoids name clashes, I am less fond of this approach.Sometimes named parameters allow one to combine the attributes and actions into one (big) call. If there are many attributes, this approach can grow a bit messy.
There is sometimes less built-in type protection with these approaches. Type protection is nice, but it is rarely without costs.
I will take the simplicity of the procedural approach over the complexity of OO if I have to sacrifice a few keystrokes. Saving a few keystrokes is no reason to bloat up a language with a second paradigm. OOP languages like Java toss out the whole idea of saving keystrokes anyhow due to period escalation ("foo.bar.thingaMajig(yagoo.maDaggo.calamaZoo)"), excessive use of inheritance, etc.
One problem with such multi-dot syntax is that it hard-wires the hierarchy into the references. If you later change the hierarchy, then you may have a lot of references to change. It is similar to hard-wiring file directory pathnames into scripts; if you move the directory, you have to alter many of the paths. (You can say I more or less agree with the Law of Demeter with regard to long paths.)
To be fair, one can often extract a shortcut reference in OOP, but this is often not done, or requires a lot of backtracking to figure out where the reference came from and/or what the heck it is. OOP often makes it hard just to find out what something is. In p/r, there are usually more clues per call.
For example, you may have "move_screen(x)" instead of "x.move". Some consider this bloat, but I consider it self-documentation. Neither "x" nor "screen" tells you what the fudge is being moved. It could be the furniture for all we know.
If you really want "reuse", then reuse what the database
(or collection engine) already does well. Hiding
(encapsulating) access to data tends to increase this
nasty OO practice of re-inventing collection interfaces.
OO fans seem to be so caught up in "factoring" duplicate
implementation that they forgot to also factor (consolidate)
duplicate interface features. Then they go bragging
about how polymorphism allows sharing the same verbs, the
collection operations, with different things. In other words,
first they make an OO mess, then brag about how great polymorphism
is at cleaning up that mess. Polymorphism or not, the
interface is larger than need be.
I would agree that components are probably one of the few places where OOP may help in some cases. However, it's benefits are marginal and mostly related to syntax and name-space issues, which may be language-specific anyhow. I still do not think the difference is worth the extra syntax and confusion of OOP, but understand why some would prefer the OOP approach, especially if they are not familiar with techniques such as using associative arrays as interface mechanisms and/or the language does not support them. The more important issues of the debate relate to business modeling and collection management, not components (although they sometimes overlap).
Apparently, the ADA language offers an interesting hybrid between function-based syntax and OO-like syntax. A study of ADA may be recommended if one is more interested in these syntax issues.
Note that some procedural languages allow variables to be defined within blocks, so variable scope is not a legitimate criticism of the paradigm:
if x = "7"
var y = 3 // defined scope within block
blah()
blah()
endIf
OR
if x = "7"
var y // defined scope within block
y = 3
blah()
blah()
endIf
Let's compare the two blocking approaches
between the paradigms:
// PROCEDURAL
if group = "Lisa"
if stage = "pre"
stuff...
endIf
if stage = "post"
stuff...
endIf
if stage = "final"
stuff...
endIF
endIF
// OBJECT ORIENTED PROGRAMMING
class Lisa
method pre
stuff...
endMethod
method post
stuff...
endMethod
method final
stuff...
endMethod
endClass
Frankly, I don't see much difference. It is true
that the compiler can provide forms of
protection
from malformed statements or associations, but many OO fans
have insisted to me that protection is not the
primary goal of OO. There may also be tradeoffs
with such formality (see below).
Further, IFfing provides more flexible variations. One is not locked into class-method template of typical OO classes. For example:
if (group="Lisa" or group="Martha) and stage="final"
stuff...
endIf
Sure, the OO approach can do this by putting a method
in the parent class, but the advantage of the procedural
approach is that it is generally more natural and easier
to combine more than
two factors (not just class and method) to create
and arrange blocks. Having 3, 4, or more
aspects
determining significant blocks is not that uncommon.
What is so magical about OO's limit of two?
One can also easily change (invert) the proximity nesting:
if stage="pre"
if group="Lisa"
stuff...
endIf
if group="Martha"
stuff...
endIf
endIf
if stage="post"
if group="Lisa"
stuff...
endIf
if group="Martha"
stuff...
endIf
endIf
etc...
Here the stage (method) has be moved to the outside
and the "group" (class) to the inside. (It is true that
some obscure OO languages do not require physical
nesting of methods within class.)
I do not understand the OO bias against procedural blocks. A block is a block. If you can articulate this distaste, please let me know. Prior attempts to coax clear explanations from OO fans has failed to turn up anything specific, or resulted in language-specific complaints like the annoying "break" statement from the C clan.
However, in practice this tends to assume that the large subtype model is practical. I find that it isn't (in custom business apps). The distinction between what a "variation" is can blur and morph. For example, an IF block may be client-specific one day, but be changed to a standard toggled feature the next. Or, it may have multiple criteria, and variation membership may be one of many (ex: "AND" and "OR" statements). It is back to the famed "has-a" viewpoint versus the "is-a" viewpoint battle again.
I agree that block association formality may make machine-processing of code easier, but risks certain inflexibility and adaptability limits without excessive code overhauls. It is roughly similar to how more machine analysis can be done on Non-Turing-Complete (limited) languages. This is a complex issue that could use some heavy-duty thinking from experts in the field. It also relates to the static-binding versus the dynamic binding ("scriptish") battle fought even among OOP fans. Thus, it is even important beyond my anti-OO crusade.
Also note that the OO view seems to be resulting in an increased reliance on IDE's and code processing tools. Whether this is good or bad gets into some complex issues. I have kicked around ideas for making or using existing table viewers as kinds of IDE's and code managers. Regardless, reading a code printout over a glass of lemonade in the backyard may be a thing of the past.
Even if a fancy IDE can rearrange an entire large application at the push of a button (for the sake of argument), it may confuse the heck out of maintenance developers. One day an application gets Contact information via interface inheritance, and the next day it gets it from delegation or a Role pattern? Spooky. (One OO fan actually proposed this.)
Organizational benefits are features that allegedly help organize software better so that it can be maintained and managed easier. However, OOP simply tends to favor one organizational grouping at the expense of another, rather than provide better grouping than procedural programming or other paradigms. (We have already seen how dubious inheritance, another organizational concept, can be.)
Protection benefits are similar to "strong typing". Strong typing is where a variable or object cannot be used with an operation that is not meant or not defined to handle that particular type. It is meant to protect the programmer or process from accidental misapplication of variables and/or objects to the wrong process, property, or assignment.
There are various pros and cons to strong typing. The pros are better compiler or interpreter detection or prevention of certain types of programmer mistakes, and the cons are that more "setup" information needs to be supplied and more conversion or translation between types is often needed. (This article at Scriptics Corporation suggests that weak typing results in much faster software development cycles.)
Further, as more systems are hooked together in various ways across vast distances and with different server and software brands, the ability to check interfaces and data services at compile-time is reduced. Thus, the value of compile-time checking may be diminishing in many domains. The world is becoming one, big interpreter.
Regardless of whether strong or weak typing is actually better, OOP appears to buck the general trend toward weaker typing in languages used for custom business applications, smaller scale projects, and rapid development projects. (Strong typing is perhaps preferred for mass-market tools, OS building, and medical applications.)
Note that OOP does not necessarily have to be strongly typed (look at Smalltalk), but a weakly typed OO language loses its claim to object/method mismatch protection. In which case, one is left with only the flimsy organizational benefit claims.
Some believe that anything that uses the "dot" syntax is OO. However, some table-oriented syntax also uses dot syntax. Further, the dot syntax can often be rewritten as functional syntax (see above under Component Syntax).
For the sake of these documents, using OOP will be defined as writing classes and methods which have more than one instance. Single instances are excluded because they are too similar to function calls in a "package scope" environment along with C-like "static" variables. (Package scope allows variables to have a scope other than either global or routine-internal).
Note that I am excluding using classes written by others. This is because in my opinion, the writing of components and/or frameworks is a very different mindset, target audience, and niche than using them for the most part. (At least in small and medium projects.) See Criticism of Meyer's OOSC2 for more on this.
As far as an object oriented "philosophy" is concerned, there seem to be two overriding or reoccurring themes in OO literature:
1. Grouping behavior or services around nouns/entities
2. Dispatching behavior based on taxonomies/divisions/subtypes
Although there are often competing or conflicting definitions of OO philosophy out there, these two themes appear to be the most common thread in my opinion. I tend to find multiple difficulties with excess use of both of these approaches in custom business application design, as described by these articles.
The first one lacks good descriptions or documents on how to design flexible business applications around this (to be better than procedural/relational's task-oriented grouping and virtual aspect views), and the second one tends to have granularity problems in that the patterns of real-world changes are often at a finer granularity than these divisions/subtypes can handle. This includes the problem of competing (orthogonal) division criteria. (I am kicking around the idea of adding Protocol Coupling to the list.)
Note that procedural/relational designing does not dismiss nouns, it only is less likely to use programming code to manage nouns and noun relationships. The structure of the code units does not reflect the noun structure in the models, you can say. Relational modeling and relational formulas are the primary depository of noun-related information in p/r. For example, p/r tends to represent GOF patterns via relational formulas, and not physical code unit structuring.