Previous | Next
Objectives|
Introduction|
The File Hierarchy|
The Components of the UNIX File I/O System|
File System Data Structures|
I-Nodes and Links|
I-Device and Partition Names|
Operations on File Systems|
Creating a New File System|
Reasons to Partition a Drive|
Mounting and Unmounting a File System|
Checking a File System|
Conclusions|
Review Questions
Section 7
FILE SYSTEMS AND DISK DRIVES
By the end of this section you will
- understand how UNIX handles the storage and retrieval of information onto disks,
- be familiar with the terms logical disk, partition, blocks, superblocks and i-nodes,
- have used or be aware of the purpose of the commands mkfs, fsck, mount, umount, sync, ncheck, ls -i,
- be able to explain the different meanings applied to the word file system,
- have an overview of the structure and components of the system UNIX uses to store information onto disk drives, and
- be able to create, mount and repair file systems.
The primary job of any operating system is to store information. UNIX (like most operating systems) makes use of a structured upside down, tree-like hierarchy of files and directories. A Systems Administrator must know a number of things about how this information is stored including
- where and why are certain files are located, and
Most UNIX operating systems have a number of standard locations for specific files and directories. The first section of this section will introduce you to some of the more common locations.
- how to manipulate, create and repair the file hierarchy and file system.
The Systems Administrator has to know more than where to find things. If the disk drive becomes corrupted it is the responsibility of the Systems Administrator to attempt to recover the data from that drive. To accomplish this, sometimes difficult task, the Systems Administrator needs to know about the data structures and algorithms used by the operating system to store information onto the disk.
By now you should have an inkling that the unified directory hierarchy you see as a UNIX user is a logical abstraction. The illusion of all the directories and files of a UNIX machine being all linked together under the one directory hierarchy is created by a part of the operating system referred to as the file system. In reality the files and directories that are seen as being joined together can in fact be located on separate partitions, drives and even on separate machines.
Diagram 7-1 demonstrates this. The directory hierarchy as seen by the user is all joined together. In fact the /usr/bin directory and the / directory are both stored on different local partitions (partition is explained below) and the /home directory is actually stored on a drive connected to a remote machine. The file system is responsible from hiding these facts from the user and the commands the used by the users.
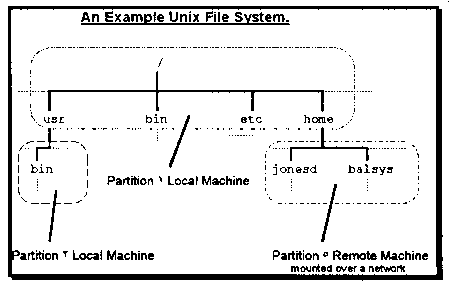
Diagram 7.1. Logical and Physical File System Organisation.
A file system is a collection of algorithms and data structures that are responsible for translating and structuring data stored on disk into the standard format used by UNIX commands.
Each user of a UNIX system is provided their own home directory in which they can create, delete and modify files and directories at will. Most users will have little need to move outside their home directory.
The system administrator on the other hand will have to manipulate files from throughout the entire directory hierarchy. To do this efficiently you will need a good working knowledge of the directory structure. One of the responsibilities of a System Administrator is management of the directory hierarchy that includes
- controlling what files go where, and
It is important that there are system guidelines for the placement of different types of files.
- controlling which users can access certain parts of the file hierarchy,
Users should be restricted to the parts of the file hierarchy to which they must have acccess. Access to other sections of the directory hierarchy should be prevented. This is achieved by using file permissions.
Table 7.1 provides a summary of the more important, relevant or useful directories you may find on a UNIX machine. These will change in some small way from machine to machine. It is by no means an exhaustive list.
Path Purpose
/ the root directory, the basis for the whole structure
/bin the binary directory, contains all the essential commands
needed when the system first boots
/dev the device directory, contains special files associated
with hardware devices (explained later in this section)
/home/usr/users location of user's home directories, usually kept in one
directory, /home is the more common
/etc contains machine-specific configuration files and system
administration databases, some systems place administration
executable programs here
/sbin some systems take the administration executable programs out
/usr/sbin of /etc and place them here
/lost+found used by fsck to save disconnected files and directories
(each partition will have its own lost+found)
/tmp temporary directory used to store temporary files
/usr usually where almost everything else goes
/usr/local the local directory, used to store all local additions to
the file system
/usr/adm administration, logfiles and record keeping
/usr/ucb used on some systems to store commands that were originally
developed at the University of California at Berkeley
/usr/bin more executable programs, those not strictly needed when the
system first boots
/usr/etc some administrative commands on some BSD systems
/usr/lib library files
/lib
/usr/mail mailboxes for users, could be under /usr/spool/mail or
a number of other locations
/usr/man directory containing manual pages
/usr/spool the spool directory, used by mail, print and other systems
/var/spool to temporarily store information that is being spooled
/usr/src source code for utilities and the system
/proc mount point of proc file system which maintains information
about running processes, SVR4
/sbin SVR4, executables used in the booting process and in manual
recovery from failure
/var on some systems the contents of /usr/spool are moved here
Table 7.1. Special Purpose Directories.
/bin and /usr/bin
Both these directories are used to store executable (binary) programs and commands. The distinction between the two directories is the assumption that /usr/bin will not always be present on the root partition.
The next section will introduce the concept of single user mode. Occasionally the Systems Administrator will have to bring up a UNIX machine in single user mode. Single user mode is basically a maintenance mode where only the root account is able to login and the Systems Administrator may perform various maintenance tasks. (A Systems Administrator should always ensure that there is some way of bringing a system up in single user mode.)
When the system comes up in single user mode only the root partition will be mounted (the root partition is the partition that contains the / directory). This may mean that /usr/bin is not present (as it would be in the system depicted in Diagram 7-1).
The /bin directory should contain all the commands that are necessary to bring a system up into single user mode and once there perform the necessary tasks. /usr/bin is used to hold commands that are not strictly essential in single user mode. For example it would be rare for the command yacc to be needed in single user modem so it will not be in /bin.
/usr/local
As a system is being used it will become necessary to add various data files, source programs and executable commands. Where should this information be kept?
One option is to add these files throughout the entire file hierarchy. Executable programs under /usr/bin, configuration files under /etc, library files under /usr/lib, and so on. However this causes some problems, especially when the system must be upgraded.
When a UNIX operating system is upgraded what usually happens is the vendor will ship a new tape or CD-ROM containing the new, updated operating system. The Systems Administrator will install the new operating system onto the machine drives and the system will be ready to go.
The problem is that installing a new operating system will generally overwrite any previous information, including any local programs and files the Systems Administrator has installed.
The solution to this problem is to backup any local files before installing the new operating system and once it is installed restoring the local files. Backing up local files is very difficult if they are spread throughout the file hierarchy.
/usr/local is used to store all local files under one directory. On most system /usr/local will contain sub-directories including (amongst others)
- doc,
Used to store local documentation.
- bin,
Containing additional local executable commands and programs.
- src,
Where the source code to local programs and commands are stored.
- lib and include.
Used for local library and include files.
Exercise 7-1. Explore the directory hierarchy of your machine. Attempt to identify each of the locations listed in Table 7.1. on your machine.
This is the type of information that would be useful in your log book.
Exercise 7-2. Examine your systems' file hierarchy for the /usr/local, /bin and /usr/bin directories. What do they contain?
The following sections aim to provide you with an overview and definitiion of all the different components that work together to make the UNIX file I/O system work. Diagram 7.3 provides a representation of how all the different components fit together.
The Physical Disk
The information ends up (or starts life depending on how you look at it) as binary information stored on the surface of a disk drive. The smallest accessible unit of measure on a disk is a block. A disk block is usually between 512-4096 bytes depending on the device.
A modern disk drive will consist of a number of circular surfaces. Each surface is divided by
- a collection of concentric circles, the area between each concentric circle are tracks, and
- a collection of lines across the diameter that divide the surface into sectors.
The collection of tracks on all surfaces that are the same distance from the centre form a cylinder.
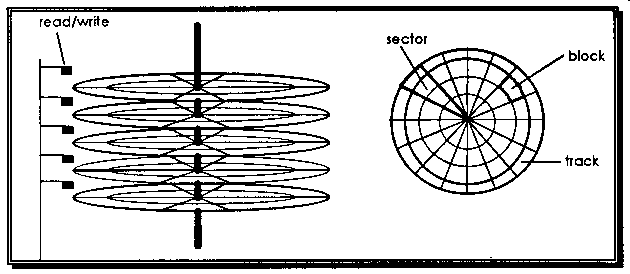
Diagram 7.2. The Physical Structure of a Disk Drive.
Disk Controller
A disk controller is an electronic device that tells the disk drive what to do, which block to read from where, and when. A single disk controller will typically control a number of separate disk drives.
Most UNIX boxes will rely on SCSI (pronounced scuzzy) disk controllers, though a few PC based Unices will support IDE controllers.
Device Drivers
Every single physical device has a different command language that it understands including disk controllers. Different types of disk controllers and other devices expect to be told to do things in different ways.
The UNIX operating system defines a standard method that is used to perform I/O regardless of the type of device that is being used. All commands and other parts of the operating system will use this standard method to perform I/O.
However because all the physical I/O devices talk a different language something must perform the translation between how UNIX performs I/O and the commands that I/O devices understand.
The part of the operating system that performs this task are the device drivers.
Every physical device connected to a UNIX machine must have an appropriate device driver installed into the kernel of the operating system before the operating system can use the device.
It is possible for one device driver to service a number of different devices, provided that the devices are all of the same type.
Device Files
A device file is basically an entry point into a device driver and are usually located under the /dev directory. Device files are used by many parts of the operating system to send or retrieve information from a device.
Device files can even be used in conjunction with the I/O redirection performed by shells to send the output of commands directly to devices.
For example:
-
Send the a long directory listing of the current directory to the terminal used by the Systems Administrator.
ls -l > /dev/console
/dev/console is explained in Table 7.2.
The entry point used by a device file is made up of
- a major device number, and
The major device number is used to indicate the particular device driver that the device file is pointing to.
- a minor device number
The minor device number indicates which entrance into the device driver that this particular device file will use. A device driver is liable to have many entrances each used to access a different device.
A major difference between device files and normal files is that when ls -l is used on a device file the size of the file is not shown. Instead the ls command displays the major and minor device numbers of the device file.
For example:
-
ls -l /dev/null
crw-rw-rw- 1 root root 1, 3 Aug 6 00:34 /dev/null
This device has a major device number of 1 and a minor device number of 1.
There are usually two types of device file, characterised by the method that is used to transfer information
- character device file, and
Information is sent to/from the device one character at a time. Examples of a character device include serial ports, printers, terminals and modems.
- block device file.
Information is sent to/from the device a block at a time. One block is usually 512 or 1024 bytes. An example of a block device is a disk drive.
Device File Usual Purpose
/dev/console the system console, the terminal used by the
Systems Administrator
/dev/ttyp0 a pseudo terminal, used by logins over a network
/dev/tty0 a dumb terminal connected via serial
/dev/ser a serial port
/dev/par a parallel port
/dev/null the null device (ignores everything sent to it)
Table 7.2. Example Special Device Files.
It is important that the permissions on a device file are set correctly. Incorrectly set permissions will result in users being able to read or send information straight to the a physical device. In many cases (hard disk drives for example) this is not a good idea.
When a Device File is Deleted
It is often suggested that a physical copy of the output of the ls -l /dev command should be made so that a record of the major and minor device numbers associated with every device file can be kept.
The reason being is that if the entries in /dev become corrupted or are deleted then big parts of the system will stop working. It is important that the device files can be reconstructed.
A device file is created using the mknod command. The mknod command takes as parameters
- the name of the device file to create,
- whether the device file is a character device or a block device,
- the major device number, and
- the minor device number.
The name of a device file is not as important as the major and minor device numbers. Two device files can have completely different names and yet they will still point to the same device if the major and minor number are identical.
For example:
-
The /dev/null device file is called the null device. Anything sent to the null device is simply thrown away. The following sequence of commands first removes and then recreates the /dev/null device file.
ls -l /dev/null
crw-rw-rw- 1 root root 1, 3 Aug 6 00:34 /dev/null
rm /dev/null
cat /etc/passwd > /dev/null
ls -l /dev/null
crw-rw-rw- 1 root root 10356 Aug 6 05:22 /dev/null
rm /dev/null
mknod /dev/null c 1 3
ls -l /dev/null
crw-rw-rw- 1 root root 1, 3 Aug 6 00:34 /dev/null
Exercise 7-3. The tty command displays the device file associated with the terminal the user is currently logged in at. Use the ls command to discover whether it is a character device or a block device.
Exercise 7-4. Examine the permissions of the terminal device file. Which users can write and read to the device file? Change the permissions so another user can write to your terminal. Have them redirect the output of a command onto your terminal.
Exercise 7-5. Make a hard copy of a long listing of your systems device files. (You will use it for the next question)
Exercise 7-6. Log onto two different terminals or consoles as the root user. Determine which device files are associated with one of the terminals by using the tty command. Delete that device file. How does it affect the session? Log out on that terminal. What happens? Why? (use mknod to recreate the device before leaving).
File Systems
There are many different methods that can be used to structure the way in which information is stored onto a disk drive. MS-DOS uses one method, OS/2 uses another and different versions of UNIX each use different methods. Under UNIX the part of the operating system responsible for structuring and understanding the information that is stored on disk is called the file system.
Some operating systems (MS-DOS for example) can only handle one file system. The UNIX operating system can manage many different file systems at the same time. Each of the partitions in Diagram 7.1. could be using completely different file system types.
This is possible because the code associated with each file system translates how the information is structured on the disk into a standard UNIX programming interface. This standard programming interface is used by the majority of UNIX commands to access the services provided by the file system kernel code.
This means that under most versions of UNIX operating system, files can be copied (using the normal UNIX command cp) from a partition formatted using MS-DOS onto a partition formatted using a UNIX file system.
Different file systems have different characteristics. Table 7.3 lists some of the different file systems you'll come across and some of their obvious differences.
In Table 7.3 the label ext2 file system refers to the collection of code and data used to implement a file system called ext2 (extended file system 2, that is the major file system used on Linux machines).
File System Description Characteristics
MS-DOS standard MS-DOS limit of 8 character filenames
file systems with 3 letter extensions
ext2 standard Linux allows 255 character filenames
file system
s5 System V file system allows 14 character filenames
Table 7.3. Brief comparison of different file systems.
(Most versions of UNIX supply a file system capable of reading MS-DOS floppies and in some cases hard disk drives. Linux is one of these.)
System Calls
The standard programming interface mentioned in the previous section consists of a number of system calls. A system call is a special type of function called used by programs to access services provided by the operating system. These services can include
- opening, closing, reading and writing from files,
- changing the priorities or killing a process, and
- allocating sections of memory and others.
You should remember from a previous section that there is a section of the manual pages set aside for system calls.
Exercise 7-7. There is a system call called kill. Examine the manual page for this command. (HINT: Remember there is also a user command called kill.)
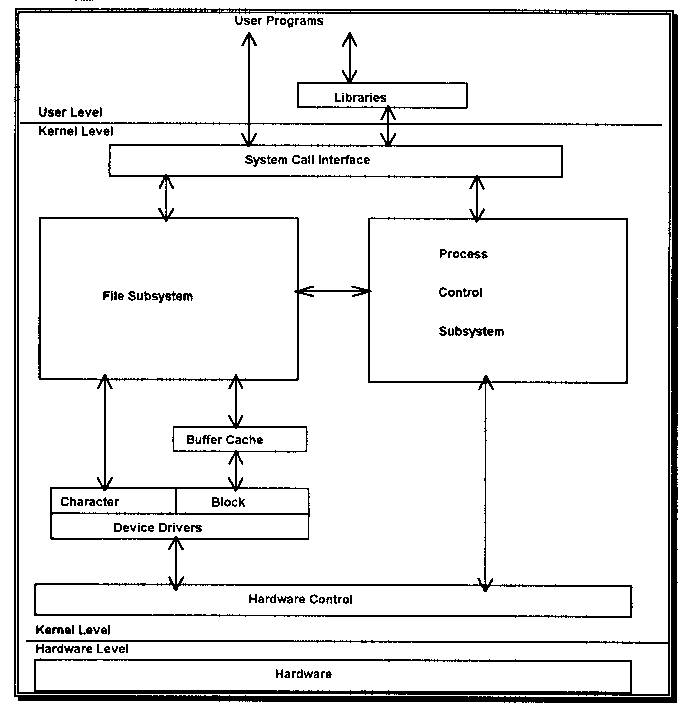
Diagram 7.3. An Overview of File I/O.
User Commands & Programs
The normal user interface with the file system consists of commands or programs like cp, ls and rm. A Systems Administrator will use additional commands like fsck, mount and mkfs (explained later in this section).
These commands make use of system calls that define the standard interface that all file systems must fulfil. By using the standard programming interface the commands will work with files stored on different file systems. The interface is used to hide the implementation detail.
The following section provides a basic introduction the internal data structures used by a standard UNIX file system. The actual implementation of most modern UNIX file systems is actually much more complex.
The following structures are based on the s5 file system. The s5 files system was the old UNIX file system standard developed as part of SysV UNIX. Most modern UNIX file systems are based on the Fast File System (FFS) developed at the University of California at Berkeley. The FFS extended the basic structure of the s5 file system to make it more efficient.
Blocks
The smallest unit of information that can be read from or written to a disk is a block. Some file systems specify a logical block size that may be different from the physical block size of the disk drive.
A block can only be used by one file. That means if you have a block size of 1024 bytes and a file that is 1030 bytes long. That file will need to use two blocks.
The Boot Block
The first block in all partitions are reserved to act as a boot block. The boot block on the boot partition is used to hold the operating system boot strap (or loader) program. This small program (it needs to fit on one disk block) has enough code to locate the operating system kernel and to place it into memory so that it can start executing.
The SuperBlock
The second block in any partition will tend to be the superblock. The superblock is basically the master index for the file system. It is used to maintain information about the entire file system.
Information kept in the superblock includes
- the size of the file system (partition),
It is likely that there will be multiple partitions on one disk. This records the size of partition that contains the superblock.
- address of the first data block,
- the number of free blocks,
- a list of the free blocks,
When new files are created the file system code must locate free blocks that can be allocated to the new file.
- the time and date the superblock was last updated, and
- the file system's name.
The I-Node
To read the information from a file the programs need to know where on the disk the blocks that hold the information in the file are stored. Under UNIX it is the i-node that points the way to the data.
The information kept on the i-node also includes
- the type of file,
Is it a normal file, a directory, a device file or any of the other special types recognised by the operating system?
- access permissions,
Which users can perform what operations?
- the number of links,
The number of hard links making using of the i-node (links are explained in more detail below).
- user and group owner identifiers,
The UID and GID of the user and group owners of the file.
- size of the file in bytes,
- time the file was last used,
- time the file was last modified,
- time the i-node was last changed, and
The i-node is changed whenever any of this information is changed about the file.
- the addresses of thirteen disk blocks.
The file system must be able to find all the data that is contained by a file. UNIX uses these disk block addresses to point to the data associated with this i-node.
Every file in a file system must have an i-node. Note that the i-node does not store the name of the file. The name of the file is stored in the directory. A directory in UNIX is simply a file that contains filenames and pointers to the i-nodes of the files within the directory.
The number of i-nodes in a partition is set and must be decided upon when creating the file system on that partition. Once this decision is made it limits the number of files that can be created on that file system (since every file must have an i-node). A general rule is that about ten percent of a file system will be taken up by i-nodes.
However, if you know a particular partition is going to be used for a few very large files you may decide to modify the number of i-nodes (the same applies if the file system will contain very small files.)
The concept of an i-node is central to the UNIX file system. Diagram 7.4 provides a representation of how an i-node points to all the data blocks related to a particular file and a summary of the other information the i-node stores about a file.
An i-node contains a number of pointers that, in some way, point to the disk blocks owned by that file. Some of these pointers point directly at data blocks. Others point to indirect block.

Diagram 7.4. I-Node structure.
An indirect block, instead of containing data, contain the pointers to other blocks. A single indirect block can contain pointers to at least another 256 blocks (how many depends on the particular version of UNIX being used and how it is configured).
A UNIX i-node can point to
- single,
The pointers in a single indirect block point to actual data blocks.
- double, and
The pointers in a double indirect block point to a single indirect block. Each of the single indirect blocks then point to actual data blocks
- triple indirect blocks.
The pointers in a triple indirect block point to double indirect blocks which then point to single indirect blocks......
Depending on size and other factors a UNIX i-node can point to enough data blocks for a file in excess of two gigabytes in length.
Exercise 7-8. If a single data block contains 512 bytes of information and the i-node contains 10 direct blocks, 1 indirect block, a double indirect block and a triple indirect block and each indirect block contains pointers to another 256 blocks, what is the size of the largest possible file?
The -i option of the ls command can be used to view the i-node numbers that are associated with individual files. Some system will also provide a program called ncheck that can be used to display the name of the file associated with a particular i-node.
Executing the command cp /etc/passwd $HOME/passwd will cause
- a new i-node to be created,
- a new entry (pointing to the new i-node) to be added to the directory $HOME for the file passwd,
- each of the data blocks of the file /etc/passwd to be read and copied to new data blocks, and
- the block addresses of the new i-node are updated to point to the new data blocks.
Once the cp command has completed you have two completely separate files with no relation between them. Executing a command on one of the files will not effect the other file in any way.
Hard Links
The command ln /etc/passwd $HOME/passwd creates a hard link called $HOME/passwd that points to /etc/passwd file. The process carried out as a result of this command is
- a new entry is added to the $HOME directory, and
- the new entry is set to point to the same i-node used by /etc/passwd.
With a hard link the two files share the same i-node and thus the same data blocks. Any change made to one file also appears to be made to the other.
A hard link can only be used to join two files that are within the same partition. This is because the i-node pointers contained in directory entries can only point to i-nodes that reside within the same partition.
Soft Links
The command ln -s /etc/passwd $HOME/passwd creates a soft or symbolic link. The process involved in creating a soft link includes
- creating a new i-node and setting the file system to soft link,
- adding a new entry to the $HOME directory to point to the i-node,
- creating new data blocks for the new file pointed to by the i-node, and
- placing into the data blocks the name of the file the soft link is pointing to (in this case /etc/passwd).
When a program tries to access the contents of the symbolic link the file system notices that the file type is a symbolic link and reads the name of the file the link points to. The file system then carries out the requested command on this new file.
For example:
-
The difference between a soft and a hard link can be demonstrated by a number of simple commands.
bash$ cat > hello
hello there
lt;CTRL-D>
bash$ ln hello2 hello
bash$ ls -il
total 2
14041 -rw-r--r-- 2 root root 23 Aug 9 22:02 hello
14041 -rw-r--r-- 2 root root 23 Aug 9 22:02 hello2
Notice that the i-node numbers are the same.
bash$ ln -s hello3 hello
bash$ ls -il
total 3
14041 -rw-r--r-- 2 root root 23 Aug 9 22:02 hello
14041 -rw-r--r-- 2 root root 23 Aug 9 22:02 hello2
14042 lrwxrwxrwx 1 root root 5 Aug 9 22:02 hello3 -> hello
Not only are the i-node numbers different but the representation seen by the user is different. In addition any change that is made to the file hello will also appear to have been made to hello2 (but not hello3).
Exercise 7-9. Perform the steps outline in the above example.
Exercise 7-10. Change the permissions on the file hello. What happens to the permissions for the file hello2? Try the same procedure on the file hello2. Why is this so?
Exercise 7-11. Repeat the procedure from exercise 7-11 for the files hello and hello3. What happens? Why is it different?
Exercise 7-12. What are the i-node numbers for the files in the root directory? Why do you think the i-nodes have these numbers?
Most UNIX systems use a standard format for names given to device files associated with disk drives and partitions. The format of these device filenames depends on the version of UNIX being used. Table 7.4 summaries some of the different formats being used.
Every disk partition will usually have two device files associated with it. One device file will be a character device file and the other will be a block device file. The majority of commands will use the block device file to communicate with the disk. The character file is used by commands to create a new file system (format) or fix an old one.
UNIX Version Partition Name Explanation Example
System V cCdDsS C - controller number c0d0s2
DsS D - disk number c3d0s0
S - partition number 0s0
BSD (Linux) ccDp cc - two letter name hd0a
D - drive number rd0g
p - partition letter hd0b
Table 7.4. A Comparison of Disk Device Naming Schemes.
When a system is supplied from the vendors there will be a number of device files associated with each disk drive including
- a drive device file, and
The drive device file is used to refer to the entire disk drive.
- a number of partition device files.
The partition device files are used to access the various partitions into which a disk may be divided.
System manufacturers do not know how many partitions may be created when the system is shipped. Generally they will set aside a number of device files for use by the one drive. There is no need for all of the supplied device files to be used.
For example:
-
The following example is taken from a Linux machine. /dev/hda is the device file associated with the entire disk. The other device files are associated with particular partitions.
brw-rw---- 1 root disk 3, 0 Jan 29 1994 /dev/hda
brw-rw---- 1 root disk 3, 1 Jan 29 1994 /dev/hda1
brw-rw---- 1 root disk 3, 2 Jan 29 1994 /dev/hda2
brw-rw---- 1 root disk 3, 3 Jan 29 1994 /dev/hda3
brw-rw---- 1 root disk 3, 4 Jan 29 1994 /dev/hda4
brw-rw---- 1 root disk 3, 5 Jan 29 1994 /dev/hda5
brw-rw---- 1 root disk 3, 6 Jan 29 1994 /dev/hda6
brw-rw---- 1 root disk 3, 7 Jan 29 1994 /dev/hda7
brw-rw---- 1 root disk 3, 8 Jan 29 1994 /dev/hda8
brw-rw---- 1 root disk 3, 9 Jan 29 1994 /dev/hda9
Notice that the major device number is the same for all the device files.
Examine the permissions and ownership of the device files for the disk drive and its partitions? What would happen if the permissions were brw-rw-rw instead of brw-rw----?
By default if users wish to access the information on a disk they must use the system calls supplied by the kernel. These system calls then access the file systems algorithms within the kernel to access the information on the disk. The file system also implements the file protection mechanism. It is the file system that checks whether or not a particular user can access the file they are asking for.
If anyone could read/write direct to the device files then the file system could be bypassed. This in turns bypasses the file protection scheme. With a little bit of work a program could be written to obtain and evaluate all the information on the disk.
Always make sure that the permissions on a device file are set correctly.
There are a number of basic operations that a Systems Administrator can carry out on a file system including (some of the following commands will be system specific)
- create a new file system (the mkfs and newfs commands),
Creating a new file system initialises all the data structures talked about in the next section. This operation makes the file system ready to be used to store information.
- mount a file system (the mount command),
Mounting a file system connects it into the entire file hierarchy as seen by the user. Each of the different partitions from Diagram 7.1. would have been previously mounted.
- unmount a file system (the umount command),
Once a particular file system is finished with it must be removed from the file hierarchy.
- monitor a file system (the find, fstat commands),
In some cases you will wish to monitor the state and contents of a file system.
- check the integrity and repair a file system (the fsck and fsdb commands), and
In some instances the file system will be corrupted and need to be fixed.
- flush a file system's buffers (the sync command).
UNIX doesn't automatically write all changes made to a file straight to disk. It buffers some of that information in memory. This means that if the power gets turned off unexpectedly the information in memory will be lost and it is possible that the file system will be in a corrupt state. This is the reason why you should never just turn off a UNIX computer (if you can possibly avoid it).
A brand new 5 Gigabyte drive has arrived waiting to be connected to the system. The process to be undertaken includes the following steps
- low level formatting of the disk,
- partitioning of the disk,
- creating a file system on each of the partitions, and
- mount the file system.
Low Level Format
Most modern disks are pre-formatted by the manufacturer so a low level format may not be necessary. If a low level format must be performed then the command will be machine and operating system dependent.
Related to this step is identifying any bad blocks that may exist on the disk surface. There are no standard UNIX commands to format a drive or check for bad blocks.
For example:
Linux provides a command fdformat to perform a low level format of floppy disks. (examine the man page)
Partition the drive
It is rare for a disk drive to be used as one large partition. In most cases a disk drive will be divided into a number of partitions. The Systems Administrator must make a number of decisions about partitioning the disk drive
- how many partitions will there be?
- how big will the partitions be?
- what type of file system will the partition be formatted as? and
- what portion of the file hierarchy will be stored on each partition?
Under UNIX there is no set command that is used to divide a disk drive into partitions. Each system will implement its own command. Examine the system documentation to discover the appropriate command. apropos partition is always a good place to start.
Create the file system
Once the disk has been partitioned each partition must have the data structures (superblock, i-nodes etc) mentioned in a previous section initialised. The mkfs or the newfs commands are used to initialise a partition depending on the system.
Mount the file system
Mounting the file system will usually entail two steps
- create or choose a mount point, and
- mount the directory.
The new file system needs to be mounted either manually using the mount command or automatically when the system boots up.
The smallest drives that can be purchased today for a UNIX system would be at least 100 to 200 Mbytes in size. It is possible to use the entire disk space as one file system. This is generally not a good idea. Reasons for partitioning a disk are explained below.
Separation
Different sections of the disk hierarchy have different characteristics that make keeping them on separate partitions a good idea. These characteristics include
- rate of change,
The users' home directories and those used to store incoming mail or news are likely to change almost continually, where as others like the root directory, /bin, /usr/bin and others are unlikely to change at all.
- size and number of files, and
See the discussion above about the number of i-nodes being fixed.
- the possibility of runaway processes.
Some partitions like tmp and spool directories are very likely to have runaway processes chew up lots of disk space. It a file system fills up it ceases working. Keeping these directories in separate partitions reduces the problems this can cause.
In addition the software on most machines can put into one of two categories
- system software, and
Software distributed by the operating system vendor.
- local software.
Software installed by the owners of the machine.
When an operating system is updated the install script will usually just replace everything in certain directories. It is suggested that local software be stored in a separate directory and possibly partition so that it can be kept safe.
Size of the Backup Media
Backups are considerably easier if you can achieve at least one partition per backup media (tape, optical disk). If you are using 150Mb tapes and have a 500Mb partition it will be more difficult to backup.
Backups should be as easy as possible to do.
Performance
Certain sections of the whole file system will be busier than others. By distributing the busy sections amongst different partitions on different drives you can spread the load around and improve the performance of the system.
Look back to Diagram 7.1. The full file specification of the adm directory is /usr/adm but this is only true because partition 2 is mounted in the /usr directory. The /usr directory is referred to as the mount point for partition 2 (before mounting adm the /usr directory was empty).
A mount point must be an empty directory and is the place in which a new partition joins the rest of the directory hierarchy. If a new partition is mounted in a directory that is not empty one of the following may happen
- if there is already another mounted file system using the mount point the mount command will report an error,
- if there are any normal files already there they will disappear (they will reappear when the partition is unmounted), or
- you may mount new file systems in directories that are part of other mounted file systems (as long as they satisfy the above criteria).
There are two basic methods that can be used to mount a file system
- file system configuration files, or
Either the /etc/vfstab or /etc/fstab file is examined during the operating system's boot process.
- the mount command.
When mounting a file system the following information is required
- the type of the file system,
Remember UNIX can support many different types of file system. The mount command must be told the type of file system this new partition is so that it can use the correct algorithms.
- the device file associated with the partition,
- the directory name of the mount point, and
- a variety of options that control how the file system is mounted.
File System Configuration Files
All UNIX operating systems have a configuration file that controls which partitions are automatically mounted when the system boots. BSD based systems use the file /etc/fstab while SysV based machines use the file /etc/vfstab.
Both files are text based with one line per partition separated into a number of columns. The major difference between the two files (apart from the name) is the format of the columns.
For example:
-
The following is an example of an /etc/fstab file taken from a Linux machine.
partition name mount point file system type options
/dev/hdb1 swap swap defaults
/dev/hda2 / ext2 defaults
/dev/hdb2 /home ext2 defaults,usrquota
none /proc proc defaults
The mount Command
While the fstab and vfstab files are used to automatically mount a file system at boot time, the mount command is used to mount a file system without having to reboot the computer.
The format of the mount command is similar to
mount -t type device_file mount_point
The -t switch is used to indicate the type of file system. The actual switch used on some systems will be different. type is a unique identifier that indicates the type of file system on the partition. Most systems will also take other command line arguments that can be used to specify further options.
For example:
-
The following mount command is taken from a Linux box
mount -t ext2 /dev/hda2 /bin
It results in the ext2 partition associated with the device /dev/hda2 to be mounted under the /bin directory.
Without any parameters the mount command will display the currently mounted file systems.
For example:
pol# mount
/dev/hda3 on / type ext2 (rw)
/dev/hda1 on /home type ext2 (rw)
none on /proc type proc (rw)
The umount Command
The umount command is used to remove a file system from the file heirarchy. The umount command can take as a parameter either the device file of the partition or the mount point.
For example:
-
To unmount the file system mounted in the example from the above section, either of the following commands can be used.
umount /dev/hda1
umount /bin
If the umount command doesn't work, reasons may include
- the user performing the umount doesn't have write permission on the device file on which the file system resides (typically only the root user can unmount a file system), or
- the file system is being used.
The file system is being used if
- the current working directory of any user is within the file system,
- there is another mounted file system mounted within the file system, or
- there is a process running that is accessing a part of the file system.
Exercise 7-13. Discover what partitions are currently mounted on your machine. Which partitions are automatically mounted on startup?
Exercise 7-14. Use the manual pages to discover the format of your system's disk configuration files. Discover the different types of file system supported by your system.
Exercise 7-15. Create a new file system and mount it somewhere in your directory hierarchy. (Simplest method might be to use a floppy disk if your system supports it.)
Exercise 7-16. All versions of UNIX provide a directory /mnt. This directory is set aside to be used as a temporary mount point for file systems. If your system supports it (Linux does) mount an MS-DOS floppy under the /mnt directory (make sure it has something on it). Refer to the manual pages for mount for information how to do it.
Copy a file of at least a couple of hundred kilobytes onto the floppy. Once it is copied do nothing but observe the drive lights (wait for between 30 seconds and 2 minutes). What do you observe? What do you think causes this?
Perform the previous task again but this time instead of waiting type the command sync. What happens? Why?
Repeat the process again but this time unmount the floppy straight away. What happens? Why?
There will come a time in every System Administrator's working life when it is discovered that a file system has become corrupt. When this occurs it is best to follow the advice of Douglas Adams and DON'T PANIC!!! Panic at such a time invariably causes more complex problems to arise.
UNIX provides a very powerful command that can usually be used to recover most damaged file systems. Even if it doesn't work, as a professional Systems Administrator you should have recent backups of the file system anyway.
fsck stands for file system check. The type of problems fsck can generally repair include
- one data block being pointed to by several i-nodes (one block owned by multiple files),
- blocks marked as free but actually being used,
- blocks marked as used but actually free,
- incorrect link counts in the i-node ,
- differences between the size field of the i-node and the number of data blocks actually pointed to by the i-node,
- illegal blocks within files,
- i-nodes that contain information but don't occur in a directory entry (these are placed into the lost+found directory in the root directory of the file system, and
- directory entries that point to illegal or unallocated i-nodes.
Guidelines on Using Fsck
- Where possible fsck should be run on a unmounted file system using the character device file and not the block device file.
- If you receive any particularly drastic messages from fsck first thing you should do when it is finished is to run fsck again.
- Write down any device file, i-node and block numbers fsck reports. Using the ncheck command allows you to identify which file belongs to an i-node. This information can be used to discover whether you have to recover something from your backups.
- If fsck reports it Can't stat, open, read... check to see that the disk is connected properly, not write protected and that you have permission on the character and block device files.
- If fsck asks if it can SALVAGE? FIX? CONTINUE? RECONNECT? or ADJUST? it is usually safe to let it.
- If fsck asks to REMOVE? or CLEAR? be more picky. Be ready to recover material from your backups.
Exercise 7-17. Select a floppy disk you can afford to lose. Mount the floppy disk and copy to it a large file. After the first phase of writing to the disk has finished, remove the disk (don't unmount it just remove it). Now attempt to unmount the floppy as if it were still in the drive (there will be errors).
Once all the hubbub has died down attempt to remount the floppy. What happens? Try to fix the floppy.
Hopefully by now you have an inkling of how the UNIX operating system stores and retrieves information from disk drives. You should be aware
- of the separate components that make up the UNIX file sub system
- of the various commands useful when manipulating, creating and using file systems
- the format of configuration files for file systems
7.1. What is the purpose of the following directories
- /etc
- /usr/spool/mail
- /home
- /bin
7.2. Define the following terms with reference to this section
- block,
- cylinder,
- file system,
- i-node,
- device file,
- major and minor device number.
7.3. What are the two methods that can be used to mount a file system.
7.4. What are the steps used to prepare a new disk drive for use on a UNIX system?
7.5. What is the difference between a hard and soft link?
Previous | Next
David Jones (author)
Chris Hanson (html 05/09/96)