ana sayfa : araştırma : mpeg görüntü : mpeg kodlama prensipleri [ 3 / 9 ]
BÖLÜM 3
MPEG KODLAMA PRENSİPLERİ
Bu
bölümde MPEG kodlanmasında kullanılan basit prensipler gözden geçirilecektir.
Sistemlerin, modelleme ve dağınım (entropy)
kodlama kısımlarına nasıl bölümlendiği gösterilerek kodlama
sistemlerinin yüksek seviyeli görünüşleri temsil edilecektir. Ve bu
neticede dağınım kodlaması ve şifreleme modelleri konularında önemli
noktalar üzerinde durulacaktır. Son olarak da MPEG-1 kodlama tekniklerinin
spesifik özelliklerini ve MPEG-1 kodlayıcı ve kod çözücülerinin
temsili blok diyagramları anlatılacaktır. Son bir not olarak, bu bölümde
kullanılacak sistem terimi MPEG
'in sistem tabakası'ndaki sistem
ile ilişkisizdir.
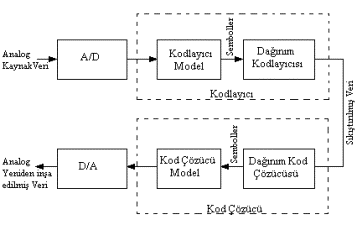
3.1. Kodlama Sistem Yapısı
Tipik
bir kodlayıcı ve kod çözücü sistem yapısının örneklemi şekil
3.1’de yüksek seviye kodlama sistem diyagramı şeklinde gösterilmiştir.
Burada analogtan dijitale çevirici (A/D) giriş verilerinin duyarlılığını
ve basit çözünürlüğünü belirler ve böylece orijinal sahneden yönetilebilir
seviyeye imkan dahilinde neredeyse sınırsız olan veriyi azaltmada önemli
bir nokta başarılır. Bununla birlikte veri indirgemesi dijitalleştirme işlemi
bitmeden durdurulması gerekmez.
Bir resim dijitalleştirildiğinde fazlaca indirgeme olmayan sıkıştırma
sistemleri kayıpsız (losslessly) sistemlerdir. Bu kayıpsız sıkıştırma
sistemleri nadiren doğal bir resim verisini iki veya üç kat sıkıştırabilir.
MPEG gibi sıkıştırma sistemlerinin ise bundan daha yüksek bir sıkıştırma
oranlarını başarmaya ihtiyacı vardır ve bu sistemler dijitalleştirme işleminden
sonra kayıplı veri indirgemesi ile bunu başarır.
Şekil 3.1 -
Bir Sıkıştırma Sisteminin Genel Yapısı
Şekil
3.1’deki gibi bir kodlama sistemini iki kısma bölmek uygun olur. Birinci
bölüm dijital kaynak veriyi konvensiyonel olarak sembollerle
isimlendirilen soyut temsile çevirerek kayıplı veri indirgemesi yapar. İkinci
bölüm ise bit akışının uzunluğunu istatistiksel bir yönde küçültecek
bir işlemle bu sembolleri kodlar. Bu ikinci basamağa dağınım
kodlaması (entropy coding) denir.
3.1.1
Modelin İzole Edilmesi
Şekil
3.1’de kod çözücü, kodlama işlemini mümkün olan en az uzantı ile
tersine çevirir. İlk olarak kayıpsız bir şekilde sıkıştırılmış
veriyi sembollere dönüştürür ve orijinal dijital kaynak verisine görsel
olarak en yakın olacak şekilde dijital resmi yeniden yapılandırır. Bu
dijital veri göstericiye, analog çıkış sinyalini yeniden oluşturmak için
dijitalden analoğa dönüştürücüye (D/A) beslenir.
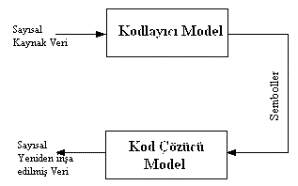
Şimdilik dağınım
kodlayıcısı ve kod çözücüsünü aşağıdaki özelliklerde siyah
kutular olarak düşünelim. Dağınım kodlayıcısı kodlayıcı modelden
akış sembollerini alır ve sıkıştırılmış veriye çevirir; dağınım
kod çözücüsü sıkıştırılmış veriyi deşifre eder ve kod çözücü
modele hemen hemen özdeş akış sembollerini gönderir. Dağınım kodlayıcı
ve kod çözücüleri kayıpsızdır. Bu sıkıştırma sistemi aşağıdaki
şekilde (şekil 3.2) kısaltılarak gösterilmiştir. Sistem çok sıkıştırma
sağlamamasına karşın diğer noktalara göre hala bayağı bir işlevseldir.
Şekil 3.2 -
Kayıpsız Sıkıştırma Bölümleri Kaldırılmış Sıkıştırma Sistemi
3.1.2
Semboller ve İstatistiksel Modelleme
Semboller
verilerin özet olarak temsilleridir. Genellikle orijinal kaynak verinin tam
tersinir olarak yeniden inşasına izin vermezler (Özellikle tersinir bir
şekilde dizayn edilmezse). Genel olarak, kodlama modeli veri indirgemesi ve
verilerin sembollerle yer değiştirmesi işlemlerinin her ikisini de
kapsamaktadır. Veriyi temsil etmek üzere seçilen semboller, verimli ve göreceli
basit dağınım kodlaması basamaklarına izin verecek şekilde az ilişkilendirilmiş
bir temsilleme sergilerler. Verileri temsil için sembol kümeleri seçme işlemi,
verilerin istatistiksel modellerini kapsar. Çünkü, bu işlem verinin
istatistiksel özellikleri üzerinde dikkatlice yapılan analize dayanır.
İstatistiksel
modelleme, kodlama modeli dizaynını da içerir. Örnek olarak; kayıpsız
kodlamada geniş ölçüde kullanılan bir kodlama tekniği türevsel
darbe kodu modülasyonu (Differential Pulse Coding Modülation-DPCM)
vardır. Bu kodlama tekniğinde her resim elemanı (pel) ve o anda iletilen
komşu resim elemanı değerlerinden bulunan kestirim arasındaki fark
hesaplanır. Resim elemanı farkları, orijinal resim elemanı değerleriyle
oldukça az ilişkilidir ve makul verim oranlarında bağımsız olarak
kodlanabilirler. Ancak, istatistiksel modellemede, farklar arası ilişkiler
(korelasyon) bir değere aktarılırsa kodlamada daha iyi bir veri elde
edilir.
İlişkileri
(korelasyon) indirgemede verimli yollardan birisi de DCT (ayrık kosinüs dönüşümü)'dir.
Fakat, DCT tabanlı modeller hakkında ayrıntılı bilgiye girmeden önce
dağınım kodlaması konusunda gelişmek gereklidir.
3.2 Dağınım Kodlaması (Entropy Codıng)
Bir
dağınım kodlayıcısı (entropy encoder), sembol dizisini kayıpsız
bir biçimde sıkıştırılmış veriye dönüştürür. Dağınım
kod çözücüsü (entropy decoder) ise kod çözücüden özdeş
dizinin geri üretilmesi için daha önce yapılan işlemi aynı şekilde
tersine çevirir. Dağınım kodlayıcısının görevi sembol dizilerini mümkün
olan en kısa bit akışı seviyesinde şifrelemektir.
3.2.1
Dağınım Kodlaması Prensipleri
Genelde
dağınım kodlayıcısına beslenen semboller bir alfabenin
üyeleridir. Tabi buradaki alfabe terimi biraz açıklama gerektirecektir.
Özel küçük harfler dizisinden oluşan bir metin dizisini sıkıştırma
işimiz olduğunu varsayalım. Eğer tüm harfler dizide bulunacak olduğu düşünülürse,
normal alfabede a'dan z'ye 29 tane harften oluşan bir sıkıştırma
alfabemiz olacaktır. Bununla beraber metin dizisinin hem büyük harfleri
hem de küçük harfleri içerdiği düşünülürse, o zaman sıkıştırma
alfabemiz 58 sembolden meydana gelecektir. Alfabede boşluk karakterlerine
izin verilirse bu karakterler diziye eklenmelidir. Eğer herhangi bir
noktalama işareti kullanılıyorsa bunlar da eklenmelidir. 8 bit kodlamayla
ifadelendirilebilen karakterlerin hepsini içeren bir alfabe olduğu düşünüldüğünde
sembol sayısı 256 olacaktır. 16 bit (1 kelime) kodlama için hesaplanırsa
65536 sembole ulaşılır. Bir başka deyişle, mesaj -dağınım kodlayıcısına
beslenen gerçek sembol akışları- birçok imkan dahilindeki akışlardan
biri iken alfabe olanaklı semboller kümesidir. Bu özel sembol akışlarını
mümkün olan en az bitle iletmek dağınım kodlayıcısının görevi
olmaktadır. Bu işlem her sembol için istatistiksel olarak optimum kod
uzunluğu gerektirir. Uygun tamsayı kodu atamaları için kullanılan tekniğe
Huffman Kodlaması tekniği denir.
Benzetme
yaparsak, dağınım kodlayıcıları oldukça akıllı kumarbazlar gibidir.
Geçerlilik bitlere bağlanır ve
kod çözücüsüne sembol akışlarını iletirken mümkün olan en az bit
kaybı olması amaçlanır. Kumar tahtasında bahislerin nasıl yer alacağı
gibi sembol ihtimalleri önemli bir rolü üstlenirler. Kazanmak için,
muhtemel semboller ortalamadan daha düşük bitlerle kodlanmalıdır.
Bunu gerçekleştirebilmenin tek yolu ise az muhtemelliğe sahip olan
sembolleri ortalamadan yüksek bitlerle kodlamaktır. Bu açıdan kumar
biraz uzamaktadır. Ama genellikle akıllı kumarbaz kazanır fakat hep düşük
ihtimallere sahip bir mesaj ortaya çıkarsa o zaman mesaj sıkıştırılacağı
yerde daha da genişletilir. Böyle durumlarda bahis kaybedilmiş olur.
3.2.2
Dağınım Kodlamasının Matematiği
Bilgi
kuramının temel teoremine dayalı olarak bir sembol için en uygun uzunluk
Ls şu formülle verilir;
![]()
Basitçe her sembol
için ortalama bit rakamı olarak ifade edilebilen dağınım ise;
formülüyle
gösterilir ve toplam alfabedeki tüm sembolleri verir. Dağınım sıkıştırılmış
bir mesaj içindeki ortalama kod uzunluğu üzerindeki küçük bir bağıntıdır.
Anlatılacak
olanlar bunun kanıtı değildir fakat olayın anlaşılması için yardımcı
olacaktır: alfabenin a,b,c ve d gibi 4 karakterden oluştuğunu düşünelim.
Sa, Sb, Sc ve Sd 'nin de sembol
sayıları olduğunu varsayalım. Her sembolle en az bir defa karşılaşılacağı
ve her birinin uzun bir mesaj içerdiğini kabul edelim. Şimdi a sembolünden
başlayarak sayıları şekil 3.3’de görüldüğü gibi sıralayıp bir yığın
oluşturalım.
 |
Şekil 3.3 - Bir Rakam Çizgisi Üzerindeki Sembol Sayıları
Her
bir sembol özel bir sayı aralığı ile birleştirilir. Böylece
belirtilen aralıktaki herhangi bir sayıyı seçerek açıkça
belirtilebilir. Mesela, a sembolü 0'dan Sa -1'e kadar olan aralıkla
belirtilir ve 0 ile 3 arasındaki herhangi bir sayıdan seçilebilir. b
sembolü ise Sa'dan Sa + Sb -1 'e kadar
olan aralıkla ilişkilendirilmiştir ve bundan dolayı 4 ve 5 rakamlarından
herhangi biri olarak seçilebilir. d sembolü Sa + Sb
+ Sc 'den Sa + Sb + Sc + Sd
-1 'e kadar olan aralıklarla ilişkilendirilir ve 8 ile 15 arasında
herhangi bir rakamdan seçilebilir. Dikkat edilmelidir ki bu aralıklarda hiç
üst üste binme olmamaktadır. Tablo 2.1’de ilk iki sütunda bu olay özetlenmiştir.
Tablo
3.1 - Tablo - Sembol Sayıları, Olasılıklar
ve Kodlar
|
Sembol |
Sayı Aralığı |
İkili Sayı Aralığı |
Kodu |
Olasılık |
Kod Uzunluğu |
|
A B C D |
0..3 4..5 6..7 8..15 |
0000..0011 0100..0101 0110..0111 1100..1111 |
00 010 011 1 |
1/4 1/8 1/8 1/2 |
2 3 3 1 |
Tablo
3.1’de 3. sütun sayıların ikili temsillerini içermektedir. Sd
, en geniş sayı aralığı olmakla birlikte sadece en değerli bit eşsizdir
ve diğer bitler ya 0 ya da bir olabilmektedir. Ondan sonra en küçük aralığı
olan Sa için iki en değerli bit 0 olmak zorundadır ve geri
kalan herhangi bir anlamda olabilir. İki küçük aralık için üç bit
gereklidir ki eşsiz olarak aralık belirlenebilsin. Eşsiz olmayan bitler görmezden
gelinirse 4. Sütundaki sonuç ortaya çıkar.
Eğer sembol olasılıkları sembol sayılarından
yararlanılarak hesaplanırsa, ideal kod uzunlukları yukarıdaki ikinci
formüle göre hesaplanabilir. Bu durum zaten Tablo 2.1’de 5. ve 6. Sütunlarda
görülmektedir. Kod kelimelerinin uzunluklarıyla tamamen uyuşan ideal kod
uzunlukları önemli bitlere bakılarak elde edilebilir.
3.2.3
Huffman Kodlaması
İhtimaller
2'nin basit katları olduğunda kod uzunlukları kolayca belirlenebilir.
Fakat 1/37 gibi bir rakamda 1 ne işe yarar? Huffman tarafından ortaya çıkarılan
kod tanımlama prosedürü bu problemi temizce çözer. Huffman bu işlemi,
küçük kodlar üreterek (en uygun olacak şekilde ve eşsiz öneklerle) ve
tablo içindeki tüm kodları kullanarak yapar. Ayrıca uygun miktarda
tamsayı uzunluk kodları sağlar. Sadece aritmetik kodlamada olduğu gibi
tamsayı olmayan uzunluk kodlama teknikleri Huffman kodlamasının kodlama
verimini arttırır.
3.2.4
Huffman Kodlarının Atanması
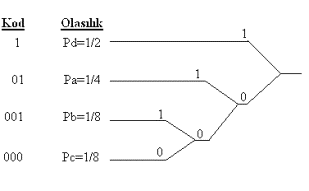
Huffman kod atamasında
kullanılan prosedür sembol çiftlerine ve sembol gruplarına dayanmaktadır.
Önceden verilen a,b,c ve d 'den oluşan sembol kümelerinden şekil
3.4’de kod ağacı yeniden oluşturulur. Genel olarak bu gibi bir ağaç düşük
olasılıklı sembol grupları veya bir sembol çiftinden geliştirilir ve
bir ağacın dallarını oluşturmak üzere birleştirilirler. Bir dal üzerindeki
olasılık basitçe iki sembolün veya grubun olasılıkları toplamıdır.
Ağaç tek dala inene kadar geliştirilir ve son olarak ağacın kökü kalır.
Daha sonra her çifte ait iki dal 1 ve 0 olan kod bitleriyle
doldurulur(atama işi keyfi yapılır). Özel sembol için kod kelimeleri, kökten
başlayarak sembol için uygun olan yapraklarla devam edilerek kod
bitlerinin zincir hale getirilmesiyle elde edilir. Bu tarzla oluşturulan
kod kelimelerinin giriş kümelerine Huffman Kod Tablosu denir. Burada verilen örneklerde olasılıkların
ikinin tam katları olduğu varsayılmıştır ve genelde de bu teknik
kullanılır.
Şekil 3.4 -
Huffman Kodlama Ağacı
3.2.5
Uyarlamalı (Adaptive) Dağınım Kodlaması
MPEG
uyarlamasız bir kodlama sistemidir ve böylece sabit kod tabloları kullanır.
MPEG kod tablolarını kurmak için birçok görüntü dizisi kodlanır ve
tablo içindeki her kod kelimesine ait istatistikler toplanır. Tabiki ideal
olarak kod kelimesi uzunlukları istatistiklere tamamen uymak zorundadır.
İdealden küçük sapmalar olduğu vakitlerde uyarlamasız kodlama nispeten
biraz daha güçlüdür. Eğer bir sembol için atanan kod kelimesi çok
uzun olursa diğer sembol için atanan kod kelimesi çok kısa olacaktır.
Bu nedenle sembol olasılıkları farzedilen değerlere çok yaklaşmazsa
bazı semboller için yükseltgenen bit sayısı diğer indirgenen bit sayılarıyla
kısmen denkleştirilir. Eğer sapmalar küçük olmazsa kodlama verimi düşer
ve uyarlamalı kodlama böylece daha dikkate değer bir sıkıştırma sağlar.
Uyarlamalı
dağınım kodlamasında kod tabloları sembol olasılıkları ile en çok
uyuşacak şekilde değiştirilir. JPEG resim sıkıştırma formatında özel
bir resim için kullanılan istatistiklere uygun Huffman tabloları sıkıştırılmış
resmin bir parçası gibi iletilebilir.
JPEG ayrıca, dağınım kodlamasının alternatif bir şeklini ve
uyarlamalı aritmetik kodlama sunar.
Bu özellikler bir resim içersinde değişen istatistiklere bile uyum sağlar.
Doğal
olarak, uyarlamalı kodlamada, kodlama verimi kazancı için biraz taviz
verilmelidir. Bu sistem genellikle çok komplekstir.
3.2.6
Sembol Olasılıkları
Tablo
2.1’de sembol olasılıkları, sembol sayılarından hesaplanmıştı.
Bunun yapılmasındaki amaç, farz edilen sayımların yüksek sayıdaki
tipik mesajların ortalamasının ihtimaller için güvenilir değerlerin
hesaplanabilmesini yeterince sağlayabilmek için tüm semboller yeterince
oluşmaktır. Bir sembol teorik olarak mümkünse bazen oluşur, fakat kod
tablosunu tamamlamak için kullanılan mesajlar içinde hiçbir zaman oluşmaz.
Kod tablosu herhangi bir uygun mesajı temsil edebilmelidir ve bu olay sıfır
frekans problemi diye bilinen bir problemi ortaya çıkarır. Bu şöyle
açıklanır; eğer olay frekansı sıfırsa ve sembol sayısının toplam
sayıya oranından hesaplanan olasılık sıfırsa bu yüzden ideal kod
uzunluğu sınırsız olacaktır. Sıfır frekans problemini çözmede
kullanılan genel bir yöntem tüm sembol sayılarını "0" yerine
"1"den başlatmaktır.
3.3 İstatistiksel Modeller
İstatistiksel
model kodlayıcı model içine baştan başa dağıtılmıştır. Resim
elemanı (pel) farklılıklarını alarak verileri ilişkisizlendirme (decorrelation)
veya DCT'nin hesaplanması istatistiksel modelin birer parçasıdır. Ayrıca
istatistiksel modelin çok önemli bir başka görevi ilişkisizlendirilmiş
temsilin elde edilmesi esnasındadır. Bu da verimli bir sembol kümesinin
oluşturulması içindir.
Bu
sembolleri kullanarak DCT katsayılarını veya resim elemanı (pel) farklılıklarını
kodlamak kesinlikle mümkündür. Ancak ne zaman sembol olasılıkları çok
büyüse Huffman kodlaması sınırlama ve tamsayı kod kelimeleri nedeniyle
yetersiz kalır. 0.5 sembol olasılığına bağlı olarak mümkün olan en
küçük kod uzunluğu 1 bittir. Eğer olasılık 0.5 'in üzerine tırmanacak
olursa kod uzunluğu 1'de kalır ama yine de ideal olarak küçük olması
gerekir.
Bu
problem için çözüm yolu DCT katsayısına ve resim elemanı (pel) farklılıklarına
dayanan sembolleri birleştirmektir. Bu istatistiksel modelin anahtar noktasıdır.
Sembolleri
birleştirirken, eski sembollerin her mümkün kombinasyonu için bir ayırma
sembolü gereklidir. Her sembol için olasılık içersinde birleştirilen
eski sembollerin sonucu olarak verilir. Örnek olarak; MPEG'de kullanılan
DCT (ayrık kosinüs dönüşümü), özellikle yüksek frekanslarda tipik
olarak birden fazla sıfır katsayısına sahiptir. Bu nedenle 0 değerinin
olasılığı 0.5'in üzerinde olacaktır v katsayıları ayrı ayrı
kodlamak verimsiz olacaktır. Onun yerine, düşük olasılıklarda yeni
semboller oluşturmak için sıfır (0) katsayı değerleri değişik
yollarla birleştirilir. Her yapılan kombinasyona bir sembol verileceğinden,
sembolleri birleştirme işlemi alfabenin boyutunu büyütecektir. Fakat
kodlama verimi bayağı artacaktır.
İstatistiksel
model koşullu olasılık yöntemlerini de kullanır. Koşullu olasılıklar
öncelikli olaylara bağlı olan olasılıklardır. Mesela, tipik İngiliz
metin dokümanlarında metin içinde bulunan "u" harfinin olasılığı
yaklaşık 0.02'dir. eğer "q" harfi ortaya çıkarsa
"u"nun olasılığı artar ve 0.95 civarına gelir. Eğer bir olasılık
geçmişte kodlanan sembollerin bir fonksiyonu ise buna koşullu
olasılık (conditional probability) denir. Kod tabloları koşullu olasılıklara
dayandırıldığında kodlama öncelikli sembollere şartlanır.
Bir
çok sıkıştırma sistemi koşullu olasılıkları kullanır. Örnek
olarak MPEG, kodlanmış resmin tipine bağlı olarak kod tablolarını değiştirir.
3.4 Kodlama Modelleri
Daha
önce bir sinema film şeridini incelemiş olan herkesin bileceği gibi
sinema içindeki resimler birinden diğerine çok benzerlik arz eder. Ek
olarak, her resmin sayısallaştırılmasından dolayı oluşan iki boyutlu
örnek dizileri yüksek seviyede ilişkilidirler. Bu da bir resim içindeki
yan yana bulunan örneklerin yoğunluk bakımından birbirine çok benzer
olmasından kaynaklanır. Bu bir resimden diğerine olan ilişkiden dolayı
resim dizileri etkin bir biçimde sıkıştırılabilmektedir.
3.4.1 I-, P- ve B- Resimleri
MPEG
bir dizi içindeki resimleri 3 ana kategoriye ayırır. İçsel-kodlanmış
(Intra-Coded) veya I-resimleri dizi içersinde önceki veya sonraki
resimlere referans almadan kodlanırlar. Tahmini-resimler (Predicted-Pictures)
veya P-resimleri zamansal olarak en yakın önceki I veya P-resimlerine
referansla kodlanırlar. Çift yönlü kodlanmış resimler (Bidirectionally
Coded pictures) veya
B-resimleri dizi içinde I-resimleri ve B-resimleri arasına serpiştirilmiştirler
ve en yakında bulunan önceki veya sonraki veya her ikisine de referans
alarak kodlanırlar. Bununla beraber B-resimleri aynı dizi içinde birkaç
yerde bulunabilir. B-resimleri hiçbir zaman diğer bir resmi önceden
bildirmek için kullanılamaz.
3.4.1.1 Resimiçi (Intraframe)
Sıkıştırma Modu
Bu
modda JPEG ‘de olduğu gibi piksel değerlerinin ayrık kosinüs dönüşümü
alınır ve sıkıştırma nicelendirme değerlerinin farklı seçilmesi değişken
uzunluklu kodlama sayesinde elde edilir.
Tablo 3.2 - MPEG Resim içi (intra) nicelendirme matrisi
8
16
19 22
26
27
29
34
16
16
22
24
27
29
34
37
19
22
26
27
29
34
34
38
22
22
26
27
29
34
37
40
22
26
27
29
32
35
40
48
26
27
29
32
35
40
48
58
26
27
29
34
38
46
56
69
27
29
35
38
46
56
69
83
8-bitlik
piksel bilgisi üniform olarak kuantalanıp ayrık kosinüs dönüşümü alınırsa;
DA bileşeni için 0...2048 arası, AC bileşenler için ise –1024...1023
arası değerler elde edilir. Bu değerler frekansın yüksekliğine göre
değişen sayıda basamaklı olarak nicelendirilir (üniform olmayan
nicelendirme). Yeni nicelendirilmiş değeri bulmak için DCT çıkışı
Tablo 3.2.’de verilen değere bölünüp en yakın tam sayıya
yuvarlanır. Sonuç olarak DA bileşeni 8-bit, en yüksek frekanslı bileşen
ise 4-bitle nicelendirilmiş olur (2048 : 8 = 256 seviye → 8-bit ;
2048 : 83 = 25 seviye → 4-bit). Bu değerler insan gözünün ayırma
özelliklerine göre seçilmiştir. Bu şekilde nicelendirilmiş
makrobloklara kısaca “intra”
denilir.
MPEG’de
ayrıca uyarlamalı nicelendirme kullanılır. Burada insan gözünün düz
renklerdeki değişimi desenli renklerdeki değişimlerden daha kolay fark
etmesi özelliğinden yararlanılır. Düz bloklar daha fazla bit, desenli
bloklar daha az bit kullanılarak nicelendirilir. Böylece JPEG’e göre
%30 daha fazla sıkıştırma elde edilir. Bu tür kodlanmış makrobloklara
“intra-A” denir.
Kodlama
devresinde; DA bileşeni farksal darbe
kod modülasyonu (Differential Pulse Code Modulation : DPCM) ile
kodlanarak sıkıştırma sağlanır. Değişken işaret bileşenleri
genellikle JPEG’de olduğu gibi zikzak tarandıktan sonra Huffman benzeri
bir kodlama ile (gereksiz sıfırlar atılarak) kodlanır.
3.4.1.2 Resimlerarası(Interframe) Sıkıştırma Modu
Bu
modda görüntünün zaman içinde alacağı yeni değer daha önceki değerlerden
yararlanarak kestirilir. Kestirilen resimle gerçek resim karşılaştırılarak
sadece aradaki hata sinyali kodlanır ve karşı tarafa gönderilir. İki tür
çerçeve söz konusudur.
P-tipi
çerçeveler sadece ileri yönde kestirilir. Hareket düzeltmeli ileri yönde
kestirim (motion compensated forward
prediction) için daha önceki I-tipi veya P-tipi çerçeveler kullanılır.
P-tipi çerçevelerdeki makroblokların kodlaması I-tipinde olduğu gibi “Intra”
veya “Intra-A” olabileceği gibi, “inter-D”,
“inter-DA”, “inter-F”, “inter-FD”,
“inter-FDA” gibi değişik
şekillerde olabilir. Bu kodlama tiplerinde “inter”kelimesi
kodlamada resimlerarası bilginin (zaman içindeki değişimin) kullanıldığını;
“D”harfi kestirme hatasının
DCT olarak kodlandığını; “A” harfi
uyarlamalı (adaptif) kodlama yapıldığını; “F”
harfi ise ileri yönde hareket düzeltmesi yapılacağını gösterir.
Örnek
olarak eğer kodlama “inter-F”
olarak adlanmışsa, hareket düzeltmeli
ileri yönde kestirimin yeterli olduğu ve bu durumda sadece hareket
vektörünün karşı tarafa gönderileceği
anlaşılır. “inter-FD” bloğunda ise
hareket vektörü yanında hata bilgisi de gönderilir. Eğer blok “inter-FDA”
olarak adlanmışsa hareket vektörü ve hata bilgisi ile uyarma katsayısının
da iletilmesi gerekir. Eğer bir makroblok bir önceki çerçevedeki ile aynı
ise atlanır ve hiç iletilmeyebilir. Bu tip bloklara “skipped”denir.
3.4.2
MPEG Kodlama Modelleri
Dizi
içerisinde I-resimleri komşu resimlerden referans almadan kodlandığı
zaman, kodlama modeli resim içindeki ilişkilerden yararlanmalıdır.
I-resimleri için MPEG2in kullandığı model JPEG tarafından tanımlanan
modele benzerdir.
P-resimleri
ve B-resimleri farklar olarak kodlanırlar. Yani kodlanan resimle referans
resim arasındaki farklar olarak kodlanırlar. Eğer görüntü bir resimden
diğerine değişmiyorsa o zaman fark da sıfır olacaktır. Sadece değişen
alanların yenilenmeye ihtiyacı vardır. Bu işlem şartlı
yeniden doldurma (conditional replenishment) olarak bilinir. Eğer dizi
içersinde hareket varsa, referans resimle o anda bulunan resim arasındaki
resim elemanı (pel) farklılıkları nedeniyle daha iyi bir kestirim elde
edilebilir. Hareket kompanzasyonu P ve B-resimleri için çok önemli bir
kodlama modeli bölümüdür.
Bir
I-resmi veya P- veya B-resmi için hareket kompanzasyonu farkı verilmiş
olsun. Kodlama modelini tamamlamak için 2 temel yöntem kullanılır: ayrık
kosinüs dönüşümü (DCT) ve kestirimci model. DCT tabanlı model tüm
resim tiplerini kodlamada ortak bir modeldir ve MPEG içinde merkezi bir rol
oynar. DCT katsayılarının nicelendirilmesi işlemi sayesinde MPEG kodlama
sistemi iyi bir avantaj sağlar. Bunu da insan gözünün aydınlık ve
renge karşı gösterdiği tepkilerden yararlanarak yapar. Bunun manası da
kodlama modellerinin katsayıların koşullu istatistiksel özelliklerini
hesaba katmalarına gerek olmadığı demektir.
Nicelendirilmiş
DCT katsayılarının kodlaması kayıpsızdır. Çünkü kod çözücü tam
olarak aynı nicelendirilmiş değerleri üretebilmektedir. Kodlama
modelleri kodlanan resmin tipine bağıdır.
3.4.3
I Resimleri'nin Kodlanması
I-resimlerinde
verilen bir blok içindeki DCT katsayılarının tamamına yakını ilişkisizlendirilmiştir. Ancak yine de verilen blok içindeki
katsayılar arasında ve komşu blokların katsayıları arasında bazı ilişkiler
olabilir. Bu anlatım DC katsayılar tarafından temsil edilen blok
ortalamaları için özellikle doğrudur. Bu nedenden dolayı, kestirimci
DPCM tekniği denilen bir teknikle DC katsayılar AC katsayılardan ayrı
olarak kodlanır.

I-tipi çerçeveler başlangıç resimleri olup bunlarda sadece
JPEG’de uygulanan çerçeve içi sıkıştırma uygulanır. Yani çok az sıkıştırılırlar.
Bir görüntünün oluşturulabilmesi için mutlaka I-tipi
çerçeveden başlamak gerekir. P-tipi
çerçeveler daha önceki resimlerden yararlanarak kestirim yöntemiyle
bulunan resimler olup bunlar daha sonraki çerçeveler için referans olarak
kullanılırlar. B-tipi çerçeveler
ise I ve P tipi çerçeveler kullanılarak, önceki ve sonraki çerçevelerin
iç değer biçimi (interpolation) ile elde edilen resimlerden oluşur.
Şekil 3.5 - MPEG Çerçevelerinin Gruplanması
Değişik
cinsten bir takım çerçevelerden oluşan guruba “Resimler
Gurubu” denir. Bir guruptaki çerçeve sayısı uygulanmaya göre değişebilir.
Şekil 3.5’de 9 çerçeveden oluşan bir gurup görülmektedir. Bu
guruptaki çerçevelerin iletim sırası 0, 4, 1, 2, 3, 8, 5, 6, 7 veya 0,
1, 4, 2, 3, 8, 5, 6, 7 şeklinde olabilir.
MPEG
yöntemi , sıkıştırma için, çerçeveler arası benzerlikten ortaya çıkan
zaman içindeki fazlalık bilgiden (Redundancy)
büyük ölçüde yararlanır. Burada belli bir andaki görüntü çerçevesinin
daha önceki ve daha sonraki çerçeve bilgileri kullanılarak bulunabileceği
veya kestirilebileceği varsayımından hareket edilir. Ayrıca hareket
bilgisinden de yararlanılarak hatalar büyük ölçüde azaltılır. Böylece
çok yüksek sıkıştırma oranları elde edilir. Çerçeve içi
benzerliklerden yararlanarak sıkıştırma yapmak için JPEG’ de olduğu
gibi ayrık kosinüs dönüşümünden yararlanılır. Ayrık kosinüs dönüşümü
(DCT) için 8x8’lik bloklar kullanılır. Burada ayrıca 4 parlaklık
seviyesi (luminance) ve 2 renk
farkı bilgisi bloğundan meydana gelen “makro
bloklar” (MB) vardır.
Bir
çerçevedeki makro bloklar değişik şekillerde kodlanabilir.
3.4.3.1 I Resimlerinde DC Katsayıların Kodlanması
Aşağıdaki
eşitlikte görüldüğü gibi, komşu bloğun kodlanan DC değeri olan P harfi o anki blokta bulunan DC değer kestirimini ifade eder. DDC fark
değeri genellikle sıfıra yakın olacaktır;
DDC = DDC - P
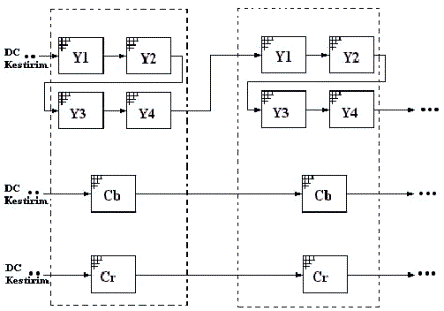
Dikkat edilmesi
gerekir ki kestirimi sağlayan blok, makroblok içindeki blokların kodlama
sırasından elde edilir. Şekil 3.6 kodlama ve kestirim dizisinin bir taslağını
vermektedir.
Şekil 3.6 -
Makroblokların kodlanma Sırası ve Ardışıl DC Kestirim Dizisi
DDC 'nin
kodlanması işlemi, büyüklük kategorisinin kodlanması ve doğruluk
işareti ile genlik değerlerini belirten
ek bitlerin kullanımı ile olur. Parlaklık (aydınlık) ve
renklilik için büyüklük kategorileri ve
buna uygun kod kelimeleri Tablo 3.3’de verilmiştir;
Tablo 3.3 -
Tablo Aydınlık (Luminance) ve Renklilik (Chrominance) için DC Kod Tablosu
|
Y
kodu |
C
kodu |
Büyüklük |
Büyüklük
Aralığı |
|
100 00 01 101 110 1110 11110 111110 1111110 |
00 01 10 110 1110 11110 111110 1111110 11111110 |
0 1 2 3 4 5 6 7 8 |
0 -1,1 -3..-2,2..3 -7..-4,4..7 -15..-8,8..15 -31..-16,16..31 -63.-32,32..63 -127..-64,64..127 -255..-128,128..255 |
Büyüklük kategorisi, DC farkı tam olarak açıklamak için gerekli
olan bitlerin sayısını belirtir. Eğer yukarıdaki tabloda değer
"0" ise o zaman DC fark da "0" olur. Aksi takdirde büyüklük
bitleri büyüklük kodunu takip edecek şekilde bit akışına eklenir. Bu
bitler büyüklük ve işaret değerlerini tamamıyla açıkça
belirtebilmek için ilave bilgiler kaynaklanmasını sağlarlar.
Fark
değerlerinin kodlanması işlemi tam olarak JPEG 'deki gibi yapılır.
Verilen bir farkı kodlamak için ilk olarak büyüklük kategorisi
belirlenir ve kodlanır. Eğer fark değeri negatifse 1 çıkarılır. Böylece
farkın düşük konumlardaki büyüklük bitleri bit akışına eklenir.
Tablo 3.4’de birkaç örnek gösterilmektedir.
Tablo 3.4 - DC Fark Kodlaması Örnekleri Tablosu
|
Onlu
Fark |
İkili
Fark |
Büyüklük |
İlave
Bitler |
|
+5 +4 +3 +2 +1 +0 -1 -2 -3 -4 -5 |
...00101 ...00100 ...00011 ...00010 ...00001 ...00000 ...11111 ...11110 ...11101 ...11100 ...11011 |
3 3 2 2 1 0 1 2 2 3 3 |
101 100 11 10 1 - 0 01 00 011 010 |
3.4.3.2 I Resimlerinde AC Katsayıların Kodlanması
DCT (Ayrık kosinüs Dönüşümü) tarafından sağlanan ilişkisizlendirme
işlemi AC katsayılarından birbirinden bağımsızca kodlanmasına müsaade
eder ve bu da kodlama işlemini oldukça basitleştirir. Verilen bir katsayının
kodlanması diğer katsayılardan bağımsız olmasına rağmen dizi içersinde
katsayının bulunacağı yer önemlidir.

Yüksek uzaysal
frekansları temsil eden katsayılar çoğunlukla "0" iken düşük
frekans katsayıları genellikle "0" değildir. Bu sistemi
kullanabilmek için, katsayılar nitelikli olarak düşükten yükseğe doğru
uzaysal frekansları izleyecek şekilde sıralanırlar. Bunu yaparken de sıralanırlar.
Bunu yaparken de zikzak tarama düzeni
denen bir yol izlenir. Zikzak tarama düzeni şekil 3.7’de görülmektedir.
Şekil 3.7 -
DCT Katsayılarının Zikzak Düzeni
Zikzak
taramada katsayılar, olasılıklarının "0" olması sırasına göre
yaklaşık biçimde düzenlenir. Tipik olarak 8x8 'lik bir bloğun bir
zikzak düzenlemesinde bir çok katsayı "0" olmaktadır. Bu
nedenden ötürü, sıfır katsayılarını bileşik (composite) sembollerle
birleştirmeden bloğu verimli bir şekilde kodlamak mümkün olabilir.
Bileşik
sembole verilebilecek en önemli örneklerden biri blok
sonudur (End-of-Block - EOB). Blok sonu sembolü zikzak düzenlenmiş
DCT içindeki tüm sıfır katsayılarını tek bir kod kelimesiyle kodlar.
tipik olarak bir blok sonu dizinin orta noktasından önce bulunur ve iki
bitlik olarak kodlanır. Dikkat edilmesi gerekir ki her katsayının bağımsızca
kodlandığı düşünüldüğünde, aynı bilgiyi kodlamak için 60 bite
ihtiyaç olacaktı.

Blok sonu kodlaması
şekil 3.8’de örneklenmiştir. Kodlama, düşük frekans katsayısından
başlar ve zikzak düzen içinde sıfır olmayan katsayı kalmayana dek
devam eder. Blok sonunun kodlanmasıyla birlikte bloğun kodlanması işlemine son
verilir. Blok sonu kodu iki bit uzunluğunda kısa bir koddur.
Şekil
3.8 - MPEG ve JPEG 'de Blok Sonu Kodlaması:
(a) DCT
iki boyutlu bir dizi olarak düşünüldü. Nicelendirme işleminden sonra tüm
yüksek frekanslar "0" oldu. (b) Zikzak Düzenlenmiş katsayılar
izleyen sıfırlarla birlikte EOB (Blok sonu) sembolüyle yer değiştirildi.
(c) Zikzak Düzenlenmiş katsayılar EOB sembolleri ve DDC
= 132 - P bileşen çalışma/seviyesi (run/level) olarak temsil edildi.
Sıfır
katsayıları EOB sembolünden önce sıklıkla görülebilir. Bu durumda
daha iyi bir kodlama verimi elde edilir. Her sıfırdan farklı AC katsayı
bu çalışma-seviye sembol (run-level symbol) yapısını kullanılarak
kodlanır. Buradaki "çalışma" (run),bir sonraki sıfırdan
farklı katsayıdan önce gelen sıfır katsayıların sayısını belirtir.
"Seviye" (level) ise sıfırdan farklı katsayıların genliğini
belirtmektedir. Yukarıdaki şeklin (şekil 3.8) c bölümünde bu olay görülmektedir.
Her çalışma-seviye kodunu izleyen bit, sıfırdan faklı katsayıların işaretini
kodlayan s'dir. Eğer s sıfır ise katsayı pozitif olacak, diğer hallerde
ise negatif olacaktır.
Tablo
3.5’de görüntülenen MPEG AC kod tablosunda yüksek sayıda çalışma-seviye
(run-level code) kodlarına yer verilmiştir. EOB (blok sonu) sembolü de
iki bit koduyla birlikte gösterilmektedir. Bu tabloda bulunmayan çalışma
uzunlukları ve seviye kombinasyonları kaçış kodlarıyla birlikte kodlanırlar.
Bu kaçış koduna 8 bit çalışma uzunluğu kodu ile birlikte 8 veya 16
bit seviye kodu eklenir. İlk bakışta biraz kafa karıştırıcı gibi görünen
çalışma 0 / seviye 1 için kodlar Tablo 2.5’de listelenmiştir. İlk
olarak, neden iki kod kullanılmıştır? İkinci olarak da, ikili kod
"1s" (s sıfırdan farklı bir katsayının işaretini gösterir)
blok sonu kodu (EOB) olan ikili "10" kodu ile neden çakışmamaktadır?
Bunların nedeni kod tablosunun ikili bir amaç için kullanılmasından
dolayıdır. Çünkü gerçekten iki kod tablosu birleştirilerek bir kod
tablosuna aktarılmıştır. Çoğu durumlarda EOB (blok sonu) olayı oluşur
ve sonraki (next) diye adlandırılan
giriş kullanılır. Ancak içsel olmayan (nonintra) kodlamada tamamen sıfır
olan DCT bloğu yüksek seviyeli bir prosedür olarak kodlanır ve blok sonu
(EOB) ilk çalışma-seviyesi 'ni kodlamadan önce oluşamaz. Bu özel
durumda ilk (first) diye adlandırılan
giriş kullanılır.
İlk
(first) diye adlandırılan kodlar sadece içsel olmayan (nonintra)
kodlamada kullanılır. İçsel (intra) kodlama içinse DC ayrı olarak
kodlanır ve herhangi bir sıfırdan farklı katsayı olmasa bile blok sonu
(EOB) meydana gelebilir. Sonuç olarak, ilk giriş nedeniyle "1s"
blok sonu (EOB) kodu ile çakışır v kullanılmaz.
Tablo 3.5 - Çalışma-Seviyesi (run-level) Kombinasyonları için Değişken
Uzunluk Kodları
|
Çalışma/Seviye
(run/level) |
VLC |
Bit
Sayısı |
|
0/1 0/1 0/2 0/3 0/4 0/5 0/6 0/7 0/8 0/9 0/10 0/11 0/12 0/13 0/14 0/15 0/16 0/17 0/18 0/19 0/20 0/21 0/22 0/32 0/24 0/25 0/26 0/27 0/28 0/29 0/30 0/31 0/32 0/33 0/34 0/35 0/36 0/37 0/38 0/39 0/40 1/1 1/2 1/3 1/4 1/5 1/6 1/7 1/8 1/9 1/10 1/11 1/12 1/13 1/14 1/15 1/16 1/17 1/18 2/1 2/2 2/3 2/4 2/5 3/1 3/2 3/3 3/4 4/1 4/2 4/3 5/1 5/2 5/3 6/1 6/2 6/3 7/1 7/2 8/1 8/2 9/1 9/2 10/1 10/2 11/1 11/2 12/1 12/2 13/1 13/2 14/1 14/2 15/1 15/2 16/1 16/2 17/1 18/1 19/1 20/1 21/1 22/1 23/1 24/1 25/1 26/1 27/1 28/1 29/1 30/1 31/1 Blok
Sonu (EOB) Kaçış
(Escape) |
1s (ilk) 11s (sonraki) 0100 s 0010 1s 0000 110s 0010 0110 s 0010 0001 s 0000 0010 10s 0000 0001 1101 s 0000 0001 1000 s 0000 0001 0011 s 0000 0001 0000 s 0000 0000 1101 0s 0000 0000 1100 1s 0000 0000 1100 0s 0000 0000 1011 1s 0000 0000 0111 11s 0000 0000 0111 10s 0000 0000 0111 01s 0000 0000 0111 00s 0000 0000 0110 11s 0000 0000 0110 10s 0000 0000 0110 01s 0000 0000 0110 00s 0000 0000 0101 10s 0000 0000 0101 01s 0000 0000 0101 00s 0000 0000 0100 11s 0000 0000 0100 10s 0000 0000 0100 01s 0000 0000 0100 00s 0000 0000 0011 000s 0000 0000 0010 111s 0000 0000 0010 110s 0000 0000 0010 101s 0000 0000 0010 100s 0000 0000 0010 011s 0000 0000 0010 010s 0000 0000 0010 001s 0000 0000 0010 000s 011s 0001 10s 0010 0101 s 0000 0011 00s 0000 0001 1011 s 0000 0000 1011 0s 0000 0000 1010 1s 0000 0000 0011 111s 0000 0000 0011 110s 0000 0000 0011 101s 0000 0000 0011 100s 0000 0000 0011 011s 0000 0000 0011 010s 0000 0000 0011 001s 0000 0000 0001 0011 s 0000 0000 0001 0010 s 0000 0000 0001 0001 s 0000 0000 0001 0000 s 0101 s 0000 100s 0000 0010 11s 0000 0001 0100 s 0000 0000 1010 0s 0011 1s 0010 0100 s 0000 0001 1100 s 0000 0000 1001 1s 0011 0s 0000 0011 11s 0000 0001 0010 s 0001 11s 0000 0010 01s 0000 0000 1001 0s 0001 01s 0000 0001 1110 s 0000 0000 0001 0100 s 0001 00s 0000 0001 0101 s 0000 111s 0000 0001 0001 s 0000 101s 0000 0000 1000 1s 0010 0111 s 0000 0000 1000 0s 0010 0011 s 0000 0000 0001 1010 s 0010 0010 s 0000 0000 0001 1001 0010 0000 s 0000 0000 0001 1000 s 0000 0011 10s 0000 0000 0001 0111 s 0000 0011 01s 0000 0000 0001 0110 s 0000 0010 00s 0000 0000 0001 0101 s 0000 0001 1111 s 0000 0001 1010 s 0000 0001 1001 s 0000 0001 0111 s 0000 0001 0110 s 0000 0000 1111 1s 0000 0000 1111 0s 0000 0000 1110 1s 0000 0000 1110 0s 0000 0000 1101 1s 0000 0000 0001 1111 s 0000 0000 0001 1110 s 0000 0000 0001 1101 s 0000 0000 0001 1100 s 0000 0000 0001 1011 s 10 0000 01 |
2 3 5 6 8 9 9 11 13 13 13 13 14 14 14 14 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 16 16 16 16 16 16 16 16 16 4 7 9 11 13 14 14 16 16 16 16 16 16 16 17 17 17 17 5 8 11 13 14 6 9 13 14 6 11 13 7 11 14 7 13 17 7 13 8 13 8 14 9 14 9 17 9 17 9 17 11 17 11 17 11 17 13 13 13 13 13 14 14 14 14 14 17 17 17 17 17 2 6 |
3.4.4
P- ve B- Resimlerinin Kodlanması
DCT
'nin ilişkisizlik (decorrelation) özelliği sadece içsel (intra) kodlanan
resimlere uygulanabilir. İçsel olmayan (nonintra) resimler ise bir başka
resme bağlı olarak yapılan tahmine göre kodlanırlar ve tahmin işlemi
veriler üzerinde ilişkisizlendirme görevini büyük ölçüde halleder.
Rao ve arkadaşları tarafından yürütülen belli başlı çalışmalar içsel
olmayan (nonintra) resimlerin DCT tarafından uygun bir biçimde ilişkisizlendirilemeyeceğini
göstermiştir. Eğer ilişki (correlation) çok az olursa küçük katsayı
ilişkilerini görmezden gelmek kodlama verimini fazla azaltmayacaktır.
DCT
'nin kullanılmasının ana sebebi nicelendirme (quantization) işlemidir.
P- ve B- resimleri için oldukça kaba bir nicelendirme işlemi yapılabilir
ve bit oranları da gayet düşük olacaktır. Ama düzce hazırlanmış bir
nicelendirme tablosu insanın görsel sisteminin özelliklerinden tamamıyla
yararlanamayacaktır. DCT nicelendirmesi bit oranını düşürmede etkili
bir araçtır.
P-
ve B- resimlerinin kodlanmasında DC katsayı türevsel bir değerdir ve
matematiksel olarak AC katsayılara benzerlik arz eder. Sonuçta AC ve DC
kodlama tek bir işlem içine entegre edilmiştir.
Sıfırdan
farklı bir makro blok içindeki sıfır bloklar kodlanmış
blok deseni - kbd (coded blok pattern) denen 6 bit değişken kullanılarak
kodlanır. Bu 6 bitteki her bit uygun bir DCT'nin aktif veya sıfır olduğunu
gösterir. Kodlanmış blok deseninin değişken uzunluk kodları makroblok
içindeki sıfır blokları kodlar. kbd = 0 şartı makroblok adres artırımı
ile ele alınır ve makroblok atlanır.
Son
olarak, sıfırdan farklı olan her blok kodlanmış olmalıdır, zaten
tablo 3.5’deki kodlar böyle kullanılmıştır. Bu tabloda ilk giriş değeri
olan çalışma 0 / seviye 1 değeri atlanmış ve AC katsayıların içsel
kodlamasına eklenmiştir. P- ve B- resimleri için se tüm tablo kullanılmıştır.
 |
İlk çalışma-seviyesini kodlarken ilk giriş değeri olan çalışma 0 - seviye 1 değerleri kullanılmıştır. Bu durumda en az 1 adet sıfırdan faklı katsayı kodlanmadan blok sonu (EOB) meydana gelmez. Çünkü, sıfır bloğu koşulu kodlanmış blok deseni tarafından kodlanacaktır. Bundan sonra, artık blok sonu oluşabilir ve çalışma 0 - seviye 1 için ikinci giriş kullanılmalıdır. Bu tablo tam olarak bir Huffman tablosu olmamasına karşın yaklaşım gayet güzeldir. Çünkü iki ayrı tabloya olan ihtiyaçtan birini elemek çok akıllıca bir yoldur.

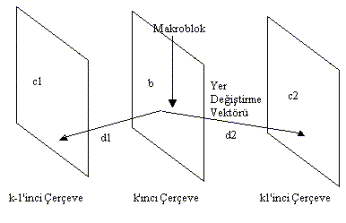
Şekil 3.9 -
MPEG İki yönlü kestirim
B-tipi
çerçeveler I-tipi ve P-tipi
çerçevelerden yararlanarak iki yönlü olarak kestirilir. Kestirilen bloğun
gerçek değerinin b harfi ile,
kestirilen değeri ise “b”
gösterirsek :
b
= α1c1 + α2c2 : α1
+ α2 = 1 olur. Burada c1 önceki ve c2
sonraki, yeniden oluşturulmuş çerçevelere ait ve b
bloğuna karşı düşen blokları göstermektedir. α1,
α2 katsayıları ağırlıkları gösterir ve “0, 0.5,
1” değerlerini alabilirler. α1 = 1 : α2 = 0
ileri yönde, α1 = 0 : α2 = 1 geri yönde,
α1 = 0.5 : α2 = 0.5 her iki yönde kestirimi
gösterir. b – b ise kestirim
hatasıdır.
İki
yönlü kestirme ve iç değerbiçimine (interpolation) dayanan bu tür
kodlamaya Zamanda Çoklu Ayırıcılı Teknik (Temporal Multiresolution Technique)
adı verilir. Bu yöntemde önce I
ve P-tipi çerçeveler kodlanır.
Bundan sonra B-tipi çerçeveler
iç değerbiçim yapılarak elde edilir. B-tipi
çerçeveleri kullanmanın sağladığı avantajları şöylece özetleyebiliriz;
Gölgelenen
arka planların işlenmesinde kolaylıklar sağlanır. Örnek olarak bir
nesne bir sonraki çerçevede başka bir cisim tarafından kapatılsa bile
onunla ilgili bilgiler hala kullanılabilir.
İki
çerçevenin ortalaması olarak hesaplanan bir görüntüde gürültü daha
azdır.
B-tipi
çerçeveler daha sonraki çerçevelerin oluşturulmasında kullanılmadığı
için hatanın devam etmesi söz konusu değildir.
Buna
karşılık;
·
B-tipi
çerçevenin oluşturulması için I ve
P-tipi en az iki çerçeve
gerektiği için alıcıda en az iki çerçevelik hafıza gerekir.
·
Eğer
B-tipi çerçevelerin diğerlerine
oranı çok fazla olursa çerçeveler arası ilinti azalacağından hata
miktarı artar ve bunu kodlamak için daha çok sayıda bit iletilmesi
gerekir. Bu aynı zamanda kodlama için gerekli gecikme zamanını da arttırır.
B-tipi
çerçevelerdeki makrobloklar da P-tipi
gibi kodlanabilirler. Bunlara ek olarak “inter-I”,
“inter-ID”, “inter-IDA” tipi bloklar da vardır. Buradaki I
harfi bu blokların hareket düzeltmeli interpolasyon yöntemiyle elde
edildiğini göstermektedir.
Çerçeveler
arası “Interframe” modunda fark işaretini kodlarken DCT girişi yine
(-255...255) arası olup çıkışta (-2048...2047) arası değişen değerler
elde edilir. Bunları nicelendirmek için değişik bir nicelendirme tablosu
kullanılır. Buradaki adımlar biraz daha kaba seçilir. Elde edilen değerler
yine değişken uzunlukta (VLC) kodlanır. Yer değiştirme vektörleri,
daha önceki blokların hareket vektörlerine göre farksal darbe kod modülasyonu
(DPCM) olarak kodlanır. Değişken uzunlukta (VLC) kodlamada tablolar
farksal hareket vektörleri ve kestirim hatasının değerine göre seçilir.
P ve B-tipi
çerçeveler için farklı Huffman tabloları kullanılır.
MPEG
kodlayıcıda I, P
ve B-tipi çerçecelerin oranı
uygulamaya bağlı olarak değişebilir. 13 çerçeveden en az bir tanesi I-tipi
olmalıdır. Hareket kestirim algoritması standarda dahil edilmemiştir. Değişik
algoritmalar kullanılabilir. Genelde bu iş için sadece parlaklık
seviyesi işareti (Luminance) kullanılır. Her makroblok için bir hareket
vektörü belirlenir. Hareket kestiriminde 0.5 piksel doğruluk istenir.
Vektörün uzunluğu resimden resime değişebilir. Ancak resmin dışına
taşan noktalara ilişkin hareket vektörleri kullanılamaz.
Kodlamanın
basamaklarını özet olarak şöyle sıralayabiliriz;
1.
Bir grup resimdeki çerçevelerin tipleri I, P ve B olarak
belirlenir.
2.
P ve B-tipi çerçevelerdeki makrobloklara ait hareket vektörleri
hesaplanır.
3.
Her bloğun tipi ve buna bağlı olarak sıkıştırma yöntemi
belirlenir (MTYPE).
4.
Uyarlamalı nicelendirme kullanılacaksa bunun oranı belirlenir (MQUANT).
Bu
işlemleri gerçekleştirmek için kullanılacak devrenin blok şeması
CCITT H.261 kodlayıcısı ile yanıdır. Ancak kullanılan dönüştürme
ve kodlama algoritmaları farklıdır.
Gelen
analog video işareti bir ön sinyal işleme devresi ile önce süzülür ve
Analog/Digital Çevirici ile sayısallaştırılır. İlk çerçeve I-tipi
olacağından bu çerçeve JPEG’de olduğu gibi makroblokları “inter”
tipinde kodlanmak üzere DCT bloğuna ve oradan nicelendirme devresine
verilir. Kodlanmış işarete ters kodlama işareti uygulanarak, resim, alıcıdaki
gibi, yeniden oluşturulur.
Bu
resim, resim hafızasına kaydedilir. Hafızadaki bu bilgi ve daha sonra
gelen çerçevedeki bilgiler kullanılarak görüntüdeki her makroblok için
hareket vektörleri hesaplanır. Bunlardan yararlanılarak ilk P-tipi çerçevenin
ne olması gerektiği kestirilir ve ayrı bir hafızaya kaydedilir. Bu iki
hafızadaki bilgiler kullanılarak ikinci çerçevenin ne olması gerektiği
kestirilir. Kestirilen resimle gerçek resim karşılaştırılarak aradaki
fark (hata) bulunur. Artık bu durumda resmin tamamını kodlayıp iletmek
gerekli değildir. Sadece bu hata işareti DCT devresine uygulanıp kodlanır.
Ayrıca bu çerçeveye ilişkin hareket vektörü de kodlanır ve elde
edilen bit dizisi tampon belleğe aktarılır. Tampon belleğin doluluk
derecesine göre nicelendirme adımları ayarlanır.
Bu
bilgilerin başına çerçevelerin sıralanışı, makroblokların tipleri (MTYPE),
varsa uyarlamalı (adaptive) sıkıştırma katsayısı (MQUANT) ve diğer
bilgiler eklenerek bir paket oluşturulur. Bu paket iletim hatalarından
korunmak için ayrıca bir hata kodlamasına tabi tutularak iletim hattına
verilir. Bu sayede iletim sırasında gürültü ve diğer etkilerden bazı
bitlerin bozulması alıcıda düzeltilerek alıcıda resmin bozulmasız bir
şekilde yeniden oluşturulması sağlanır.
3.5 Kodlayıcı ve Kod Çözücü Blok Diyagramları
Bu
bölümde ve önceki bölümlerde çeşitli kavramlar üzerinde duruldu. Bu
kavramlar yüksek seviyeli kodlayıcı ve kod çözücü blok diyagramları
oluşturmak için birleştirilebilir.
3.5.1
Yeniden İnşa Modülü
Şekil
3.10’da gösterildiği gibi, yeniden inşa modülü kodlayıcı ve kod
çözücülerin ikisi için de ortaktır. Bu modül kestirim için gerekli
olan resimleri yeniden inşa etmede kullanılır. Bu şekilde kullanılan
sinyal tanımları, izleyen kodlayıcı ve kod çözücü şemalarına
uygulanacaktır.
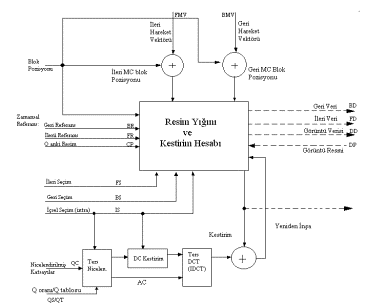
Yeniden inşa modülü,
bir ters nicelendirici birim, bir DC ön birim (içsel kodlanmış
makrobloklardaki DC katsayıların yeniden inşası için) ve ters DCT hesabı
için bir IDCT birimi içermektedir. IDCT çıkışı yeniden inşayı şekillendirmek
için kestirimle (içsel-kodlanmış makrobloklar durumunda sıfırdır)
birleştirilir. Kestirim resim stoğundaki verilerden hesaplanır. İçsel
olmayan kodlamadaki ileri ve geri yönde hareket yer değiştirmeleri uygun
bir şekilde yerleştirilir.
Şekil 3.10 -
Kodlayıcı ve Kod Çözücü İçin Ortak Kullanılan Yeniden İnşa Modülü
3.5.2
Kodlayıcı Blok Diyagramı
Şekil
3.10’da görülen yeniden inşa modülüne ek olarak şekil 3.11’deki
kodlayıcı modelinde birkaç değişik fonksiyonel bloklar vardır. Bunlar:
bir kontrolör, bir ileri DCT, bir nicelendirme birimi, bir VLC kodlayıcı
ve bir hareket hesaplayıcısıdır.
Modüllere
bakıldığında her şey açıkça anlaşılmaktadır. Kontrolör
senkronizasyon ve kontrol sağlamaktadır, ileri DCT FDCT'de ve Q modüllerinde
hesaplanır, ileri ve geri hareket hesabı hareket hesaplayıcı tarafından
gerçekleştirilir, hareket vektörlerinin hesabı ve DCT verisi VLC kodlayıcısı
tarafından yapılır. Hareket hesaplayıcı blok basit bir bölüm gibi görünebilir
fakat belki de sistemin en karmaşık parçasıdır. Dikkat edilmesi gereken
nokta yeniden inşa modülü kodlayıcı ve kod çözücü fonksiyonları için
genel bir yeterliliktir. Ayrıca sadece I- ve P resimlerinin yeniden inşasını
sağlayacak kodlama için basit
bir versiyon yeterlidir.

3.5.3
Kod Çözücü Blok Diyagramı
Kodlayıcıda
olduğu gibi şekil 3.10’da verilen yeniden inşa modülü kod çözücünün
(şekil 3.12) merkezi noktasını oluşturur. Bu durumlarda hareket yer değiştirmelerinin
kodları ve DCT verisinin
kodları VLC kodlayıcısında çözülürler.
 |
Şekil 3.12 - MPEG
Kod Çözücü Yapısı