|
|
| Regístrate y recibe nuestro boletín | Recomiéndanos | Martes 26 / Feb / 2002 |
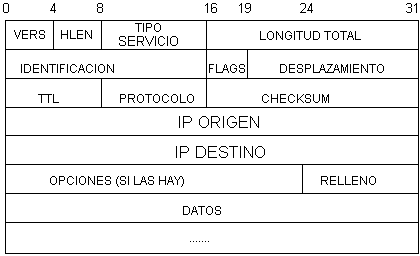
Por Antonio Mora Samper Diciembre 1998 1.Introducción Este proyecto es una parte de un gran proyecto que la Escola Universitaria Politécnica de Mataró ha emprendido con el objetivo de poder diseñar distintas redes con todos sus componentes. Estas redes podrán ser Ethernet, Token Ring en el caso de redes locales (LAN) y Frame Relay, RDSI, punto a punto etc... por lo que corresponde a Redes de área extensa, también conocidas como WAN. Sus componentes electrónicos, Hub, switches, Routers son partes vitales dentro de este proyecto y merecen un estudio muy detallado si queremos obtener resultados que se acerquen a la realidad. Por este motivo tanto el diseño y simulación de los componentes electrónicos como las distintas redes son proyectos individuales. 2.Objetivos Así pues el objetivo de este trabajo es el de diseñar y simular un ROUTER en el entorno de programación LLULL (P.A.D.D.), con el fin de poder evaluar su comportamiento en distintas redes antes de construirlas definitivamente. Esta simulación también nos permitirá poder configurar el Router y observar el rendimiento que es capaz de obtener en relación con sus características, como por ejemplo, el tamaño de las colas de entrada, el tiempo de acceso a la Tabla de reenvío, el tamaño de la memoria donde almacena las direcciones hardware de direcciones IP destino, etc. Todas estas observaciones nos acercarán mucho a la realidad de la red que vayamos a construir y de esta manera nos aseguraremos que ésta cumplirá los requisitos que se necesitan de antemano. La simulación es en PADD ya que este lenguaje de programación nos permite simular sistemas en paralelo y hardware con mucha facilidad. La utilización del ‘Entorno LLULL’ es debida a que éste ha desarrollado un entorno de programación en padd mas avanzado que el antiguo editor (edfd) y mas amable a la hora de trabajar con él. 3.Base Teórica En esta apartado se dan a conocer las características de un Router y los conocimientos indispensables para comprender su funcionamiento dentro de una red de redes. Hablaré de router refiriéndome al dispositivo que hace las funciones de enrutar datagramas y de anfitrión como la máquina que dentro de una red genera o recibe información. 3.1 Sistema de entrega sin conexión El servicio más importante de la red de redes consiste en un sistema de entrega de paquetes. Técnicamente, el servicio se define como un sistema de entrega de paquetes sin conexión y con el mejor esfuerzo, análogo al servicio proporcionado por el hardware de red que opera con un paradigma de entrega con el mejor esfuerzo. El servicio se conoce como no confiable porque la entrega no está garantizada. Los paquetes se pueden perder, duplicar, retrasar o entregar sin orden, pero el servicio no detectará estas condiciones ni informará al emisor o al receptor. El servicio es llamado sin conexión dado que cada paquete es tratado de manera independiente de todos los demás. Una secuencia de paquetes que se envían de una computadora a otra puede viajar por diferentes rutas, algunos de ellos pueden perderse mientras otros se entregan. Se dice que el servicio trabaja con base en una entrega con el mayor esfuerzo porque el software de red de redes hace un serio intento por entregar los paquetes. Esto es, la red de redes no descarta paquetes caprichosamente, la falta de confiabilidad aparece sólo cuando los recursos están agotados o la red subyacente falla. 3.2 El protocolo de Internet (IP) Es el protocolo que define el mecanismo de entrega sin conexión y no confiable. El protocolo IP proporciona tres definiciones importantes. Primero, define la unidad básica para la transferencia de datos utilizada a través de una red de redes TCP/IP. Es decir, especifica el formato exacto de todos los datos que pasarán a través de una red de redes TCP/IP. Segundo, el software IP realiza la función de ruteo, seleccionando la ruta por la que los datos serán enviados. Tercero, además de aportar especificaciones formales para el formato de los datos y el ruteo, el IP incluye un conjunto de reglas que le dan forma a la hora de entrega de paquetes no confiables. Las reglas caracterizan la forma en que los anfitriones y routers deben procesar los paquetes, cómo y cuando se deben generar los mensajes de error y las condiciones bajo las cuales los paquetes deben ser descartados. El IP es una parte fundamental del diseño de la red de redes TCP/IP. 3.2.1 El datagrama de Internet El parecido entre una red física y una red de redes TCP/IP es muy grande. En la red física la unidad de transferencia es una trama que contiene un encabezado y datos, donde el encabezado contiene información sobre la dirección de la fuente(física) y el destino. La red de redes llama a esta unidad de transferencia básica datagrama Internet, a veces datagrama IP o simplemente datagrama. Como una trama común de red física, un datagrama se divide en áreas de encabezado y datos. También como una trama, el encabezado del datagrama contiene la dirección de la fuente y del destino. La diferencia es que le encabezado contiene direcciones IP en tanto que el encabezado de la trama contiene direcciones físicas. 3.2.2 Encapsulación de datagramas La idea de transportar un datagrama dentro de una trama de red es conocida como encapsulación. Para la red subyacente un datagrama es como cualquier otro mensaje que se envía de una máquina a otra. El hardware no reconoce el formato del datagrama ni entiende las direcciones de destino IP. Así, cuando una máquina envía un datagrama IP hacía otra, el datagrama completo viaja en la porción de datos de la trama de red. 3.2.3 Formato del datagrama Una vez descrita la posición general del datagrama IP se puede observar su contenido con mayor detalle (figura 3.3).
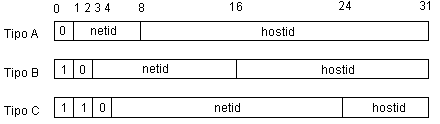
Figura 3.3. Formato del Datagrama IP Debido a que el proceso de datagramas se da en el software, el contenido y el formato no está condicionado por ningún tipo de hardware. Por ejemplo, el primer campo de 4 bits en un datagrama (Vers) contiene la versión del protocolo IP que se utilizó para crear el datagrama. Todo software IP debe verificar el campo de versión antes de procesar un datagrama para asegurarse de que el formato corresponde al tipo de formato que espera el software. Si hay una cambio de estándar, las máquinas rechazarán los datagramas con versiones de protocolo que difieren del estándar, evitando con ello que el contenido de los datagramas sea mal interpretado debido a un formato obsoleto. El protocolo actual IP trabaja con la versión número 4. El campo de longitud encabezado(HLEN), también de 4 bits, proporciona el encabezado del datagrama con una longitud media de 32 bits. Todos los campos del encabezado tienen longitudes fijas excepto para el campo OPTIONS. El encabezado más común, que no contiene opciones ni rellenos, mide 20 octetos y tiene un campo de longitud de encabezado igual a 5. El campo TOTAL LENGTH proporciona la longitud del datagrama IP medido en octetos, incluyendo los octetos del encabezado y los datos. El tamaño del área de datos se puede calcular restando la longitud del encabezado(HLEN) de TOTAL LENGTH. Dado que el campo TOTAL LENGTH tiene una longitud de 16 bits, el tamaño máximo posible de un datagrama IP es de 216 o 65,535 octetos. En la mayor parte de las aplicaciones, ésta no es una limitación severa, pero puede volverse una consideración importante en el futuro, si las red de redes de alta velocidad llegan a transportar paquetes de datos superiores a los 65,535 octetos. El campo TIME TO LIVE especifica la duración, en segundos, del tiempo que el datagrama tiene permitido permanecer en el sistema de red de redes. La idea es sencilla e importante: cada vez que una máquina introduce un datagrama en la red de redes, se establece un tiempo máximo durante el cual el datagrama puede permanecer ahí. Los routers y los anfitriones que procesan los datagramas deben decrementar el campo TIME TO LIVE cada vez que pasa un datagrama y eliminarlo de la red de redes cuando su tiempo ha concluido. Una estimación exacta de este tiempo es difícil dado que los routers por lo general no conocen el tiempo de tránsito por las redes físicas. Unas pocas reglas simplifican el procedimiento y hacen fácil el manejo de datagramas sin relojes sincronizados. En primer lugar, cada router, a lo largo de un trayecto, desde una fuente hasta un destino, es configurado para decrementar en 1 el campo TIME TO LIVE cuando se procesa el encabezado del datagrama. Sin embargo, para manejar casos de routers sobrecargados que introducen largos retardos, cada router registra el tiempo local cuando llega un datagrama, y decrementa el TIME TO LIVE por el numero de segundos que el datagrama permanece dentro del router esperando que se le despache. Cada vez que un campo TIME TO LIVE llega a cero, el router descarta el datagrama y envía un mensaje de error a la fuente. La idea de establecer un temporizador para los datagramas es interesante ya que garantiza que los datagramas no viajarán a través de la red de redes indefinidamente, aun cuando si una tabla de ruteo se corrompa y los routers direccionen datagramas en un ciclo. El campo PROTOCOL es análogo al campo tipo en una trama de red. El valor en el campo PROTOCOL especifica qué protocolo de alto nivel se utilizó para crear el mensaje que se está transportando en el área DATA de un datagrama. En esencia, especifica el formato del área de datos. La transformación entre un protocolo de alto nivel y el valor entero utilizado en el campo PROTOCOL debe administrarlo por una autoridad central para garantizar el acuerdo entre los enteros utilizados en Internet. El campo HEADER CHECKSUM asegura la integridad de los valores del encabezado. La suma de verificación IP se forma considerando al encabezado como una secuencia de enteros de 16 bits(en el orden de los octetos de la red), sumándolos juntos mediante el complemento aritmético a uno, y después tomando el complemento a uno del resultado. Para propósitos de calculo de la suma de verificación, el campo HEADER CHECKSUM se asume como igual a cero. La suma de verificación sólo se aplica para valores del encabezado IP y no para los datos. Debido a que el encabezado por lo general ocupa menos octetos que los datos, tener una suma separada disminuye el tiempo de procesamiento y ruteo, los cuales sólo necesitan calcular la suma de verificación del encabezado. La separación también permite a los protocolos de alto nivel seleccionar su propio esquema de suma de verificación para los datos. La mayor desventaja es que los protocolos de alto nivel se ven forzados a añadir su propia suma de verificación o corren riesgo de que las alteraciones de datos no sean detectadas. Los campos SOURCE IP ADDRESS y DESTINATION IP ADDRESS contienen direcciones IP de 32 bits del los datagramas del emisor y del receptor involucrado. Aun cuando los datagramas sean dirigidos a través de muchos routers inmediatos, los campos de fuente y destino nunca cambian; éstos especifican la dirección IP de la fuente original y del destino final. El campo DATA muestra el comienzo del área de datos de un datagrama. Su longitud depende, por supuesto, de qué es lo que está enviando en le datagrama. El campo OPTIONS de IP que se analiza tiene una longitud variable. El campo señalado como PADDING depende de las opciones seleccionadas. Este representa un grupo de bits puestos en cero que podrían ser necesarios para asegurar que la extensión del encabezado sea múltipla exacto de 32 bits. 3.3 Tipos primarios de direcciones IP Conceptualmente cada dirección IP es una par(netid, hostid), donde netid es la identificación de la red y hostid la del anfitrión dentro de la red. En la práctica, cada dirección IP debe de tener una de las tres formas mostradas en la figura 3.4.
Figura 3.4 Las tres formas primarias se pueden distinguir por medio de los tres primeros bits. La ventaja de dividir una dirección IP en dos partes surge del tamaño de las tablas ruteo que necesitan los routers. En vez de almacenar un registro de ruteo para cada anfitrión de destino, un router puede tener un registro por cada red y examinar sólo la porción de red de la dirección destino cuando tome decisiones de ruteo. Este primer diseño de direcciones IP se encontró con un problema, el crecimiento. Debido a que los diseñadores trabajaban en un mundo de computadoras mainframe caras, visualizaron una red con cientos de redes y miles de anfitriones. No pensaron en las decenas de miles de redes pequeñas de computadoras personales que aparecerían de manera repentina en los años siguientes al diseño del TCP/IP. La solución más empleada hoy en día se conoce como direccionamiento de subred. 3.4 Direccionamiento de Subred. La manera más sencilla de entender el direccionamiento de subredes imaginándose que una localidad tiene asignada una sola dirección de red tipo B, pero tiene dos o más redes físicas. Sólo los routers locales saben que existen muchas redes físicas y cómo rutear el tráfico entre ellas. Los routers en otros sistemas autónomos rutean todo el tráfico como si sólo hubiera una red física. Para regular este nuevo direccionamiento existe un estándar que especifica que una localidad que utiliza el direccionamiento de subred, debe escoger una máscara de subred de 32 bits para cada red. Los bits en la máscara de subred se indican como 1, si la red trata al bit correspondiente de la dirección IP como parte de la dirección de red, y se indican como 0, si se trata al bit como parte del identificador de anfitrión. Por ejemplo, la máscara de subred de 32 bits: 11111111.11111111.11111111.00000000 especifica que los tres primeros octetos identifican a la red y el cuarto a un anfitrión en dicha red. Una máscara de subred debe tener 1 para todos los bits que correspondan a la porción de red de la dirección(por ejemplo, la máscara de subred para una red de tipo B tendrá 1 los primeros dos octetos y adicionalmente uno o más bits en los dos últimos). Este giro interesante de subred surge porque el estándar no restringe a las máscaras de subred para que seleccionen bits contiguos de la dirección. Por ejemplo, una red puede tener asignada la máscara: 11111111.11111111.00011000.01000000 La cual selecciona los primeros dos octetos, dos bits del tercero y un bit del cuarto. Aunque tal flexibilidad hace posible que se puedan realizar asignaciones interesantes de direcciones, también causa que la asignación de direcciones de anfitrión y que el entendimiento de las tablas de ruteo sea un poco confuso. 3.5 Ruteo en una red de redes En un sistema de conmutación de paquetes, el ruteo es el proceso de selección de una camino sobre el que se mandarán paquetes y el router es la computadora que hace la selección. El ruteo ocurre a muchos niveles. Por ejemplo, dentro de una red de área amplia que tiene muchas conexiones físicas entre conmutadores de datos, la red por sí misma es responsable de rutear paquetes desde que llegan hasta que salen. Dicho ruteo interno está completamente contenido dentro de la red de área amplia. Las máquinas del exterior no pueden participar en las decisiones, sólo se ven como una unidad que entrega paquetes. El ruteo IP selecciona un camino por el que se debe enviar un datagrama, el algoritmo de ruteo IP debe escoger cómo enviar un datagrama pasando por muchas redes físicas. El ruteo en una red de redes puede ser difícil, en especial entre computadoras que tienen muchas conexiones físicas de red. De forma ideal, el software de ruteo examinará aspectos como la carga de la red, la longitud del datagrama o el tipo de servicio que se especifica en el encabezado del datagrama, para seleccionar el mejor camino. Sin embargo, la mayor parte del software de ruteo en red de redes es mucho menos sofisticado y selecciona rutas basándose en suposiciones sobre los caminos más cortos. 3.6 Entrega directa y indirecta Podemos dividir el ruteo en dos partes: Entrega directa y entrega indirecta. La entrega directa, que es la transmisión de un datagrama desde una máquina a través de una sola red física hasta otra, es la base de toda la comunicación en una red de redes. Dos máquinas solamente pueden llevar a cabo la entrega directa si ambas se conectan directamente al mismo sistema subyacente de transmisión física(por ejemplo una sola Ethernet). La entrega indirecta ocurre cuando el destino no es una red conectada directamente, lo que obliga al transmisor a pasar el datagrama a un router para su entrega. Así pues los protocolos de red envían los paquetes a una única estación, si no pueden acceder directamente, envían el paquete a un Router. Pero, ¿cómo sabe el transmisor si el destino reside en una red directamente conectada? La respuesta es la siguiente: Las direcciones IP se dividen en un prefijo específico de red y un sufijo específico de anfitrión. Para averiguar si un destino reside en una de las redes directamente conectadas, el transmisor extrae la porción de red de la dirección IP de destino y la compara con la porción de red de su propia dirección IP. Si corresponde, significa que el datagrama se puede enviar de manera directa. Aun si el datagrama atraviesa muchas redes y routers intermedios, el último router del camino entre la fuente del datagrama y el destino siempre se conectará directamente a la misma red física que la máquina destino. Por lo tanto, el último router entregará el datagrama utilizando la entrega directa. La entrega indirecta es más complicada que la directa porque le transmisor debe identificar un router para enviar el datagrama. Luego, el router debe encaminar el datagrama hacia la red destino. 3.6.1 ¿Cómo las estaciones y los Routers conocen las direcciones MAC o las rutas? Cuando una estación o Router quiere enviar un Datagrama, debe seguir unos pasos antes de decidir hacia donde o para hacia quien debe enviarlo. 3.7 Tablas de reenvío Los routers contienen una tabla en la que encuentran la información necesaria para reenviar el datagrama por el camino correcto, estas tablas son conocidas como tablas de reenvío, tablas de ruteo o tablas de forwarding (del término reenvío en inglés). Estas tablas guardan información de cómo llegar hasta la red destino, no contienen información para cada anfitrión sino que sólo informan de cómo alcanzar la red donde esta situado el anfitrión. Esto es debido a que sino las tablas tendrían tamaños demasiado grandes y todo el proceso de reenvío se ralentizaría. Además, sólo enviando el datagrama hacia el router que se encuentra en la red del anfitrión destino, éste ya se encarga de entregárselo individualmente. Esta información la encuentran gracias a los diferentes registros que tiene la tabla, estos registros son:
En la dirección IP se encuentra la dirección IP de la red a la que queremos llegar. La máscara es la de la anterior red, la dirección IP del salto siguiente corresponde con la dirección IP del siguiente router de la ruta, y la interficie es el número de la interficie por la que ha de salir el datagrama para encontrar el router. Por lo tanto la tabla de ruteo sólo especifica un paso a lo largo del camino desde el router a su red de destino, el router no conoce el camino completo hacia el destino. Es importante entender que cada registro de la tabla de ruteo apunta hacia un router que se puede alcanzar a través de una sola red. Esto significa que todos los routers listados en la tabla de ruteo del router M deben residir en las redes con las que M se conecta de manera directa. Cuando un datagrama esta listo para dejar M, el software IP localiza la dirección IP de destino y extrae la porción de red. Luego, M utiliza la porción de red para tomar una decisión de ruteo, seleccionando un router que se pueda alcanzar directamente. En la figura 3.6 se muestra un ejemplo concreto. La red de redes ejemplificada consiste en cuatro redes conectadas por tres routers. En la figura 3.6 la tabla de ruteo proporciona las rutas que utiliza el router R.
Figura 3.6 Existen tres tipos de tablas:
3.8 ¿Qué es un Router? Hasta el momento he hablado de routers como dispositivos que encaminan datagramas dentro de una red de redes sin detenerme mucho en sus características. Ahora es el momento de entrar más en detalle en el dispositivo en concreto, y de cómo realiza todo lo que anteriormente he asumido. Empiezo a contestar esta pregunta con las siguientes definiciones: [6]. Router: Un Router es un conmutador que recibe unidades de transmisión de datos desde interfaces de entrada y, dependiendo de las direcciones de esas unidades, el Router las guía hacia las correspondientes interfaces de salida. Estos pueden ser de diferentes niveles de protocolos. Por ejemplo, ‘Interfaces Message Processors’ (IMPs) son Routers de nivel de paquetes. Paquete: Unidad de transmisión de nivel físico. Gateway: En la documentación general de Internet, un Gateway es un Router de nivel IP. En la comunidad de Internet el término tiene una larga historia con este uso. [4] Router: En el modelo de Internet, las redes están interconectadas por encaminadores de datagramas IP llamados Routers. Algunos antiguos documentos de Internet se referían a estos como Gateways. Un Router conecta dos ó más interficies lógicas, representadas por subredes IP ó innumerables líneas punto a punto. Enviar un datagrama IP generalmente necesita la elección de una dirección y la interficie del siguiente Router o host destino. Esta elección llamada reenvío(forwarding) depende de una base de datos de rutas que posee el Router. La base da datos del Router es también llamada tabla de ruteo o de reenvío. El término Router deriva del proceso de construcción de esta base de datos; protocolos de ruteo y configuración interactuan en un proceso llamado ruteo(routing). La tabla de ruteo debe ser mantenida dinámicamente para reflejar la topología del sistema de Internet que corre. Un Router, normalmente cumple esto participando en ruteo distribuido y algoritmos de alcance de otros Routers. Router: Computadora dedicada de propósito especial que conecta diferentes redes. Los Routers conmutan paquetes entre esas redes en un proceso conocido como reenvío(forwarding). Este proceso puedes ser repetido muchas veces en un mismo paquete por múltiples Routers antes que el paquete pueda ser enviado al destino final conmutando el paquete desde un Router a otro Router y a otro... hasta que el paquete llega a su destino. [3] Router: Computadora dedicada, de propósito especial, que se conecta a dos ó más redes y envía paquetes de una a otra red. En particular, un router IP envía datagramas IP entre las redes a las que esta conectado. Un router utiliza la dirección de destino en un datagrama para decidir el próximo salto al que enviará el datagrama. Los investigadores utilizan el término compuerta IP. [10] Router: Dispositivo de red que conecta dos redes de computadoras. Usa un protocolo de Internet y asume que todos los dispositivos conectados a la red usan la misma arquitectura de red y protocolos. Un Router opera en la capa tres del modelo OSI. Conclusión: Un Router es un dispositivo que interconecta redes al nivel de capa de red. Para ello utiliza datagramas IP, de donde obtiene las direcciones de red ó subred, y encamina los datagramas basándose en una tabla de enrutado. Esta tabla puede ser estática o dinámica y refleja el estado de las redes a las que esta conectado. Debe ser actualizada periódicamente, para ello utilizan protocolos de enrutado y diálogo entre Routers. La conexión con las redes las hace mediante interficies. Un Router puede tener dos ó más interficies según las necesidades. 3.9 Características de un Router. Un Router debe tener las siguientes características:
Antonio Mora Samper Ingeniero técnico en telecomunicaciones |

 Envíanos un e-mail a: |
Contacta con nosotros: Colaboraciones: colaboraciones@canalti.com Publicidad: publicidad@canalti.com Soporte: ayuda@canalti.com © Copyright CanalTI.com, Barcelona, 2001 http://www.canalti.com |