La experiencia como docente en escuelas técnicas y universidades me motiva a escribir este manual, que espero, llene las expectativas de muchos programadores empíricos y profesionales. Trataré de explicar detalle a detalle los argumentos teóricos en los que sustentan los procedimientos prácticos, ya que soy del criterio de que si se hará algo debemos estar seguro el porqué se va hacer. Es posible que cometa errores y por esta razón les pido disculpas de antemano, agradecería cualquier comentario o sugerencia que me permita poder modificar este manual para ganancia de los todos los usuarios del mismo.
Para este manual utilizaremos la versión de Access 97, no porque sea el mejor, sino porque posee las herramientas de programación incorporada (especificamente los tipos de datos Workspace, Database y Recordset); con esto estoy diciendo que éstas herramientas se incorporan en la versión Developer del Office 2000 y todavía no la he conseguido. En todo caso, la diferencia no importa, sugiero crear las Bases de Datos en la versión 97 (sin tablas) y luego convertir el archivo a la versión 2000, automaticamente se heredan estos tipos de datos y se podrá programar sin problema.
El curso comprende 2 áreas de estudios : Access en la gestión de Bases de Datos y Access como lenguaje de Programación.
Access como Gestor de Bases de Datos :
Access es un programa que permite la manipulación de grandes
cantidades de información. Esta información tiene la característica
que se encuentra clasificada y organizada de tal manera que su gestión
en una computadora sea la más eficaz y oportuna.
 |
|
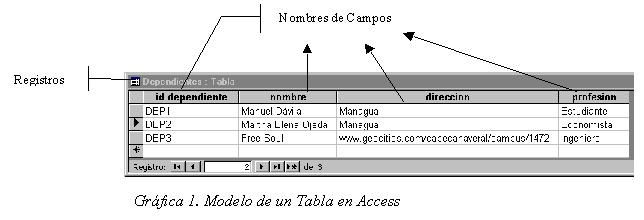
En la Gráfica anterior podemos notar que la tabla está
compuesta de 4 Campos y de 3 Registros. De la misma se deriva que la tabla
es un conjunto de información relacionada a través de variables
llamadas campos. Decimos que son variables porque para el registro 1 el
campo Nombre es Manuel Dávila pero para el registro 2 el
campo Nombre es Martha Elena Ojeda.
Además de las tablas Access posee otros elementos que facilitan
enormemente la gestión de la información. Veamos cuales son
:
 Consultas
de Selección :
Consultas
de Selección :
Permiten presentar la información contenida en una o más
tablas. Las consultas de Selección son importantes para la creación
de Formulario y de Informes, así como de otras consultas de selección.
 Consultas
de Datos Anexados :
Consultas
de Datos Anexados :
Consultas que permiten copiar registros de una tabla hacia otra. Son útiles para cuando deseamos limpiar una tabla que contiene registros que ya no tienen válidez como información actual pero sí como información de futuras investigaciones.
 Consultas de Eliminación :
Consultas de Eliminación :
Consultas que permiten eliminar registros de una tabla, los registros a eliminar generalmente ya fueron respaldados en otra tabla usando una consulta de Datos Anexados. Son útiles para evitar que las tablas se recarguen de información innecesaria.
 Consultas
de Actualización :
Consultas
de Actualización :
Son consultas que permiten realizar operaciones de cálculos u operaciones aritméticas. Estas operaciones las podemos realizar sobre campos de una o más tablas e incluso en otras consultas de selección.
 Consultas
de Referencias Cruzadas :
Consultas
de Referencias Cruzadas :
Son consultas que permiten realizar consolidados de cantidades a partir
de los datos contenidos en una o más tablas.
 |
|
De los anterior podemos deducir que los formularios tienen la función de permitir alimentar las tablas (agregar datos), modificar los datos de las tablas e incluso eliminar los datos de las tablas. Para hacer esto los formularios son creados a partir de las tablas o de las consultas definidas anteriormente.
Hay dos tipos básicos de formularios : Los Formularios Simples y los Principal - Subformularios.
Formularios Simples :
Son aquellos que realizan las gestiones sobre los datos de solo una tabla.
Formularios Principal - Subformularios :
Son aquellos que realizan las gestiones sobre los datos de una o más
tablas.
 |
|
Informes Simples :
Son informes basados en una sola tabla o consulta, por ejemplo, un Informe que presente todos los trabajadores de una compañía o todos los productos contenidos en un inventario.
Informes de Rupturas :
Son informes que se basan en una sola tabla o de más de una tabla,
como ejemplo podemos poner aquellos informes en los que se presenta un
listado del personal de una empresa o compañía agrupados
por Cargo o Departamento de trabajo; también tenemos un Informe
que presente la existencia de productos en un Inventario agrupados por
categorías.
 |
|
 |
|
Supongamos el control de inventarios (el ejemplo más fácil de estudiar y el más típico para aprender a manejar Access), comencemos por analizar el elemento que necesitamos inventariar : un producto, luego veamos como lo clasificaremos, sigamos con el control de los bodegueros, continuemos con el proveedor y finalmente determinaremos las bodegas en las que los almacenaremos.
Como se puede observar podríamos resumir todo lo anterior en las Tablas : Productos, Categorías de Productos, Bodegueros, Proveedores y Bodega. En otras palabras encontramos un universo de datos que están relacionados pero a la vez podrían estar no relacionados directamente. Continuando con el análisis ahora vamos a "desmenuzar" los Productos y solo basta en pensar un poco las características de un Producto. Normalmente nos damos la idea de que un producto puede presentar las siguientes características : Código, Nombre, Fecha de Fabricación, a quién se lo compramos, a qué categoría pertenece, la cantidad existente, el precio, fecha de Vencimiento, etc. Vamos a limitar las características porque podrían variar según el producto y la necesidad de información de las diversas empresas.
Si bien, es cierto ya "desmenuzamos" el producto aún podría faltar terminarlo de hacer "tiritas" , por ejemplo cuando decimos a quien se lo compramos podríamos sacar la siguiente información : El código del Proveedor para reconocerlo, Nombre del Proveedor, Dirección, Teléfono, y otros datos que quizás son menos significativos para nuestro interés actual : El Producto.
Resumamos todo el análisis en el siguiente cuadro tratando de
abarcar todos los elementos que hemos nombrado en nuestro caso de estudio
el Inventario.
| Producto | |||
| Código | |||
| Nombre | |||
| Fecha Fabricación | Día
Mes Año |
||
| Proveedor | Código
Nombre Dirección Teléfono |
Primer Nombre
Segundo Nombre Primer Apellido Segundo Apellido |
|
| Categoría | Código
Descripción Observación |
||
| Cantidad Existente | |||
| Precio | |||
| Unidad de Medida | |||
| Fecha Vencimiento | Día
Mes Año |
||
| Proveedores | Código | ||
| Nombre | Primer Nombre
Segundo Nombre Primer Apellido Segundo Apellido |
||
| Dirección | |||
| Teléfono | |||
| E Mail | |||
| Fax | |||
| Categoría | Código | ||
| Descripción | |||
| Observación |
Se observa que obtuvimos 3 Tablas conteniendo la información
más organizada. A manera de Ejercicio se sugiere que el lector "desmenuce"
las características para los Bodegueros y para las Bodegas.
Fase I : Atomización.
Atomizar es fragmentar, en nuestro caso "desmenuzar". Eso es lo que hicimos en la primera fase, analizamos los datos desde el punto de vista más amplio hasta fragmentarlo de tal manera que no se pueda dividir más. Por ejemplo Nombre no es un dato atomizado ya que lo podemos subdividir en Primer Nombre y Segundo Nombre; pero el Primer Nombre ya no podemos seguirlo dividiendo entonces ese dato se encuentra atomizado.
Fase II : Dependencia Funcional.
Dependencia es una derivación de Depender y un sinónimo de Subordinación, y es en este contexto que podemos analizar cuales datos dependen de otros datos. Por ejemplo :
De Producto tomemos Código y de Categoría tomemos Descripción y analicemos :
Producto ! Código ==> Categoría ! Descripción
Con esto le estamos preguntando que si la Descripción de la Categoría depende directamente de el Código del Producto, es obvio que NO por lo tanto podemos decir :
Producto ! Código =/=>Categoría ! Descripción
No hay dependencia funcional.
Ahora nótese que SI existe una dependencia funcional entre los siguientes :
Producto ! Código ==>Categoría ! Código
Repitamos este procedimiento tomando cada elemento hasta analizar su dependencia con el resto de los elementos. Esto nos permitirá agrupar los elementos con afinidades directas, reduciendo en algunos casos los elementos que contienen las tablas.
Fase III : Redundancia.
La fase de redundancia consiste en la eliminación de posible información que se repita en las tablas. Veamos un ejemplo :
En la tabla Producto encontramos el Código del Proveedor y el Nombre del Proveedor (independiente de que esté o no Atomizado) y también lo encontramos en la Tabla Proveedor; esto produce que los datos se repitan en ambas tablas, originándonos los siguientes inconvenientes :
Lentitud en la gestión de información
Consumo innecesario de espacio en el disco
Mala organización de los datos.
Para eliminar esto, los datos se agrupan en sus tablas y solamente dejamos
los elementos significativos en las otras tablas con las que tengan relación.
Por ejemplo, en la Tabla Proveedor dejamos todos los elementos relacionados
con el nombre del proveedor y sus datos, y en la tabla Producto
solamente dejamos su Código; de esta manera cuando hagamos referencia
a un Código de Proveedor en la tabla Producto conoceremos sus demás
datos.
 |
Lo anterior define el objetivo fundamental de la Normalización : La creación de Tablas que presenten la información organizada y relacionada. Esto también nos permite redefinir el Access, pero antes de que lo hagamos aclararemos que estas Tres fases de Normalización son más que suficientes para el nivel de gestión de información que requiere nuestro curso, así que dejaremos pendiente las otras dos fases por ser menos significativos en estos momentos. Ahora sí definamos Access.
Access : Gestor de Bases de Datos que utiliza el Modelo Relacional
para gestionar la información.
Para que dos tablas estén relacionadas debe existir un campo común en ellas. Una relación entre las tablas la podemos reconocer por una línea que las une, la línea parte de los campos comunes. Los tipos de Relaciones que existen entre las tablas son las siguientes :
En la figura 3 se establece una relación 1 a 1. Nótese que las tablas Cliente y Saldos están unidas por una línea que parte del campo común a ambas tablas.
Esta relación podría leerse de la siguiente manera :
| 1 Cliente TIENE 1 Saldo
o también como 1 Cliente ESTA en 1 Saldo
|
 |
En la figura 4 se establece la relación 1 a varios y se lee de
la siguiente manera :
| 1 Cliente TIENE muchas Facturas
O también como : 1 Cliente ESTA en muchas Facturas
|
 |
En las figuras siguientes veremos ejemplos de modelos relacionales completo
:
 |
 |
Durante el análisis y montaje de un sistema, el diseño
del modelo relacional es la parte fundamental para que el funcionamiento
del mismo sea el más óptimo.
 |