Capitolo 2
Processi e Thread
Nei sistemi operativi di tipo Unix l'unità fondamentale per l'esecuzione
viene chiamata processo. Un processo consta di tre zone di memoria
chiamate regioni: dati, codice e stack; inoltre un processo è
dotato di una serie di proprietà che gli vengono assegnate dal sistema.
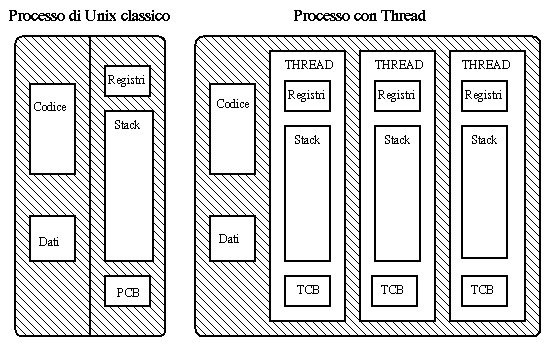 Figura 2.1: Processi e Thread
Figura 2.1: Processi e Thread
In Unix il processo è un'unità atomica. In questo lavoro,
invece, il processo è stato spezzato in unità contenute strettamente
al suo interno. Queste unità sono chiamate Thread e sostanzialmente
consistono in uno stack e in un Program Counter.
La regione dati e codice resta parte del processo e viene condivisa
da tutti i thread che si trovano all'interno del processo (fig. 2.1).
2.1 Schedulazione di Thread
Per poter realizzare un sistema in multiutenza si utilizza il metodo chiamato
time sharing, pertanto il kernel del sistema operativo decide
quando avviare, sospendere, riavviare e terminare l'esecuzione di ogni
Thread. Per fare ciò il kernel deve memorizzare una serie
di informazioni riguardanti i Thread in un'apposita struttura di dati chiamata
TCB (Thread Control Block) che viene associata a ciascuno dei Thread.
La definizione del TCB è la seguente:
struct Tcb {
char SMI, /* Modulo trasmittente */
RMI, /* Modulo ricevente */
PR, /* Priorita' */
PX, /* Indice del processo */
DATA[4], /* Campo dati */
SR[2], /* Registro di stato */
*a[8], /* Registri indirizzo: A0-A7 */
*d[8], /* Registri dato: D0-D7 */
*PC; /* Contatore del Programma */
short Stack, /* Stack assegnato */
heap; /* Heap assegnato */
int BornTime, /* Tempo di creazione */
Mem; /* Indirizzo Memoria Dati */
char ST_PR; /* Priorita' iniziale */
void (* fun)(); /* Puntatore alla funzione da eseguire */
unsigned int PID,PPID; /* Process ID */
CommandLine Command; /* Campo di dati esteso */
char Name[NameDim]; /* Nome del processo */
struct Tcb *CP; /* Puntatore al prossimo TCB */
};
typedef struct Tcb TCB;
struct CommandLine {
char param1[NameDim], /* primo parametro */
param2[NameDim], /* secondo parametro */
flags[10] /* opzioni */
};
typedef struct CommandLine CommandLine;
Si faccia attenzione al fatto che il TCB viene utilizzato anche da alcune
routine scritte in Assembly, perciò se si modifica qualcosa nella
definizione del TCB si dovrà modificare anche queste routine.
In estrema sintesi i campi del TCB hanno il seguente significato:
SMI è l'identificatore di tipo del modulo che ha generato
il processo, mentre RMI è l'identificatore del tipo di processo
a cui appartiene il Thread. PR è la priorità corrente
del modulo, mentre ST_PR è la priorità di partenza
con la quale viene accodato il TCB. Stack, Heap e mem contengono
l'indirizzo di memoria rispettivamente dello Stack, dello Heap e della
zona dati accessibili al thread. PX indica se il thread va eseguito
in modo di esecuzione particolare; fun è un puntatore alla
prima locazione di memoria che viene eseguita dal Thread. Data serve
per sapere su che porta seriale lavorare, se eseguire in background
o in foreground e gestire eventuali errori. Command è
utilizzato per memorizzare eventuali parametri forniti con il comando in
linea ed interpretati dalla shell. BornTime registra l'istante nel
quale è stato accodato il TCB, questo dato è necessario per
poter implementare l'aging.
Lo stato della CPU al momento dell'interruzione del thread è
memorizzato nelle variabili SR, a[ ], d[ ] e PC. In queste variabili
viene copiato il contenuto dei vari registri della CPU nell'istante dell'interruzione.
SR contiene il registro di stato della CPU, in a[ ] vengono copiati i registri
indirizzi A0-A7, mentre in d[ ] ci sono i registri dati D0-D7. Infine il
program counter è salvato in PC.
L'ultimo campo è CP, che punta al prossimo elemento in
coda.
Lo schedulatore mantiene i TCB in una struttura a sette code con priorità
decrescente; l'ultima coda è utilizzata per mantenere i TCB liberi
(vedi fig. {codeTCB). I primi elementi di ciascuna coda sono raggiungibili
tramite un vettore di puntatori chiamato fipt, gli ultimi sono puntati
da un vettore chiamato lipt.
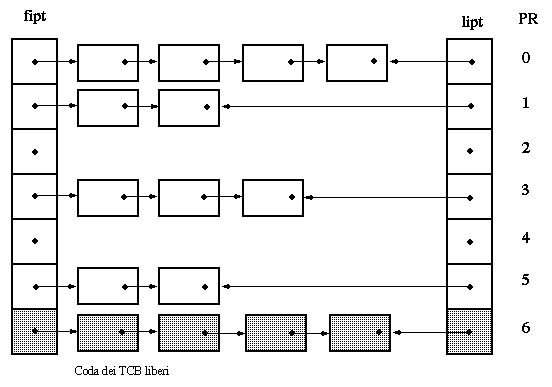 Figura 2.2: Code di priorità dei TCB
Figura 2.2: Code di priorità dei TCB
Lo schedulatore in determinati momenti scandisce dalla coda a priorità
più alta fino alla più bassa finché non trova un TCB
pronto per l'esecuzione.
| puntato da |
Descrizione |
| fipt[6] |
inutilizzato |
| fipt[i] |
in attesa di essere eseguito |
| savedTCB |
esecuzione in corso |
|
Tabella 2.1: Stati dei TCB
Per
evitare che Thread a bassa priorità non vengano eseguiti mai, si
attiva un meccanismo di aging, cioè dopo un certo tempo che
un TCB permane in una coda viene passato alla coda con priorità
immediatamente superiore come si vedrà più in dettaglio in
seguito. Il TCB del Thread mandato in esecuzione viene prelevato dalla
coda d'attesa e memorizzato da un apposito puntatore chiamato savedTCB.
Al termine dell'intervallo di tempo assegnato al Thread, il TCB viene posto
nella coda della priorità di partenza del Thread. Un Thread può
trovarsi in uno degli stati visualizzati nella tabella 2.1.
Gli interrupt provenienti dalle porte seriali, che corrispondono
ai terminali, vengono gestiti semplicemente utilizzando una tabella chiamata
itable. In questa tabella ogni interrupt causa la modifica
di un flag posto nella riga corrispondente all'interrupt
stesso. Le routine di input-output gestiranno questi interrupt
interrogando questa tabella.
Lo schedulatore ripete indefinitamente un ciclo
in cui viene attivata la funzione ServiceInterruptTable, che verifica
se è giunto un interrupt dalle porte seriali, e la funzione SetviceTaskQueue
che gestisce la lista dei TCB.
Schedulatore
{
ciclo {
se la tabella di interrupt non e' vuota
chiama la ServiceInterruptTable;
altrimenti
chiama la ServiceTaskQueue;
}
}
La funzione ServiceTaskQueue aggiorna la coda di attesa dei TCB provvedendo
per prima cosa al meccanismo di aging. In seguito preleva il TCB a priorità
più elevata e lo avvia all'esecuzione distinguendo i casi della
prima esecuzione (che avrà bisogno di allocare risorse) e della
ripresa dell'esecuzione (che dovrà ripristinare i registri allo
stato precedente all'interruzione).
ServiceTaskQueue (cmid)
/* aggiorna l'anzianita' dei thread e preleva il thread da eseguire */
{
operazioni di aging;
cerca il primo TCB disponibile;
se il TCB e' stato trovato {
preleva e salva il TCB;
aggiorna la coda;
se il modulo e' gia' stato eseguito
chiama RESTORE();
altrimenti
chiama EXE();
}
}
La sezione di codice che provvede all'aging si attiva solo ogni TstTime
istanti. Per ogni coda preleva il primo elemento e verifica se il tempo
d'attesa è superiore ad un limite memorizzato nella variabile AdvTime.
In caso affermativo pone il TCB prelevato nella coda a priorità
immediatamente superiore; altrimenti lo rimette nella stessa coda.
Aging
/* aumenta la priorita' dei thread in coda da piu' tempo */
{
Se sono trascorsi TstTime istanti
Per tutti i livelli di priorita' tranne il primo {
preleva il primo TCB se disponibile;
aggiorna i puntatori alla coda di priorita';
se il TCB e' in coda da almeno AdvTime {
incrementa la priorita' del TCB;
aggiorna il tempo del TCB;
}
accoda il TCB;
}
}
La funzione ServiceInterruptTable verifica se ci siano interrupt
della seriale, in caso affermativo avvia subito l'esecuzione della funzione
EXEINT la quale, a sua volta, avvia l'esecuzione del modulo che
serve le richieste associate a questi interrupt. Nella versione attuale
solo la shell svolge questo compito. Tuttavia questa struttura è
flessibile in quanto permette la creazione di nuove shell diverse.
bool ServiceInterruptTable (cmid)
/* esamina gli interrupt di sistema */
{
esamina la tabella degli interrupt;
se la tabella e' vuota
ritorna FALSO;
altrimenti {
imposta i dati in itcb;
chiama EXEINT(itcb,cmid);
ritorna VERO;
}
}
void EXEINT()
/* esegue un modulo senza attivare il timer */
{
se e' un modulo di sistema
esegui il modulo
altrimenti
chiama la ServiceERROR
}
Il Thread che viene prelevato dalla coda d'attesa dalla funzione ServiceTaskQueue
viene mandato in esecuzione per la prima volta tramite la funzione EXE.
Questa funzione dovrà distinguere una serie di casi:
-
Se il Thread va eseguito in foreground passa l'input al Thread.
-
Se il puntatore alla memoria dati e codice è nullo (cioè
si tratta del primo Thread di un processo) alloca una zona di memoria per
la regione dati e, se non è un modulo di sistema, per la regione
codici.
-
Alloca una regione Stack e se si esegue un modulo di sistema ponilo nel
Supervisor Stack Pointer (SSP), altrimenti mettilo nello User
Stack Pointer (USP).
-
Se è un'applicazione prepara i parametri formali sullo Stack.
-
Se non è un modulo di sistema passa al modo utente.
Una volta testati tutti questi parametri viene fatto partire il timer e
viene avviata l'esecuzione. Al termine dell'esecuzione vengono liberate
tutte le risorse utilizzate, compresa la memoria Heap eventualmente allocata.
void EXE()
/* avvia l'esecuzione di un thread per la prima volta */
{
alloca una zona di stack
se il puntatore alla zona dati e codice e' nullo
chiama il loader
se il processo non e' in background
manda l'input al processo
se il processo non e' di sistema {
passa in modalita' utente
prepara i parametri formali sullo stack
}
avvia il timer
avvia l'esecuzione
FreeMod /* libera le risorse occupate */
}
Quando il tempo assegnato per l'esecuzione
di un Thread è esaurito il timer invia un interrupt che attiva
la subroutine ContextSwitch. Questa subroutine, scritta in linguaggio
Assembly, memorizza il contenuto di tutti i registri nel TCB, disattiva
l'interrupt del timer, ripristina la priorità iniziale, mette il
TCB nella coda d'attesa e riprende l'esecuzione dello schedulatore. L'unico
registro per cui serve qualche cautela è lo Stack Pointer: a seconda
del modo operativo sarà il SSP o lo USP.
ContextSwitch
/* salva lo stato di un thread interrotto */
{
aggiorna la variabile tempo;
se il modulo e' terminato
disattiva l'interrupt in servizio;
altrimenti {
aggiorna SavedTCB con lo stato della CPU;
se thread eseguito in modo utente
copia lo USP (User Stack Pointer)
altrimenti
copia lo SSP (Supervisor Stack Pointer)
ripristina la priorita' iniziale (ST_PR);
accoda SavedTCB;
disattiva l'interrupt in servizio;
salta allo schedulatore;
}
}
L'operazione inversa viene fatta quando si riprende l'esecuzione di un
Thread che è già stato mandato in esecuzione. Ciò
viene svolto da un'altra subroutine scritta in Assembly: RESTORE,
la quale copia il valore di tutti i registri dal TCB (con la stessa cautela
nel distinguere tra il SSP e lo USP), attiva il timer e riavvia l'esecuzione
del Thread.
RESTORE
/* riprende l'esecuzione di un thread interrotto */
{
aggiorna i registri della CPU;
se thread eseguito in modo utente
ripristina lo USP (User Stack Pointer)
altrimenti
ripristina lo SSP (Supervisor Stack Pointer)
attiva il timer;
riprendi l'esecuzione del Thread;
}
Gli stati per cui può passare l'esecuzione di un Thread sono visualizzati
nella figura 2.3.
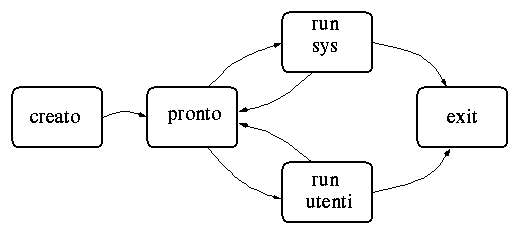 Figura 2.3: Le fasi nella schedulazione di un Thread
Figura 2.3: Le fasi nella schedulazione di un Thread
2.2 Operazioni sui processi
2.2.1 Creazione dei processi
Un processo può essere creato mediante un comando interpretato dalla
shell oppure tramite un'opportuna chiamata di sistema. In ogni caso si
passerà attraverso la funzione CallData o la sua versione
semplificata Call. Questa funzione preleva un TCB dalla coda dei
TCB liberi, tramite la funzione GetTCB, vi copia i parametri necessari
per l'esecuzione e lo inserisce nella coda con la priorità richiesta,
chiamando la funzione QueueTCB.
CallData (cmid,PX,PR,ID,Port,Data)
/* prepara il TCB per un nuovo processo */
{
chiama GetTCB;
aggiornamento del TCB ottenuto;
chiama QueueTCB;
}
La funzione GetTCB verifica che ci siano abbastanza TCB nella coda
dei TCB liberi (in questa coda deve rimanere sempre almeno un TCB in modo
da poter servire in ogni caso un eventuale errore). Se possibile, preleva
il primo TCB da questa coda, inizializza alcuni parametri del TCB e aggiorna
le variabili che tengono conto dei TCB attivi; infine restituisce un puntatore
al TCB prelevato.
TCB *GetTCB (cmid)
/* preleva un TCB dalla coda libera */
{
se ci sono almeno due TCB liberi e non sto servendo un errore {
prende il primo TCB dalla coda di TCB liberi;
aggiorna la coda di TCB liberi;
esamina la tabella dei TCB attivi;
}
se coda != vuota e nr. TCB attivi <= max {
aggiorna il TCB prelevato;
aggiorna la tabella dei TCB attivi;
aggiorna il nr. di TCB usati;
aggiorna eventualmente il max. nr. di TCB usati;
}
altrimenti
chiama la ServiceERROR;
ritorna il puntatore al TCB prelevato;
}
La funzione QueueTCB aggiorna alcuni parametri del TCB e chiama
la funzione InsertTCB. Questa funzione non fa altro che prelevare
la priorità dal campo PR del TCB e inserisce il TCB nella
coda con questa priorità.
InsertTCB (p)
/* inserisce un TCB nella lista d'attesa */
{
Prende la priorita' di p;
Accoda il TCB alla coda di priorita' prelevata;
}
QueueTCB (p,ID)
/* accoda un IMP nella lista d'attesa */
{
aggiorna SMI e RMI del TCB;
chiama InsertTCB(p);
aggiorna la tabella dei TCB attivi;
}
2.2.2 Cancellazione dei processi
La cancellazione di un processo può avvenire in vari modi: o per
terminazione del codice o a causa delle chiamate di sistema exit e kill.
Comunque viene attivata la funzione FreeMod. Questa funzione libera
tutte le risorse occupate dal processo che viene terminato: libera la regione
dati, codice e stack, libera tutti i blocchi di Heap eventualmente occupati.
Inoltre viene liberato il TCB cioè viene inserito nella coda dei
TCB liberi, viene stampato il prompt del sistema e infine si salta
all'inizio del ciclo dello schedulatore.
FreeMod
/* libera le risorse occupate da un processo che e' terminato */
{
libera la memoria dati e codice
libera la memoria heap e stack;
aggiorna la tabella degli stack;
stampa il prompt;
libera il TCB;
salta all'inizio del ciclo dello schedulatore;
}
2.3 Sincronizzazione
In un sistema con più processi eseguiti in parallelo o con il time
sharing ci possono essere dei conflitti nell'utilizzo di alcune risorse
o problemi di coordinazione tra i vari task. È utile che molte risorse
siano condivise, ad esempio il file system, ma spesso è necessario
che per un tempo limitato un processo o un thread ne abbia l'uso esclusivo.
Questa condizione viene chiamata mutua esclusione. Il thread che
non può essere interrotto per una certa parte del suo codice viene
chiamato corsa critica. La parte di codice che non può essere
interrotta si chiama sezione critica. Per evitare che le prestazioni
complessive del sistema decadano è necessario che le sezioni critiche
siano ridotte il più possibile.
Un problema classico è quello in cui un primo modulo genera
un secondo modulo e deve aspettare che il secondo termini un certo compito
per poter proseguire l'esecuzione. È chiaro che le situazioni di
questo tipo necessitano di un protocollo preciso di sincronizzazione.
Il metodo più semplice per risolvere i problemi di sincronizzazione
è costituito dai semafori binari. Si tratta di semafori che
si possono trovare solo in due stati: UP significa risorsa disponibile
e DOWN significa risorsa occupata, nel senso che si deve aspettare
per potervi accedere.
Il punto critico sta nel passaggio dallo stato UP allo stato
DOWN. Infatti questa operazione comporta due operazioni elementari:
prima si deve testare se il semaforo è libero, cioè nello
stato UP e poi si deve porre lo stato del semaforo DOWN.
Ma cosa succede se proprio in mezzo a queste due operazioni un interrupt
del timer fa scattare un context switch? In questo caso è
possibile che un altro thread trovi lo stesso semaforo UP e lo ponga
DOWN diventandone il possessore. Quando, più tardi, il primo
thread riprenderà l'esecuzione, sarà convinto che il semaforo
sia ancora libero, avendo fatto il test prima del context switch,
e lo porrà DOWN senza accorgersi che lo è già.
In questo caso l'utilizzo dei semafori binari sarebbe perfettamente inutile.
Questo problema trova soluzione in un'istruzione del processore che
testa e setta un semaforo in un'unica operazione indivisibile. Per i microprocessori
della famiglia Motorola 68000 questa operazione si chiama TAS (Test
and Set an Operand) e usa come parametro l'indirizzo effettivo
di un byte. Di questo byte si testa se tutti i bit sono posti a zero e
viene posto ad uno il bit 7 (il più significativo), pertanto il
valore esadecimale corrisponde a DOWN mentre corrisponde a UP.
Per utilizzare i semafori binari in questo sistema operativo sono disponibili
due funzioni: down ed up. La prima funzione utilizza l'istruzione
Assembly TAS; se quest'istruzione ha trovato il semaforo UP, allora
si salta alla fine della funzione, altrimenti si ritorna ad eseguire la
TAS finché non si trova il semaforo UP. Tuttavia lo stato
del semaforo può essere cambiato solo da un altro thread e quindi
finché non interviene l'interrupt del timer ad attivare un context
switch, non c'è speranza che il semaforo passi allo stato UP,
perciò tutto il tempo fino a questo evento sarebbe sprecato. Per
evitare questo inconveniente il context switch viene attivato tramite
una chiamata di sistema subito dopo che si è verificato che il semaforo
è già DOWN. Il ciclo verrà ripreso quando lo
schedulatore riavvierà l'esecuzione di questo thread.
void down(Semaforo)
/* occupa un semaforo binario */
bool *Semaforo;
{
#asm
movea.l (sp),a0 // mette l'indirizzo del semaforo in a0
Sem_wait:
tas (a0) // testa e setta il semaforo
beq Sem_end // esce dal ciclo se il semaforo era up
trap #14 // chiama il context switch
bra Sem_wait // entra in ciclo se il semaforo era down
Sem_end:
#endasm
}
La funzione up, invece, è molto più semplice, non
occorre fare nessun test, basta porre il semaforo UP.
void up (Semaforo)
/* libera un semaforo binario */
bool *Semaforo;
{
*Semaforo = FALSE;
}
Le due funzioni appena illustrate vengono utilizzate dal sistema operativo
per due scopi: per regolamentare l'accesso al file system e per realizzare
le funzioni di comunicazione nella libreria dei thread.
Per quanto riguarda l'accesso ai file ci troviamo di fronte al problema
classico dei lettori e scrittori. Un lettore per poter leggere un file
deve verificare che nessuno ci stia già scrivendo. Uno scrittore,
invece, deve accertarsi sia che nessuno stia leggendo il file sia che nessuno
ci stia scrivendo. Questo problema può essere risolto con l'uso
dei semafori. Per ogni file è necessario un semaforo binario per
proteggere la scrittura e un semaforo contatore per proteggere la
lettura. I semafori contatori sono dei semafori che contano il numero
di processi che stanno accedendo ad una determinata risorsa, in questo
caso un file. I semafori contatori possono essere realizzati mediante l'utilizzo
di una variabile globale utilizzata come contatore e da tre semafori binari
che ne proteggono l'accesso (cfr silberschatz).
In questo sistema, non essendo implementati i semafori contatori, è
stata adottata una versione semplificata del problema del lettore scrittore.
Viene utilizzato un unico semaforo binario che protegge dalla scrittura
tutto il disco. Pertanto risultano tutelati gli scrittori ma non i lettori;
infatti potrebbe capitare che uno scrittore modifichi un file letto solo
parzialmente da un lettore.
2.4 Thread
I thread sono flussi di controllo multipli che condividono uno stesso spazio
di indirizzamento; spesso sono chiamati processi a peso leggero (lightweight
process o LWP) e anche se questa definizione è un po' troppo drastica,
è un buon punto di partenza.
In Unix un processo comprende sia un programma in esecuzione sia una
serie di risorse come una tabella di descrittori di file e uno spazio di
indirizzi.
Esistono situazioni nelle quali sarebbe utile ammettere la condivisione
di risorse per consentirne poi l'accesso in concorrenza. L'utilizzo dei
thread consente un grado molto elevato di condivisione di risorse; infatti
tutti i thread all'interno di un processo condividono un'unica zona di
codice ed una sola zona dati e tutte le altre risorse fornite dal sistema
operativo; si hanno diversi fili (thread) di esecuzione in un solo processo.
Un processo tradizionale, o heavyweight, può essere visto come un
task dotato di un unico thread.
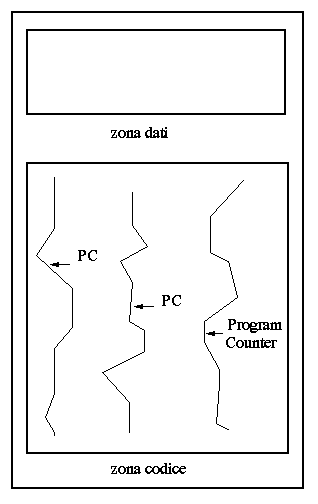 Figura 2.4 Thread multipli all'interno di un processo
Figura 2.4 Thread multipli all'interno di un processo
In sostanza ciascun thread è costituito da:
-
un identificatore di thread (TID)
-
un program counter (PC)
-
uno stack
-
uno stack pointer (SP)
-
un puntatore alla memoria condivisa con altri thread
-
un insieme di registri generici
-
un indicatore di priorità
Le zone condivise da tutti i thread all'interno di un processo (cioè
le risorse del task) sono le seguenti:
-
una tabella di descrittori dei file
-
un contatore di thread
-
una serie di semafori binari
-
una zona di codice
-
un nome mnemonico
-
un identificatore di processo (PID)
-
un identificatore del processo padre (PPID)
-
un puntatore alla zona di memoria heap
I vantaggi nell'utilizzo dei thread sono una maggior rapidità nella
creazione e nel passaggio di contesto e la possibilità di beneficiare
del time sharing anche all'interno di un processo. Ad esempio mentre un
thread è bloccato in attesa di un dato fornito da una risorsa lenta,
gli altri thread del processo possono proseguire nell'elaborazione.
Esistono diversi tipi di thread; in questo lavoro si è seguito,
pur con molte limitazioni, lo standard Posix. Non si può dire che
i thread siano conformi allo standard Posix (pthread) ma ne costituiscono
un sottoinsieme significativo.
I processi di Unix sono basati su un concetto di padre e figlio, ma
questa nozione è assente nella maggior parte dei sistemi dotati
di thread.
Dato che i thread condividono molte risorse, il problema del coordinamento
è cruciale. Per fare ciò molti sistemi usano mezzi appositi,
in particolare lo standard Posix prevede due tipi di strumenti di sincronizzazione.
Il primo metodo è costituito dai Mutex, ovvero semafori binari creati
e distrutti dinamicamente, che permettono ad un thread di bloccare una
o più risorse condivise finché si trova all'interno di una
sezione critica al termine della quale il Mutex verrà rilasciato.
Uno strumento un po' più sofisticato sono le Condition Variables:
dei semafori che usano un Mutex come protezione e che mantengono una lista
di thread che sono in attesa che sia soddisfatta una particolare condizione.
La cancellazione asincrona dei thread è, in generale, da evitarsi.
Infatti se un thread possiede un Mutex significa che, salvo abusi, si trova
in una sezione critica; se si cancella il thread non si potranno più
usare le risorse protette da quel semaforo bloccato, dato che solo il thread
possessore lo può sbloccare. Se invece si decidesse di sbloccare
il semaforo all'atto della cancellazione del thread che lo possiede, i
dati contenuti nelle risorse protette da quel semaforo probabilmente saranno
incoerenti e gli altri thread potranno dar luogo a comportamenti scorretti.
Riguardo la schedulazione esistono due politiche fondamentali (con
numerose varianti intermedie): a livello utente e a livello kernel. La
schedulazione a livello utente si ha quando il sistema assegna un quanto
di tempo ad un processo all'interno del quale il processo stesso provvederà
al passaggio di contesto fra i vari thread. Il kernel non sa nulla della
presenza dei thread; perciò se un thread facesse una chiamata di
sistema bloccante in attesa che si liberi una risorsa occupata anche tutti
gli altri thread del processo risulterebbero bloccati. Inoltre un unico
thread potrebbe monopolizzare tutti i quanti di tempo a disposizione del
processo lasciando gli altri thread inoperosi (starvation). La schedulazione
a livello kernel prevede che il kernel sia conscio della presenza di tutti
i thread e ne gestisca la schedulazione con le stesse regole con cui sono
schedulati i processi; in questo caso il passaggio di contesto è
più pesante ma consente l'esecuzione di un processo su più
processori contemporaneamente (su sistemi multiprocessore) ed evita che
un thread in attesa blocchi tutti gli altri thread associati.
Nella presente realizzazione la schedulazione è di tipo kernel.
Per tener conto dello stato di ciascun thread il sistema utilizza la struttura
chiamata TCB (Thread Control Block) già vista. All'interno
del TCB un unico campo a 32 bit tiene conto sia del TID (Thread ID) che
del PID (Process ID). Infatti i 24 bit bassi sono utilizzati per il PID
mentre gli 8 bit alti sono utilizzati per il TID, il primo thread di ogni
processo ha TID 0. Tuttavia l'utente non vedrà mai questo campo
unito: le routine di visualizzazione come la ps mostreranno sempre i due
campi separati.
2.4.1 Creazione dei Thread
Il primo thread di un processo inizia l'esecuzione di un programma partendo
dal main. In un punto qualsiasi dell'esecuzione può essere creato
un nuovo thread utilizzando la funzione di libreria thread_create.
A questa funzione si deve passare come parametro l'indirizzo di una funzione
all'interno del codice del processo dalla quale partirà l'esecuzione
del nuovo thread. Questa chiamata di sistema, se ha successo, restituisce
il TID del thread generato.
Per sapere quale thread si stia eseguendo basta chiamare la funzione
di libreria thread_self.
2.4.2 Cancellazione dei Thread
Per uscire da un thread ci sono due modi: o il thread stesso chiama la
funzione thread_exit o un altro thread chiama la thread_cancel.
Non è opportuno che un thread termini banalmente quando termina
l'esecuzione della funzione da cui è partito grazie alla thread_create.
È bene che prima della fine ci sia una chiamata alla funzione thread_exit.
La funzione thread_exit verifica che il thread non stia bloccando nessun
semaforo, nel caso ne trovi li sblocca. È responsabilità
del programmatore evitare che qualche semaforo protegga risorse con dati
incoerenti quando viene chiamata la thread_exit.
Per cancellare un thread diverso da quello in esecuzione, si utilizza
la funzione thread_cancel. Questa funzione verifica che il thread da cancellare
non possieda alcun mutex bloccato. Per tutti i mutex bloccati che vengono
trovati viene settato il bit che indica la mancata cancellazione del thread
a causa anche di quel mutex. Se non viene trovato nessun mutex, si procede
a cancellare il thread mediante la funzione kill con un parametro
particolare; infatti di norma la kill elimina un processo, cioè
tutti i thread e tutte le risorse del processo.
2.4.3 Comunicazione fra Thread (ITC)
In questa realizzazione per il coordinamento dei thread l'unico strumento
disponibile è il mutex. Nella sezione dati di ogni processo
vengono riservate 8 word (16 bit ciascuna) che possono ospitare
un massimo di 8 mutex. Qualora si richiedesse di creare un nono mutex la
richiesta non verrebbe soddisfatta e verrebbe restituito un messaggio di
errore (-1). Nella parte alta di ciascuna di queste word, viene memorizzato
il TID del possessore (che ha proprio 8 bit). Si noti che il possessore
del mutex non è il thread che l'ha creato ma quello che l'ha bloccato
per ultimo (chiamando la ``down''). La parte bassa serve per memorizzare
lo stato del semaforo: il bit più significativo serve per indicare
se il semaforo è bloccato o no (si noti che a causa dell'istruzione
assembly 68000 TAS il significato logico di questo bit è l'opposto
del significato fisico ovvero sarà 1 quando è occupato e
0 quando è libero), il bit meno significativo indica se il mutex
ha impedito la cancellazione del possessore, il secondo bit meno significativo
indica se il mutex è stato inizializzato oppure no, i rimanenti
bit sono riservati per usi futuri (si veda la figura 2.2).
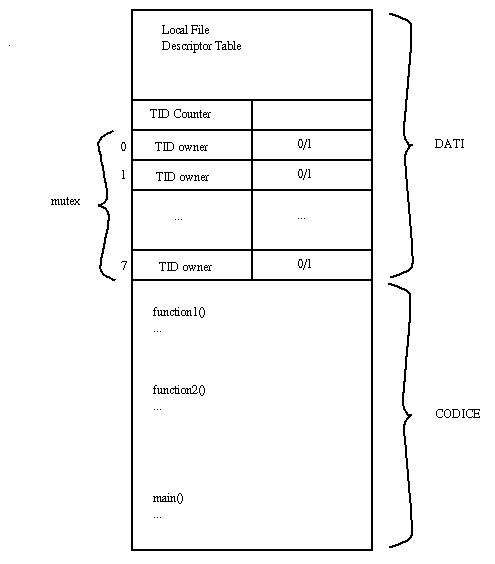 Figura 2.2: Utilizzo della Memoria da parte dei Thread
Figura 2.2: Utilizzo della Memoria da parte dei Thread
Per creare un mutex basta chiamare la thread_mutex_init; questa
funzione non fa altro che cercare un mutex inutilizzato e fornirne l'indice
al richiedente.
Per bloccare un mutex si utilizza la funzione thread_mutex_lock.
Questa funzione verifica che l'identificatore del mutex sia valido, poi
ne calcola l'indirizzo e lo passa alla funzione down la quale utilizza
l'istruzione TAS.
Sbloccare un semaforo è un'operazione abbastanza più
complicata del bloccaggio. Non solo si deve riconoscere se il thread che
fa la richiesta è il possessore di un effettivo mutex bloccato,
si deve anche verificare se il mutex ha impedito la cancellazione del possessore;
in questo caso si richiamerà la funzione di cancellazione (thread_cancel)
la quale verificherà di nuovo se ci sono o meno le condizioni per
la cancellazione del thread.
Per cancellare un mutex si chiama la funzione thread_mutex_destroy,
la quale verifica se il mutex esiste ed è sbloccato nel qual caso
effettua la cancellazione.
2.4.4 Applicazione
Come esempio per verificare il buon funzionamento di processi dotati di
thread è stato scelto il problema del produttore consumatore. Questo
problema trova grosso giovamento dall'utilizzo dei thread: in questo modo
si può condividere molto facilmente una zona di memoria il cui accesso
viene coordinato mediante un mutex.
Purtroppo le limitazioni del compilatore non hanno consentito di chiamare
le funzioni di libreria con gli stessi nomi definiti fino a qui e conformi
allo standard Posix. Quindi si veda le corrispondenze riportate nella tabella
2.2.
| Theos |
Standard |
| thcreate |
thread_create |
| thself |
thread_self |
| thmutexi |
thread_mutex_init |
| thlock |
thread_mutex_lock |
| thunlock |
thread_mutex_unlock |
| thmutexd |
thread_mutex_destroy |
| thexit |
thread_exit |
| thcancel |
thread_cancel |
|
Tabella 2.2: Funzioni della libreria dei thread
Il thread principale alloca una zona di memoria di 40 byte, setta i
puntatori all'inizio e alla fine di questa zona di memoria, crea un mutex
e lancia un thread che svolge il ruolo di produttore e un altro thread
che svolge il ruolo di consumatore, infine si blocca in un ciclo infinito.
Il thread produttore compie un ciclo infinito all'interno del quale
blocca il mutex, verifica se c'è posto per una nuova produzione,
scrive un dato (un numero progressivo a 8 bit), incrementa ciclicamente
il puntatore alla memoria e visualizza il dato scritto; infine sblocca
il mutex.
Il thread consumatore compie un ciclo infinito all'interno del quale
blocca il mutex, verifica se c'è almeno un dato da leggere, legge
un dato (un numero progressivo a 8 bit), incrementa ciclicamente il puntatore
alla memoria e visualizza il dato letto; infine sblocca il mutex.
/* problema del produttore consumatore */
int i, /* puntatore alla memoria usato dal produttore */
j, /* puntatore alla memoria usato dal consumatore */
k, /* puntatore alla prima locazione di memoria */
l; /* puntatore all'ultima locazione di memoria */
char c, /* contatore di dati presenti nel buffer */
m, /* puntatore al mutex */
t; /* TID */
/* ------------------------- */
/* thread produttore */
void prod()
char e;
{
e = 0;
while (1) { /* ciclo infinito */
thlock(m); /* blocca il mutex */
if (c<40) {
c = c+1;
*i = e; /* scrive il dato */
i = i+1;
if (i==l)
i = k;
write(" p ", e);
e = e+1;
}
thunlock(m); /* sblocca il mutex */
}
}
/* ------------------------- */
/* thread consumatore */
void cons()
{
while (1) { /* ciclo infinito */
thlock(m); /* blocca il mutex */
if (c) {
c = c-1;
write(" p ", *j);
j = j+1;
if (j==l)
j = k;
}
thunlock(m); /* sblocca il mutex */
}
}
/* ------------------------- */
/* thread principale */
void main()
{
malloc(i,40);
j = i;
k = i;
l = i+40;
thmutexi(m); /* inizializza il mutex */
thcreate(t, prod);
thcreate(t, cons);
while (1); /* ciclo infinito */
}