JOURNALİNG FİLE SYSTEM
Bu dosya sisteminin birçok dosya sistemiyle ilişiği vardır. Bu dosya sistemini anlatırken birçok dosy
a sistemine değineceğiz. Çünkü Journaling File System ‘i birçok işletim sisteminin güvenliğini sağlayan, onlara yeni ve daha güvenilir bir çalışma ortamı hazırlayan ...v.b işlemlerin gerçekleştirilmesini sağlayan bir dosyalama sistemidir. İlk olarak Linux Ext2fs file systeminin journaling file systemi ile olan ilgisini anlatmadan önce Ext2fs file systemine biraz değinmek istiyorum.
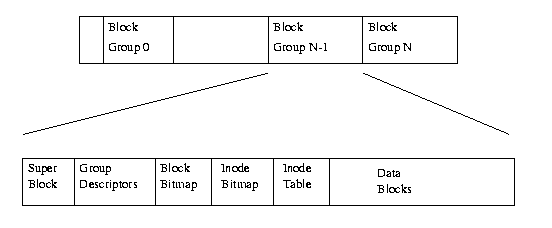
Figure1:physical layout of the EXT2 file system
EXT2 dosya sistemi linux için güçlü ve geniţletilebilir bir dosya sistemi
olarak planlanmıştır. Şimdiye dek linux topluluklarında en başarılı dosya sistemidir ve linux dağıtımlarının tümünün temelidir. EXT2 dosya sistemi diğer birçok dosya sistemi gibi dosyalarda tutulan verilerin veri bloklarında korunduğu dayanak noktasında kurulur.(Veri bloklarında saklanan,dosyalarda tutulan verilerin bulunduğu alana inşa edilir.) Yaratıldığı zaman (mke2fs kullanılarak) kurulan belirli bir EXT2 dosya sisteminin blok boyutunun , farklı EXT2 dosya sistemleri arasında uzunluğunun değişebilmesine rağmen bu veri bloklarının uzunlukları aynıdır. Her dosyanın boyutu blokların bir integral numarasına yuvarlanır. Eğer blok boyu 1024 byte ise 1025 boyutunda bir dosya iki 1024 lük bloğu işgal edecektir. Maalesef bu dosya başına bloğun yarısını boşuna harcadığınız anlamına gelir. Genellikle hesaplamada CPU kullanımını bellek ve disk kullanımına değişirsiniz. Bu durumda bir çok işletim sistemi ile birlikte , CPU üzerindeki iş yükünü azaltmak için diski oldukça verimsiz olarak kullanır. Veri tutan dosya sistemindeki blokların hepsinde değil ama birkaçı dosya sisteminin yapısını tarif eden bilgiler içermelidir. EXT inode veri yapısı ile sistemdeki her dosyayı tarif ederek dosya sistemi topolojisini tanımlar. Bir inode , hangi blokların dosya içindeki verinin dosyaya erişim hakları, dosyanın son değiştirilme zamanı ve dosya tipi kadarını işgal ettiğini tanımlar. EXT2 dosya sistemindeki her dosya tek bir inode tarafından tarif edilir ve her bir inode kendini tanımlayan tek ve ona özgü bir numaraya sahiptir. Dosya sisteminin tüm inodeları inode tablosunda saklanır. EXT2 dizinleri, dizin girişlerinin inodelarını gösteren pointerlar içeren son derece özel dosyalardır.(inodelar tarafından tarif edilen) Figure 1 bir blok yapılı cihazda bir dizi blok işgal eden EXT2 dosya sisteminin görüntüsünü gösterir. Blok cihazları sadece yazılabilen ve okunabilen bir dizi bloktur. Bir dosya sistemi , cihaz sürücüsünün işi olan,bir bloğun fiziksel medya üzerinde nereye yerleştirileceği ile ilgilenmez. Ne zaman olursa olsun bir dosya sistemi onu içeren blok cihazından veri veya bilgi okumaya ihtiyaç duyar, onu destekleyen cihaz sürücünün okuduğu gerekli blok numarasını ister. Ext2 dosya sistemi blok grupları içeren mantıksal bölüme ayırır. Her grup, bilgi ve veri blokları gibi gerçek dosya ve dizinleri tutarak dosya sisteminin bütünlüğünü için kritik bilgileri kopyalar. Bu kopyalama bir hasar meydana geldiğinde ve dosya sistemini yeniden elde etmek için gereklidir. Bu alt bölümler (subsection) her bloğun içeriğini daha ayrıntıyla tarif eder.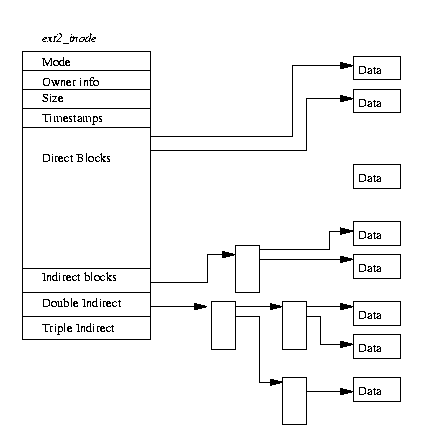
Figüre 2: EXT2 Inode
Ext2 dosya sisteminde,inode, blok oluşturmanın temelidir; dosya sistemindeki her dosya ve dizin bir ve sadece bir inode tarafından tanımlanır. Her Blok Grup için EXT2 inodeları , sistemin ,yerleştirilmiş veya yerleştirilmemiş inodeların tracklarını korumasını sağlayan bir bitmap ile birlikte inode tablosunda saklanır. Fig.2 ,aşağıdaki alanları içeren ve alanlarında diğer bilgilerinde bulunduğu EXT2 inode formatını gösterir.
Unutmamalısınız ki EXT2 inodeları özel cihaz dosyalarını tanımlayabilir. Bunlar gerçek dosyalar değildirler fakat cihazlara erişim için kullanılan programlardır.
Changing the Size of a File in an EXT2 File System
Dosya sisteminin en genel problemi bölünmeye olan eğilimidir. dosyaların verilerini tutan bloklar tüm dosya sistemi boyunca yayılır ve bu da bir dosyanın veri bloklarına sırasal olarak erişimi data blokları daha fazla parçalandıkça daha fazla verimsizleştirir. EXT2 dosya sistemi bir dosyanın yeni bloklarını fiziksel
olarak güncel data bloklarına yakın veya en azından aynı blok grubuna yerleştirmeye çalışarak bunun üstesinden gelmeye çalışır. Sadece bunlar olmadığı zaman veri bloklarını başka bir blok grubuna yerleştirir. Bir işlem bir dosyaya veri yazmaya kalkıştığında linux dosya sistemi verinin dosyanın son yerleştirildiği bloğun sonunda kesilip kesilmediğini kontrol eder. eğer öyleyse onu , bu dosya için yeni bir veri bloğuna yerleştirir. yerleştirme tamamlanana kadar işlem çalışamaz; yeni data bloğunu yerleştirmesi için dosya sistemini ve devam etmeden önce verinin kalan kısmı yazılmasını beklemelidir. EXT 2 blok yerleştirme rutinin ilk yapacağı şey bu dosya sistemi için EXT2 superbloğunu kilitlemektir. yerleştirme ve kaldırma superblok içindeki alanları değiştirir, ve linux dosya sistemi aynı zamanda birden çok dosyanın bunu yapmasına izin vermez Eğer başka bir process daha fazla yerleştirmek isterse ,bu processin bitmesini beklemek zorundadır. Superblok bekleyen processler çalışamaz ve kullanıcı tarafından superbloğun kontrolü bırakılana kadar askıya alınırlar. Superbloğa erişim verilir ve temel hizmet sağlanır ve bir defa bir process superbloğu kontrolü altına aldıktan sonra onun kontrolünü işi bitene kadar elinde tutar. Superblok kilitliyken, process bu dosya sistemin de kalan yeterli boş blok olup olmadığını kontrol eder. Eğer yeterli blok yoksa bu yerleşim girişimi başarısızlığa uğrayacaktır ve process bu dosya sisteminin superbloğunun kontrolünü bırakacaktır. Eğer dosya sisteminde yeterli blok varsa process birine yerleşmeyi deneyecektir. Eğer EXT2 dosya sistemi veri bloklarını önyerleştirme için kurmuşsa bunlardan birini alabilir önyerleştirmeli bloklar zaten yoktur,onlar sadece yerleştirilmiş blok bitmaplerinde rezerve edilmişlerdir. Yeni bir veri bloğu yerleştirmek için uğraştığımız dosyayı gösteren VFS inodu, ilk yerleştirilen veri bloğunun blok numarasının ve kaç tane olduğunu tutan prealloc_block ve prealloc_count adlı iki özel EXT2 alanı vardır.Eğer hiç önyerleştirilmiş blok yoksa veya blok önyerleştirilmesi yapılamıyorsa, EXT2 dosya sistemi yeni bir blok yerleştirmelidir. EXT2 dosya sistemi ilk olarak dosyadaki son veri bloğundan sonraki veri bloğunun boş olup olmadığına bakar. Mantıksal olarak, en verimli bloğa yerleştirmek, sıralı erişimi hızl
andırır. . Eğer bu blok boş değilse, araştırma genişletilir ve 64 bloklu ideal bir data bloğu aranır.Bu blok ideal olmamasına rağmen bu dosyaya ait diğer veri bloklarına oldukça yakın ve aynı blok grubundadır. Blok boş değilse, process boş blok bulana kadar diğer tüm blok gruplarına bakmaya başlar. Blok yerleştirme kodu blok gruplarından birinde sekiz boş veri blok clusterı (kümesi) arar. Eğer sekizini bir arada bulamazsa daha azına yerleştirecektir. Eğer blok önyerleştirme istenilen ve uygun şekilde ise prealloc_block ve prealloc_count update edilecektir. Boş bloğu nerede bulursa bulsun blok yerleştirme kodu blok gruplarının blok bitmapini update eder ve buffer cache' ine bir veri bufferı yerleştirir. O data bufferı, yerleştirilen bloğun blok numarası ve dosya sisteminin desteklediği cihaz tanımlayıcı tarafından tek olarak tanımlanır. Veri bufferda zero’d dir ve buffer ,içeriği daha fiziksel diske yazılmadığını gösteren dirty olarak işaretlenir. Sonuç olarak superblok kendini değiştirildiğini ve kilidinin kaldırıldığını gösteren dirty olarak işaretler. Eğer superbloğu bekleyen processler varsa sıradaki ilkinin çalışmasına izin verilir ve dosya işlemleri için özel superblok kontrolü sağlanır.İşlem datası yeni data bloğuna yazılır ve eğer data bloğu doluysa tüm işlem tekrarlanır ve diğer data bloğuna yerleştirilir.
JOURNALING THE LINUX Ext2fs FILE SYSTEM
Dosya sistemleri modern işletim sistemlerinin merkezi kısımlarıdır ve fazlasıyla hızlı ve güvenilir olmaları beklenir. Bununla birlikte problemler oluşur ve makineler donanım, yazılım sorunları veya güç yetmemesi se
bebiyle işlemez hale gelirler. Beklenmedik bir yeniden başlatma işlemi sonrasında, sistemin dosyalama sistemini uygun bir alana alması işlemi bir hayli zaman alabilir. Disk boyutu büyüdükçe bu bekleme zamanı büyük bir problem halini alır. Diskin taranması, kontrol edilmesi, temizlenmesi bir saatten fazla vakit alır. Her ne kadar disk hızları her geçen gün artsa da, diskin müthiş kapasitesi yanında bu hız ihmal edilebilir düzeydedir. Ne yazık ki, iki kat daha büyük bir disk, standart kurtarma teknikleri kullanıldığında iki kat daha fazla kurtarma zamanına ihtiyaç duyar. Sistem kullanımının hayati önm taşıdığı yerlerde bu zaman paylaşılamaz bir zamandır. Bu yüzden makine her açıldığında pahalı bir kurtarma aşamasına gerek duymayacak mekanizmalar gereklidir.DOSYA SİSTEMİ NEDİR?
Kullanım açısından bakıldığında bir dosya sistemine neden ihtiyaç duyulur? Dosya sisteminin hizmet verdiği işletim sisteminin, bize zorla kabul ettirdiği bir takım ihtiyaçları bulunur. Bir dosya sisteminin uygulamada karşılaşılan yüzü, tek kullanıcılı işletim sistemlerinin dosya isimlerini kesin kurallara bağlamış olması ve farklı özelliklere sahip dosyaların özel bir yolla iletişim kurmalarıdır. Bununla birlikte, bir dosya
sisteminin, zorunlu olmayan ve kullancıya belirli özgürlükler sunarak tasarlama yapmasını sağlayan özel yanları vardır. Verinin disk üzerideki görüntüsü (veya yerel bir sistem değilse ağ protokolünde); tampon bellekleme, disk giriş-çıkış işlemlerini düzenlemekte kullanılan algoritmalar vs. dosya sisteminin uygulama arabirimi çiğnenmeden değiştirilebilecek şeylerdir. Bir dizayn tipni diğerlerine tercih etmemiz için birkaç sebep vardır. Daha eski dosya sistemleriyle uyumluluk (örneğin Linux, bilinen DOS dosya sistemi standartı üzerine getirdiği POSIX dosya sistemi standartı ile UMSDOS kullanımına olanak verir.) Linux üzerinde, uzun dosya kurtarma zamanlarını incelerken aklımızda tutmamız gereken birkaç nokta var:
DOSYA SİSTEMİNİN GÜVENİLİRLİĞİ
Dosya sistemi güvenilirliğinden bahsederken birkaç noktadan bahsedilmelidir.
EXİSTING IMPLEMENTATION
(ŞU ANKİ MEVCUT GERÇEKLEME )
Linux ext2fs dosya sistemi koruyucu fakat re-covery sunar ama non-atomiktir(atomik değildir) ve tahmin edilemez(unpredictible). Tahmin edilebilirlik ilk başta gerektiğinden daha komplex bir yapıdır. Bir bozulmadan sonra sistemin diskteki tamamlanmamış bir durumunu temsil eden bir tutarsızlık ile karşılaştığı zamanne yapmaya çalıştığını bulmak zorundadır. Genel olarak bu file systeminin yazmalarını tek bir update o işlemi diskteki birçok bl
oğu değiştirdiği zamantahmin edilebilir şekilde yazmasını gerektirir. Diskyazmaları arasında bu yapmanın çok yolu vardır. En basiti istemi device drivere’ a sonrakini kabul etmeden önceki yazmanın tamamlanması ki bu “synchronous metadata update” yaklaşımıdır. Bu ilk olarak 4.2BSD de ortaya çıkan ve takiben Unix sistemlerini esinlendiren BSD Fast File System[1] tarafından ele alınan yakalaşımdır. Bununla birlikte synchronous metadata update’ in büyük bir dezavantajı performansıdır. Eğer file system işlemi bizim disk IO ‘ a sunmuş ve tamamlanmasını istiyorsa çoklu File systemi update ‘lerini tek bir disk yazımına toplayamayız. Örneğin; disk üzerinde aynı directory bloğunda bir dizina directory girişi yaparsak synchronous update’ler bu bloğu diske kaydetmek için 12 kez ayrı ayrı yazma gerektirir. Bu performans probleminin çözüm yolları var . Bu yolu bellekteki disk bufferlarının arasındaki istemi gerçeklemeyi tamamlamak için IO ‘yu beklemeden disk yazımlarını istemek ve datayı yazmak için geriye gittiğimizde, kendisinden önce gelemler güvenli şekilde yerleştirilmeden verinin yazılmamasını garantilemek ister “deferred ordered write” tekniği. Defered Ordered Write (geciktirilmiş yazma istemi ) nin bir komplikasyonu cache edilen bufferlar arasında karşılıklı bağımlılık durumuna girmek kolaydır. Mesela eğer 2 directory ‘ den birinci directory yeniden adlandırmak istersek 2 directory bloğunu birbirine bağlı şekilde durumu sonuçlandırırız. Hiçbir dosya diğeri diskte olmadan yazılamaz. Ganger’ in “Soft Updates” (Yumuşak Update) mekanizması [2] bu problemi , eğer bufferdaki bilgileri diske yazmak istediğimiz zaman hala bağımlılıklar varsa onları seçici olarak geri alarak açıkça çözer. Bütün bağımlılıkları ortadan kalktığı zaman eksik data yerleştirir. Bu bize karşılıklı bağımlılıklar olduğu zaman bufferları seçtiğimiz sırada diske yazma imkanı verir. Soft mekanizması FreeBSD tarafından adapte edildi ve sonraki ana kernel veriyonlarında kullanıma hazır olacak. Bununla birlikte bütün bu yaklaşımlar ortak bir problemi paylaşırlar. File System işlemi sırasında diskin her zaman tahmin edilebilir ( predictible) durumda olmasını garanti etmesine rağmen , recovery işlemi herhangi bir tamamlanmayan işlemi düzeltmek için bütün diski taramak zorundadır. Yine de File System Recovery ‘i , güvenilirlik (reliobility) ve tahmin edilebilirlik ( predictability) den feda etmeden hızlandırılabilir. Bu tipik olarak File System Update’in atomik olarak tamamlanmasını garanti eden dosya sistemleri tarafından yapıldı. (Böyle sistemlerde tek bir File System Update’ i transaction olarak adlandırılır) .Atomik update’ lerinin temel prensibi, File System tamamen yeni bir veri yığınını (gurubunu ) diske yazılabilir ama bu update’ ler disk üzerindeki Find, Commit Update’i yapılmazsa etki etmez . Eğer Commit diske tek bir blok yazımını içeriyorsa bozulma sadece 2 şeye yol açar ; ya commit kayıdı diske yazılmıştır ki bütün commit edilen file system operasyonları diskteki tüm ve tutarklı varsayılabilir, yada commit kayıdı kayıptır ki bu durumda bozulma anında ki , kısmi commit edilmeyen update’ lere bağlı olarak file system update’ inin commit zamanına kadar ki eski ve yeni dataları ve update edilen kayıtların yeni içeriklerini disk üzerinde bir yerde saklamayı gerektirir.
Bunu yapmanın birkaç yolu vardır.Bu durumlarda file systemler update edilen datanın eski kayıtları ile yeni kopyalarının farklı yerlerde saklarlar ve sonuçta update ‘ler commit edildiği zaman eski yer yeniden kullanılır.
PROJE DURUMU VE GELECEĞİN İŞİ
(Project Status and Future Work)
Bu hala gelişmekte olan bir iştir. Baştaki yürütmenin dizaynı hem sabittir hem de basittir ve biz yürütmeyi tamamlamak icin gerekli olan dizaynda büyük düzeltmeler ummayız.Yukarıda tanımlanmış olan dizayn göreceli olarak doğrudur ve bu dizayn bilgisayarın habersiz kapatılmasından sonra file systemlerin kendini toplaması için,buffer ve transactionlar (aktarma) arasındaki birliği ve journal dosyasının yonet
imini elinde bulundurmak için bir koddan var olan diğer ext2fs koda en az degisikliği gerekli bulacaktir. Test edilecek sabit bir codebase ‘imiz olduğu zaman temel dizaynı genişletebileceğimiz çok mümkün talimatlar vardır. Burada önemli olan filesystem performansının ayarı olacaktır. Bu journaling sistemdeki commit frekansları ve kütük boyutları gibi rastgele(keyfi) parametrelerin etkisini çalıştırmak için bizi gerekli bulacaktir. Eğer performans her zaman kendilerini öne sürecek olan dizaynı birkaç mümkün genişletme ve sistemin dizaynı için yapılan degişiklikler içerisinde düzeltilebilirse o aynı zamanda bottle-necksin ‘in çalişmasını icap ettirecek. Çalışmanın bir alanı güncellemenin journal guncellemesini sıkıştırmasını göz önünde bulundurmalıdır. Blok içerisinde yalnız tek bir bit degiştirilmiş olsa bile akış şeması journal’ a bütün meta-data bloklarını yazmak için bizi gerekli bulur. Biz bazı güncellemeleri onun tamamının içindeki bufferi kütüklemek yerine buffer içindeki yalnız değiştirilecek değerleri kayıt ederek çok basit bir şekilde sıkıştırabiliriz. Bununla beraber bu büyük bir performans yararını sunmuş olsa da bu şu an temiz değildir. Akış şeması bellekten belleğe fazla yazıları kopyalamayı hiç gerekli bulmaz ki bu da BUS kullanımını ve CPU içerisindekileri kullanmada büyük bir performans sağlar. Bütün bufferlara yazılmaktan doğan I/O lar ucuzdur ve birbiri ardınadır ve modern disklerdeki I/O lar CPU veya cashe uğramadan ana memory den doğrudan disk kontrole transfer edilir. Genişletmenin diğer önemli alanı hızlı NFS serverların desteğidir. Eğer bir server çökerse NFS dizayn alıcıya düzeltmesi için izin verir: eğer server reboot olursa alıcı tekrar bağlantı kuracak. Eğer bir çökme meydana gelirse diske güvenli olarak yazılmamış olan serverın alıcı datası kaybolmuş olabilir ve bundan dolayı NFS serverların bir alıcının filesystem talebini tamamlamasınıve bunu onaylamamasını gerekli bulur taa ki bu taleb server diske ulaşana kadar. Bu destekleme icin genel amaçli file systemler için yakışık olmayan bir durumdur. Bir NFS serverın performansı genellikle alıcının istediği yanıtlama zamanıyla ölçülüdür ve bu yanıtlamalar diske aynı anda tesadüf edilmesi için file system güncelleştirilmesini beklemek zorundaysa bütün performans disk üzerindeki file system güncelleştirmesinin belirsizliğiyle limitlenir. Bu, bir file systemin kullanılanlarıyla arasıdaki farkı bulmak için disk güncelleştirmesi değil cash güncelleştirilmesinin LATENCY(belirsizlik) şartıyla ölçülen performansta karşılaştırır. Bu problemi adreslemek için özel dizayn edilmiş file systemler vardır. WAFL[6] disk üzerinde bir yere güncelleştirmeyi(update) yazabilen bir transactional tree-baseddir, fakat CALAVERAS filesystem[7] yukarıdaki örnekte olduğu gibi bir journalin kullanımı içinde aynı şeyi yapar. Fark Calaveras filesystem talebini(request) her uygulama için journal’ a ayrılmış bir transaction‘ı kütüklere kaydeder, böylece disk üzerindeki ferdi güncelleştirmelerin tamamlanması çabuksa mümkün olur. Önerilen ext2fs journaling’ deki commitlerin toplanması bir an önce çeşitli güncelleştirilmelerin commit edilmesi uğruna hızlı commiti feda eder ki böylece belirsizlik pahasina baştan başa kazanir. (disk uzerindeki belirsizlik cache nin etkisiyle uygulamalardan saklanır.) Bir NFS server üzerinde kullanmak için çok uygun yapılmalarının ext2fs journal ‘daki iki yolu küçük transactionlarin kullanılmış olması ve file datanın logging (kütüğünün) inin meta-data kadar iyi olmasıdır. Transactionların ölçülerindeki ayarının journal’a commit edilmesiyle biz ayrı güncelleştirmeleri commit etmek için dolanımını düzeltebiliriz. NFS mümkün olan en hızlı şekilde diske commit edileni yazan bu datayı gerekli bulur, ve normal file datanın yazılarını örtmek için journal file‘i genişletmemiz için hiç sebep yoktur. Sonuç olarak birkaç farklı file system arasında tek bir jounal’i ayırmaktan bizi engelleyen bu semadaki hiçbirşeyi not almaya değmez. O istenileni bütünüyle saklayan ayri bir disk üzerinde bir kütüğe journal edilmiş olan çok yönlü file systeme izin vermek için ekstra bir işi gerekli bulur ve bu deneyimli ağır yüklemeler getiren birçok journal file system’lerin olduğu yeri anlamlı bir performans yardımı verir. Ayrı journal disk tamamıyla sıralı olarak yazılmıştır ve ana file system disk üzerindeki bant uzunluğunun kullanışlılığını yaralamadan baştan sona yüksek bir destek olabilir.
LOGGING AND JOURNALING FILE SYSTEMS
Bu dosyalar icin log daki dosyalar icin logging duzeltmeler yaparak ve log lari checkpoint ederek dosya sistemlerinin update i icin farkli bir yaklasim getiriyor. Okuma kabaca, dosyalari direct olarak update eden geleneksel file systemleri kadar hizli.Yazma ise update ler sadece log a eklendigi icin daha hizli. Bunların hepsi kullanıcıya açıktır. It is in reliability ve particularlyinchecking file system integrity that these file systems really shine. Son kontrolünden önce veriden dolayı, sadece sisteme girişin kontrol edildiği iyi biliniyorsa ve bu genel dosya sistemlerinden daha hızlıdır.
Dikkat edin, logging dosya sistemleri değişikliklerin izini veri ve inode’larda tutar iken , journalling dosya sistemleri izleri sadece inode değişikliklerinde tutar. Linux dosya sistemleri içinde seçkin bir yere sahiptir,ama henüz hiç biri üretim kalitesinde değildir. Bazıları aynı zamanda devam etmektedir.
Daha öncede belittiğim gibi Journaling File Systeminin bir çok dosyalama sistemi ile bir ilişiği vardır. Şimdi de journaling file systeminin XFS ile olna ilişiğine bir göz atalım.
XFS ve JOURNALİNG FİLE SYSTEM
Bazı Journal kaideleri file systemi seri halinde okunacaksa ;
Meta dataların kütük dosyası ve kullanıcı dataları Journaling file systemi ile gönderilerek uygulanır. NTFS, örneğin sadece meta datanın kütük dosyasını tekrar içingönderirseniz kullanıcı Journal’ i yazmak için gönderemez. Bunun anlamı , tekrar sırasında kullanıcı datalarını kaybedebilirsiniz. Eğer XFS ‘ e sadece Journal meta datalarını yazıyorsanız ve kullanıcı olmaya
n data, ileri sürüldüğü gibi , o zaman teknik düzeltmeleri seri halde okuyamazsınız. Bununla birlikte bunun anlamı XFS için Journaling file systeminde “TRUE” değildir. Çünkü tekrarlanırsa kullanıcı datalarını kaybedebilirsiniz ve faydalar sağlamak açısından Journaling “fsck” ‘ dan sonra çalışan etkili bir sistemden daha etkili değildir. Elbetteki bu durum XFS ‘ nin NTFS ‘ den daha iyi olduğunu göstermez.XFS ve Journaling dosya sistemleri;
Journaling ile systemin de adlandırılan benzer işlemler benzer adlandırmalar “ clust
ering ”den farklı olmaz ve bazı file system ler gerçek Journalled değildir. Fakat bu adlandırmalar yer belirlemek için tekrar uygulanır. Daha önceki düşünceler NTFS ‘ nin XFS ‘ ye çok benzer göründüğü şeklindedir. Linux ‘un içinde XFS ‘in içerdiği açık, faydalıve kabiliyetli bir yer oluşturur hatta bu düşünce Journaling file system ‘de doğru kabul edilmiyor. Kullanıcı kütüklerin yazımı ve listelemesine izin vermesi kullanıcının birçok şeyi üzerine almasında Journaling kullanılır ve bu da kütük dos
ya sisteminin temelidir.XFS kütük içine data yerleştirmez. Kütük içindeki meta data işlemleri track’ larda tutulur. XFS’ nin birinci hedefi başlangıçta ‘fsck’ nın ihtiyaçlarını gidermektir. Büyük bir dosya sistemi olduğu zaman bu çok büyük bir dağıtım gerektirir. Çok büyük dosya sistemlerinden ‘fsck’ almak ise çok uzun bir zaman gerektirir. Eğer data kütüklerindeki sistem dosyalarına bakıyorsak XFS bizim için bir çözüm değildir. XFS sistemi aynı zamanda O_SYNC ile bir dosyaya yazmamıza iz
in verir. Bu da yazmaya geri döndüğümüzde disk üzerindeki dataları garanti altına almamızı sağlar. XFS ‘ de çok fazla kütük ve journaling olabilir. Başka bir deyişle XFS data kütüğü değildir. XFS ‘nin bütün diğer adres görünüşleri NTFS ‘ den daha kötüdür.Sizin data alanlarınızın Journal sisteminize bağlı olarak pek çok alternatif vardır. Eğer sadece iyileştirme amacıyla data alanlarında track değişimlerini istiyorsanız SNDJRNE komutunu kullanırız. (APİ ‘yle aynı işlevde ) her ne zaman data alanını değiştirecekseniz iyileştirme durumlarında data alanlarının kesilmesinden önceki son değerini bulmak için DSPJRNE '‘yi kullanabiliriz. Eğer remote sistemi yansıtma değişiklikleri gösteriyorsanız, yansıtma paketlerinin çoğu data alanlarının polling me
todu yoluyla kullanabiliriz. Eğer remote sistemi data alanlarının geçerli değerinden korumak için gösteriyorsanız *DDM dataalanı tipini göz önüne alamalısınız. DDM data alanı remote sistemdeki uygulama programlarının kullandığı hiçbir bilginin olmadığı dataların bir adım dosyasında çalışmasıdır. Güncelleme ve kilitleme zorlakabul ettirilir. Eğer sadece data alanlarının kullsanımında track’ları kullanıyorsanız, data alanlarında activating object auditing durumunu göz önüne almalısınız.
JOURNALİNG SİSTEMİN KAYIT GÜVENLİK KULLANICI MODÜLÜ
(Records Maintenance Journaling System User – ID Module)
User- ID modülü kayıt güvenlik sistemine giren kullanıcıların tanıtıcı bilgilerini tutar. Bu noktada sadece Net- Gateway tututabilir. Eğer diğerleride (pathler) ortaya çıkarsa onlardan tutulur. Module Records Maintenance tarafından kullanılan kullanıcı tanımlama dosyasını oluşturur.
ID Modülü şunları içerir:
Kullanıcı tanımlama modülü bütün RM I/O modüller tarafından çağrılır.
Tanımlanmış modüller şunları içerirler:
Her çağrıldığında kullanıcı ID modülü ;
Modül ya iş programı çağırır yada CISC ortamından çalışma anında bilgileri ele geçirir.
Her I/ O modülü kullanıcı ID modülünü iş listeleri için çağırır. İş tanımlama listesi korunabilir olmalıdır. Bu liste dinamik olmalı ve çeşitli guruplar tarafında erişilebilir olmalıdır. RM sistemi içindeki Net- Gateway pek çok çeşit client/server ortamlarını destekler. Böylece koddan bağımsız güvenli procedure oluşturulmuş olacaktır. SSG2 , Demoxpnd dosyasını güncelleyen işleri başlatan b
ir Net-Gateway ‘ dir. Bu I/O modülünü kullanmaz. Aktüel mekanizma müzakere edilebilir ve oluşturulamaz. Bu bir zaman periyodunda kolayca güncellenmelidir. Merkezi olarak kontol edilmelidir ve zıt erişimlere karşı korunabilmelidir. Güzel bir kullanıcı arayüzüne gerek yoktur.
JOURNALİNG FİLE SYSTEM ‘DE KULLANICI TANIMLAMA DOSYASI
(Error handling journaling file system )
Kullanıcı ID modülü kayıtları I/O modülden VSAM dosyasına yazar.
Kayıtlar:
Bu bilgileri içeren listeler Record Maintenence Journal Creation Job ‘un gereksinimlerine göre dahada büyüyebilir. Dosya her akţam RM create job taraf
ından korunur ve yedekleme işi tanımlanır.
SONUÇ(CONCLUSIONS)
Bu kağıtta hazırlanmış olan file system dizaynı linux üzerinde var olan ext2fs file system üzerinde önemli avantajlar sağlar. Bir çökmeden sonra çok öncelikli ve hızlı bir ţekilde tekrar örten , yaratarak güvenilirliğini arttırmayı sunan bir dosya sistemidir ve normal operasyon süresince performansın düţmesi büyük bir kaosa neden olmaz. Gün gün performans üstünde çok önemli etki kernel ile destekli ertelenmiţ data geri yazılımına izin vermekten ziyede journal’a oluţturulan commit için hızlıca diske eriţim sırasında oluţturulan yeni dosyalar olacak. Bu on/tmp file system ‘lerin uygunsuz kullanımı bu jounaling file systemi oluţturur. Dizayn var olan ext2fs codebase’e enaz değiţikliği gerekli bulur: Fonksiyonellik bufferların arayüzlerindeki I/O transfer örneği içerisindeki ana ext2fs koduna arayüz olacak yeni journaling mekanizmasıyla sağlanır. Sonuç olarak disk dosya sistem planı üzerinde var olan ext2fs nin üstünde dizaynın inţasını sundum ve var olan bir ext2fs dosya sistemine bir transfer journal’i eklemek imkanlı olacaktir ki bu da dosya sistemine tekrar format atmaksızın yeni özelliklerin avantajını alır.