 Statistics 101 - Part 2
Statistics 101 - Part 2
Statistics 101 - Part 2
Below is a list of topics that I will cover in this review:
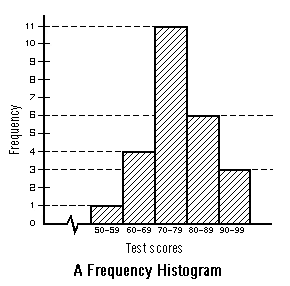
When we deal with large sets of data, a good overall picture and all the information we need can often be conveyed by grouping the data into a number of classes, intervals, or categories. For instance, suppose that a class of 25 students received the following scores on a final exam for a math class,
57, 71, 63, 67, 66, 72, 93, 71, 75, 72, 73, 77, 71, 70, 83, 92, 79, 85, 80, 84, 83, 85, 95, 62, 70, we can summarize them as:
| Interval | Tally | Frequency |
| 50 - 59 | / | 1 |
| 60 - 69 | //// | 4 |
| 70 - 79 | ///// ///// / | 11 |
| 80 - 89 | ///// / | 6 |
| 90 - 99 | /// | 3 |
The construction of a frequency distribution consists of three major steps:
This is the frequency histogram for the final exam scores we obtained previously when we discussed frequency distribution:
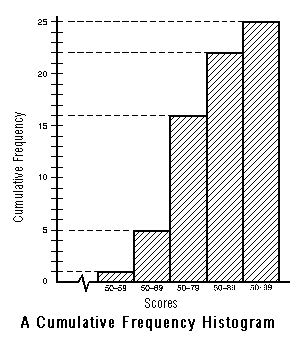
| Old Interval | Old Frequency | New Interval | Cumulative Frequency |
| 50 - 59 | 1 | 50 - 59 | 1 |
| 60 - 69 | 4 | 50 - 69 | 5 |
| 70 - 79 | 11 | 50 - 79 | 16 |
| 80 - 89 | 6 | 50 - 89 | 22 |
| 90 - 99 | 3 | 50 - 99 | 25 |
Cumulative Frequency Histograms
Cumulative frequency histograms are constructed by using the same method as we used for constructing frequency histograms, with the exception that we now add more data to each successive class/interval. In other words, we should be seeing a histogram in which the frequency is increasing.
This is the cumulative frequency histogram for the final exam scores we obtained previously when we discussed frequency distribution:
This is why we need to study measures of dispersion, which indicate whether the data are spread out or are clustered together. Some examples of measures of dispersion include: range, standard deviation, and variance.
The standard deviation is the most widely used measure of dispersion. It is defined as the square root of the variance, which is the mean of the squares of the deviation from the mean. In other words, the standard deviation is the measure of how the average deviates from the mean.
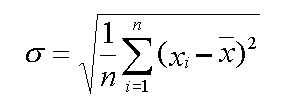
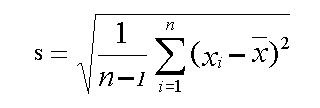
The variance of a set of numbers is the average of the squares of the deviation from the mean. Another way of looking at variance is to think of it as the square of the standard deviation.
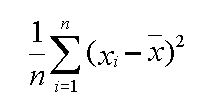
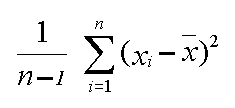
By squaring each deviation from the mean, the variance formula prevents the mean deviation from summing to zero. The squaring process, however, tends to exaggerate the size of the variance in comparison to the values of the individual data items it is describing. The standard deviation (since it is the square root of variance) attempts to correct this weakness of variance.
Sometimes, the data that you collect might be dispersed in such a way that resemble a bell-shaped curve. We usually call such a curve, the normal curve.
If you know that a set of data is distributed like a normal curve, you can draw conclusions about how far the data are from the mean.
A normal curve is symmetric with respect to the vertical line x = x bar, or the mean. If a set of data values, such as the scores on a test, fits a normal curve, then the numbers of these data values that fall within one, two, and three standard deviations of the mean can be predicted, as shown in the following diagram:
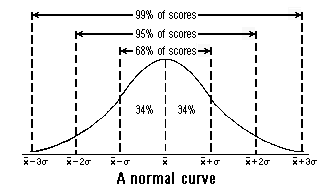
When a large number of data points closely approximate the bell shape of a normal curve, the data are said to be approximately normally distributed. When data are normally distributed, the following relationship can be used to draw conclusions concerning the approximate numbers of data scores that are within one, two, and three standard deviations from the mean:
| Interval | Interval Length | Contains... |
| mean +/- one standard deviation | 2 standard deviations | 68% of all scores |
| mean +/- two standard deviations | 4 standard deviations | 95% of all scores |
| mean +/- three standard deviations | 6 standard deviations | 99% of all scores |
Since one standard deviation is 5, the requested interval is within two standard deviations of the mean. According to the table from above, approximately 95% of the test scores should fall between 65 and 85.
If 100 students took this test, then, 95% of them, or 95 of them would have scored between 65 and 85.
Click here to go back to Statistics 101 - Part 1
[ Home | Regents Review | Join Pen-Pal Network | E-mail me ]
© July 1998 by Danny Chan
