| tipo memoria | dati e codice | Stack | Heap |
| utilizzo | files - mutex | param form | gestito da processo |
| TID - codice | var loc | ||
| tipo | statico | dinamico | dinamico |
| dimensioni totali | 0.5 Mbyte | 1 Mbyte | 0.5 Mbyte |
| dimensioni blocco | variabili | 32 kbyte | 8 kbyte |
| numero blocchi | max 65 | 32 | max 64 |
| frammentazione | esterna | interna | interna |
| accesso | PC | SP | gestito da processo |
3.1 Memoria dati e codice
Per ogni processo viene allocata una zona di memoria dati composta da una tabella locale dei descrittori dei file aperti e da una zona per la gestione dei thread.Per i processi il cui codice non č incorporato nel sistema operativo (not embedded) viene allocata subito dopo la zona dati una zona codice. Questa zona č grande esattamente come il file eseguibile da cui viene copiato il codice.
L'indirizzo di memoria da cui parte l'esecuzione del codice viene scelto in modo imprevedibile dal loader del sistema operativo; perciň il codice dovrŕ essere rilocabile, cioč l'esecuzione deve essere indipendente dalla posizione in memoria occupata dal codice; quindi non ci possono essere riferimenti assoluti a locazioni di memoria e i salti, condizionati o no, dovranno essere tutti relativi al program counter (PC). Lo pseudocodice del loader chiarisce quanto illustrato finora:
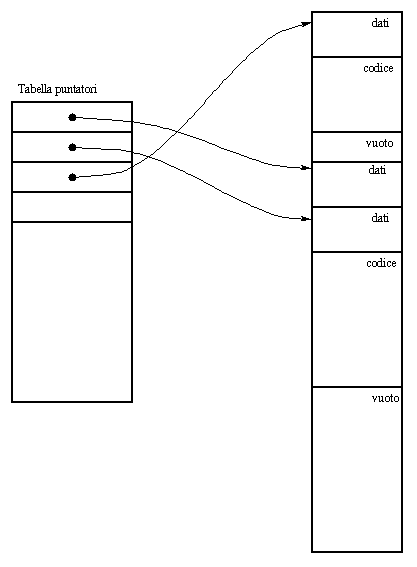
Figura 3.1: Memoria Dati e Codice
int Loader(FileN)
/* algoritmo di basso livello */
/* Carica un file eseguibile in memoria e inizializza la zona dati */
{
calcola lo spazio necessario
se !GetMem() /* alloca memoria */
esci
se il file esiste
copia il file nella posizione allocata
inizializza la zona dati
restituisci la locazione di memoria allocata
}
Il numero di zone di memoria dati e codice č limitato dal numero massimo di processi attivi contemporaneamente. Questo numero č fissato a 32 (ammesso che ogni processo abbia un solo thread). Le dimensioni della memoria dati e codice č fissa per ogni processo dall'inizio alla fine dell'esecuzione, perciň puň essere allocata esattamente la memoria che occorre senza frammentazione interna. Si puň avere, invece, frammentazione esterna, cioč uno spazio libero fra ciascuna zona allocata; in totale si possono avere al massimo 33 zone vuote (32+1). Č pertanto possibile indirizzare tutta la memoria dati e codice con una tabella.
L'allocazione č gestita con l'algoritmo first-fit, ovvero i dati e il codice vengono posti nella prima zona libera che si trova e che sia abbastanza grande per contenerli. Qualora non ce ne sia nessuna, anche se complessivamente nelle zone libere c'č abbastanza posto, l'esecuzione del processo viene abbandonata. Al momento dell'allocazione č normale che il blocco trovato sia piů grande di quanto richiesto, perciň questo blocco viene spezzato in due parti: nella prima vengono caricati il codice e i dati del processo mentre la seconda parte resta libera. Si noti che, mentre si possono avere due o piů zone occupate consecutive, non si possono avere due zone libere adiacenti perché vanno considerate, ovviamente, come un'unica zona libera formata dalla fusione delle due.
int GetMem(size)
/* algoritmo di basso livello */
/* Alloca una zona di memoria usando l'algoritmo del first fit */
{
ripeti per tutti i possibili spazi di memoria {
se lo spazio e' libero {
calcola la lunghezza del blocco
se lo spazio e' grande abbastanza {
se avanza spazio
dividi lo spazio in due
altrimenti
occupi tutto lo spazio
restituisci la locazione corrente
}
}
}
non c'e' spazio: restituisci codice d'errore
}
void FreeMem(beg)
/* algoritmo di basso livello */
/* libera una zona di memoria */
{
cerca la zona di memoria puntata da beg
verifica se e' preceduta o seguita da zone libere
libera la memoria
fondi le zone libere adiacenti
}
3.2 Memoria Stack
Lo stack č una memoria gestita a pila, cioč con un algoritmo di tipo lifo (last in first out). L'accesso avviene attraverso un registro apposito: lo Stack Pointer (SP), per la famiglia Motorola 68000 lo SP coincide con il registro A7; tuttavia si deve fare sempre attenzione al fatto che esistono due SP dei quali solo uno č attivo; per maggiori dettagli su questo punto si veda il capitolo 6 sulle chiamate di sistema.Esiste uno stack per ogni TCB e cioč per ogni thread, ciascuno stack č lungo 32 kbyte, ne consegue che non si avrŕ frammentazione esterna, ma una rilevante frammentazione interna.
Normalmente l'accesso avviene dall'alto verso il basso (cioč dalle locazioni con indirizzo maggiore a quelle con indirizzo minore) ma il sistema operativo non controlla che lo SP non vada oltre alla zona assegnata; questo compito č demandato al thread in esecuzione. Tuttavia per evitare che il codice divenga troppo pesante vengono utilizzati stack piuttosto lunghi (32 kbyte), molti thread resteranno cosě lontani dal limite che potranno fare a meno di controllarne il raggiungimento.
3.3 Memoria Heap
Lo heap č la zona di memoria (il "mucchio") da dove si attinge per soddisfare le chiamate di sistema alloc.
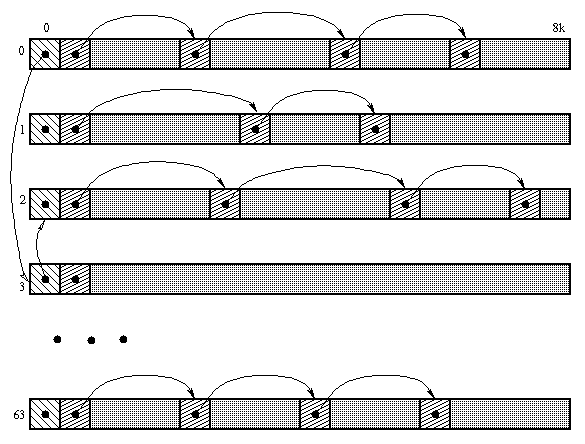
Figura 3.2: Architettura dello Heap
Le caratteristiche fondamentali sono la assoluta non prevedibilitŕ delle richieste e l'esigenza di distinguere le zone utilizzate da un processo rispetto a quelle utilizzate da un altro processo. In questo modo la procedura di kill puň facilmente deallocare tutte le zone di memoria utilizzate da un processo che venga terminato.
Ogni processo č dotato di un puntatore ad una zona di heap. Ciascuna zona di heap contiene un puntatore a una zona successiva in modo che si possa creare una lista concatenata unidirezionale. A ciascuna zona corrisponde un blocco di memoria di 8 kbyte.
All'interno di queste zone viene allocata la memoria richiesta formando un'ulteriore lista concatenata unidirezionale gestita con il meccanismo del first fit.
Si noti che č opportuno allocare sempre un numero pari di byte per permettere la lettura di word al M68000. Inoltre vengono allocati due byte in piů: i primi due byte della zona vengono utilizzati per scriverne la lunghezza, mentre il bit piů basso specifica se la zona č utilizzata o libera (in sostanza viene sommato 1 alla lunghezza delle zone libere). Dalla lunghezza viene ricavato l'indirizzo della prossima zona.
Per poter allocare una zona di memoria Heap l'unico modo č utilizzare la chiamata di sistema alloc; per liberarla si utilizza la chiamata free. Per maggiori dettagli si veda il paragrafo 6.2.3 "Chiamate di sistema per la gestione dello Heap"
![[Home]](home.gif) Back to Lucio's Home page.
Back to Lucio's Home page.