


La interfaz CGI
1. Presentación de la interfaz
2. Fundamentos
2.1. Invocación de un script CGI
2.2. Variables de entorno primarias
2.3. Variables de entorno secundarias
2.4. Variables dependientes del protocolo HTTP
2.5. Resultado de la ejecución de un CGI
2.5.1. Scripts con salida PH
2.5.2. Scripts con salida NPH
3. Procesamiento de forms
3.1. Invocación de scripts para el procesamiento de forms
3.1.1. Descodificación de la información procedente de un form
3.2. Uso de GET y POST
1. Presentación de la interfaz
CGI (Common Gateway Interface) es una interfaz entre programas de aplicación y servicios de información. Hasta el momento, se ha utilizado únicamente como pasarela hacia servidores WWW que utilizan el protocolo HTTP. Sin embargo, ha sido planteada como pasarela independiente del servicio y de la aplicación.
Un documento HTML, es algo estático, permanente, lo que no se adecúa a los requisitos de interactividad necesarios en una aplicación del estilo de la tele-ducación, como el acceso a información en constante actualización, consulta a bases de datos o seguimiento, control o recuperación de resultados de un determinado proceso. En este tipo de aplicaciones, es necesario acceder a una información que se está generando "en tiempo real". Así pues, es necesario contar con algún tipo de pasarela como la que define CGI.
La interfaz define una forma cómoda y simple ejecutar programas que se encuentran en la máquina en la que se aloja el servidor. Para el cliente presenta una ventaja en el aspecto de la seguridad, ya que no tendrá que ejecutar ningún programa de efectos desconocidos en su sistema local. Desde el punto de vista humano, además de eliminar la necesidad de aprendizaje, se resuelven los problemas de mantenimiento, operación y distribución de clientes ya que el acceso se realizará a través de cualquier cliente estándar de WWW y la comunicación de realizará según el protocolo HTTP.
Sin embargo, aunque en el servidor ya no será necesario permitir el acceso a extraños, disponer de un programa CGI en un servidor implica que virtualmente todo usuario de internet será capaz de ejecutar un programa en ese servidor, por lo que es necesario atender ciertas precauciones concernientes a la seguridad. La primera de ella suele ser centralizar la localización de todos los CGIs de un servidor en un directorio reservado al efecto al cual se permitirá el acceso únicamente al webmaster. Todo servidor de WWW es configurable de tal forma que al recibir una petición de acceso a un documento alojado en tal directorio considerará que se trata de un programa ejecutable.
Como su propio nombre indica, CGI es una interfaz entre servidores de información y programas de aplicación. Por tanto, define una serie de reglas que deben cumplir tanto las aplicaciones como los servidores para hacer posible la presentación de resultados de programas ejecutables en tiempo real a través de servicios de información estandarizados. Al tratarse de una interfaz, no existe ningún tipo de dependencia con el lenguaje de programación empleado. Así pues, es posible encontrar aplicaciones CGI programadas en lenguajes como en C, C++, fortran, perl, tcl, Visual Basic, AppleScript y cualquier shell de UNIX.
2. Fundamentos
La interfaz CGI es fruto de las conversaciones que se han venido realizando a través de una lista de correo: la www-talk y en su mayor parte, se debe a Rob McCool, John Franks, Ari Luotonen, George Phillips y Tony Sanders. En Enero de 1996, D. Robinson de la Universidad de Cambridge, realizó el primer draft de RFC describiendo la interfaz, aunque se puede encontrar documentación desde mucho antes en el servidor del W3 Consortium, http://www.w3.org/pub/WWW/CGI. En cualquier caso, este draft de RFC aún cuenta con numerosas ambigüedades.
2.1. Invocación de un script CGI
Para invocar un script CGI se emplea una URL que identifica al script, el cual deberá encontrarse en un directorio especial destinado a tal efecto, para lo que debe estar configurado el servidor de información. El formato de esta URL es :
script-url=protocolo"://"SERVER_NAME":"SERVER_PORT
enc_script enc_path_info"?"QUERY_STRING
donde enc_script corresponde al nombre del script, bajo el nombre lógico del directorio asignado a CGIs por el servidor y enc_path_info y QUERY_STRING se explican a continuación.
2.2. Variables de entorno primarias
La especificación CGI define una serie de variables que el servidor debe generar en el entorno de ejecución de los scripts que invoca. Estas variables no son case sensitive y un valor NULL equivale a su no definición. Entre ellas me permito hacer una distinción entre variables primarias y variables secundarias.
Podríamos considerar primarias a aquellas variables cuyo valor puede fijar el usuario directamente en la invocación del script y contienen información que pueda definir la función del script, como es el caso de parámetros.
Como secundarias consideraríamos todas las demás, cuyo contenido es asignado por el servidor de información atendiendo a diversos elementos que definen el estado de la comunicación o al valor de las variables primarias.
Como variables primarias encontraríamos, por tanto, únicamente dos :
- QUERY_STRING
- Como se puede deducir de la sintaxis correspondiente a la URL de un script, esta variable contendrá todo lo que figure a partir del signo "cierre de interrogación" (?) en este URL. La especificación exige que esta información se encuentre URL-codificada, lo que implica que se debe sustituir los espacios en blanco por el signo "más" (+) y los caracteres especiales deben indicarse en hexadecimal precedidos por un signo "tanto por ciento": %xx. Siempre que el script no se encuentre invocado por un form, podrá acceder a esta información ya URL-descodificada como si se le hubiera facilitado desde línea de comandos en forma de argumentos. Así, una shell podrá acceder a ella a través de las variables $1, $2 ... y un programa en C, a través de la función argv.
- PATH_INFO
- A través del URL de invocación de un script, es posible facilitar cierta información adicional al mismo a través del campo enc_path_info. El script CGI podrá acceder a esta información a través de la variable de entorno PATH_INFO. El uso habitual es la indicación de paths de búsqueda de ficheros al script, de donde toma el nombre. Sin embargo, la semántica de esta información viene dada por el programador.
2.3. Variables de entorno secundarias
- AUTH_TYPE
- Es posible establecer protección de acceso a ciertos URLs mediante la adecuada configuración del servidor de información. Si este es el caso de la URL del script, se emplea esta variable para indicar el método de protección.
- CONTENT_LENGTH
- Indica el tamaño del la información asociada a la invocación (attachment) o toma el valor NULL si no se ha asociado infirmación. Esta información puede provenir, por ejemplo de un método POST o PUT de HTTP. Un ejemplo sencillo, es la información facilitada por un form.
- CONTENT_TYPE
- Indica el tipo MIME correspondiente a la información que acompaña a la invocación si procede. Sólo en caso de que esta variable no tenga valor, el script debe tratar de deducir el tipo de la información examinándola. Si aún así no se puede determinar de qué tipo es, se asumirá el tipo application/octect-stream.
- GATEWAY_INTERFACE
- Indica la versión de la especificación CGI que cumple el servidor, de la forma "CGI/revisión", por ejemplo "CGI/1.1"
- PATH_TRANSLATED
- Indica el valor de PATH_INFO una vez el servidor de información ha realizado la traslación de direcciones lógicas a direcciones físicas. El uso de esta variable es interesante ya que un URL no siempre designa un objeto físico, como es un fichero. Sin embargo no es recomendable usarla si se desea hacer portables los scripts ya que depende de la implementación del servidor.
- REMOTE_ADDR
- Indica la dirección IP del agente que invocó al CGI.
- REMOTE_HOST
- Indica el nombre completo (o NULL) del agente que invcó al CGI.
- REMOTE_IDENT
- Si el servidor remoto admite ident facilita el nombre del usuario al que pertenece el cliente. Este valor debe únicamente ser considerado como información complementaria o elaboración de estadísticas, pero nunca como información de autenticación.
- REQUEST_METHOD
- Esta variable sí es case sensitive y facilita el método HTTP empleado para facilitar información al servidor: GET, HEAD, POST o cualquier extensión.
- SCRIPT_NAME
- Proporciona el URL que identifica al script CGI. Es útil para referirse a sí mismo.
- SERVER_NAME
- Proporciona el nombre del servidor tal y como se indicó en la parte <host> del URL de invocación del script. Este nombre puede, por tanto ser una dirección IP, un alias de DNS o un nombre propiamente dicho.
- SERVER_PORT
- Funciona análogamente a SERVER_NAME indicando el puerto de atención del servidor.
- SERVER_PROTOCOL
- Facilita la versión y extensión del protocolo empleado por el servidor
de información.
Por ejemplo:
SERVER_PROTOCOL=HTTP-version|extension-version - SERVER_SOFTWARE
- Proporciona el nombre y versión del software servidor que sirve la petición o ejecuta la pasarela.
2.4. Variables dependientes del protocolo HTTP
La interfaz define una serie de variables específicas para servidores de información basados en el protocolo HTTP. En general, se define una variable por cada cabecera de mensajes del protocolo y se le da el nombre de HTTP_(nombre_de_cabecera). Al darse valor a las variables se realiza un cambio del carácter guión (-) por el carácter subrayado (_). Se exceptúan aaquellas variables cuyo valor sea recogido en otras genéricas, como Content-type y Content-length o que haya sido procesado, como Authorization.Entre las variables HTTP_* más usadas se encuentran:
- HTTP_ACCEPT
- Indica los tipos MIME aceptados por el servidor separados pr comas (,) en la forma habitual: tipo/subtipo, tipo/subtipo ...
- HTTP_USER_AGENT
- Indica el browser empleado por el cliente de la forma software/versión biblioteca/versión.
2.5. Resultado de la ejecución de un CGI
Según la especificación, todo CGI debe generar algo por su salida estándar. Esta salida queda directamente conectada con el servidor de información que, tras cierto proceso la hará llegar al cliente. En función de cómo se realiza esta comunicación entre el CGI y el cliente, se distinguen dos tipos de script :2.5.1. Scripts con salida PH
Se trata del tipo más habitual de script. Exige que el script genere una
salida que corresponda a :
*(Cabecera_CGI|Cabecera_HTTP)NL[Cuerpo_Entidad]
donde NL designa al carácter de avance de línea, Cabecera_HTTP es cualquier cabecera válida del
protocolo HTTP y Cabecera_CGI es una de las
siguientes :
- Content-type :
- Define el tipo MIME a que corresponde la información que proporciona el script. Esta cabecera es de uso obligatorio si la respuesta del CGI incluye un cuerpo de información, el cuál no es obligatorio.
- Location :
- Actúa como un puntero devolviendo un URL en lugar de la información. Un cliente, al recibir esta cabecera debería realizar automáticamente una conexión HTTP para recuperar el URL indicado de manera transparente al usuatio, por lo que lo habitual es que la salida de un CGI que genere una cabecera Location : no contenga cuerpo de mensaje y, por tanto, no precise de una cabecera Content-type : En cualquier caso, dado que los browsers más antiguos no reconocen la cabercera Location : a veces aparecen ambas juntas con un cuerpo de mensaje destinado a informar al usuario de la localización de la información.
- Status :
- Se emplea para facilitar un valor de status definido en la
especificación del protocolo HTTP. En caso de que no se indique, el cliente
tomará un 200 OK.
2.5.2. Scripts con salida NPH
Un script NPH deben devolver un mensaje HTTP completo. El servidor enviará este mensaje completo al cliente sin realizar ningun tipo de análisis de las cabeceras (No Parse Headers) y el buffering intermedio realizado por el servidor se reduce a la mínima expresión, por lo que, en la práctica, es como si el CGI se comunicara directamente con el cliente. En la práctica, y si no se desea descender hasta el nivel del protocolo para conseguir un mayor control, es suficiente con incluir el mensaje HTTP/1.0 200 OK inmediatamente antes de la cabecera Content-type: del CGI para convertir un script CGI PH en un NPH. Otro dato a tener en cuenta es que algunos servidores deben saber que un script es NPH antes de ejecutarlo, por lo que es necesario nombrarlos de manera especial. Así, por ejemplo, el servidor del CERN, empleado para el desarrollo del proyecto, requiere que los nombres de los scripts NPH, comiencen con la cadena "nph-".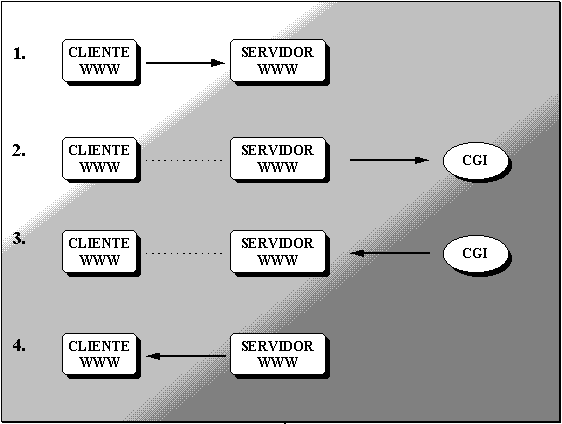
Fig. 1 Funcionamiento de la
invocación de un CGI
3. Procesamiento de forms
3.1. Invocación de scripts para el procesamiento de forms
Todo form consta de dos partes: una página HTML, el form propiamente
dicho; y un script CGI encargado de procesar la información que esta página
recoge. El envío de información se sustenta, como todo el sistema, sobre el
protocolo HTTP y se puede realizar a través de dos métodos definidos en el
mismo: GET y POST.
El script que procesara un documento form se indica en el propio documento
mediante la etiqueta <FORM> según la sintaxis :
<FORM METHOD=método ACTION=script>
Donde METHOD es uno de los métodos
HTTP : GET o POST y script es el URL de
invocación del CGI.
Si el método elegido es GET, el servidor facilitará toda la información cumplimentada por el usuario en el form al CGI a través de la variable QUERY_STRING. Si, por el contrario, el método elegido es POST, el servidor proporcionará toda la información al CGI a través de la entrada estándar de este último. En ambos casos la información se encontrará codificada según el formato que se describe a continuación.
3.1.1. Descodificación de la información procedente de un form
El formato en que se encuentra codificada la información procedente de un
form es un flujo de pares:
nombre=valor
separados por el signo "ampersand" (&). Es decir:
nombre_1=valor_1&nombre_2=valor_2&...&nombre_n=valor_n
En definitiva, se utilice el método que se utilice, habrá que procesar la
información recibida según los siguientes pasos:
- Extraer tokens tomando el signo "ampersand" (&) como delimitador.
- En cada token, realizar una nueva separación tomando el carácter "igual" (=) como delimitador. El primer token obtenido ahora corresponderá al nombre de la variable y el segundo, al valor obtenido. El nombre de la variable coincide con el que figura en el documento en el atributo NAME de cada etiqueta <INPUT>.
- URL-descodificar (URLdecode) los valores obtenidos.
3.2. Uso de GET y POST
Se desaconseja el uso de GET para el envío de información de un form a un CGI debido a que se realizará a través de una variable de entorno que puede tener una longitud más o menos limitada según el sistema. Por ello, la información presente en el form podría desbordarla. En caso de emplear POST, la única aclaración a realizar para aquellos scripts que accedan a su entrada mediante una interfaz de ficheros es que el servidor no colocará ningún signo de terminación como, por ejemplo EOF. Por ello, si se accede de esta forma a los datos, será necesario emplear la información presente en CONTENT_LENGTH.
 Actualizado por: Fernando
J. Echevarrieta Fernández
Actualizado por: Fernando
J. Echevarrieta Fernándezemail: echeva@dit.upm.es