Unidad II. Comunicación entre procesos
Descargar archivo utilizado en clase
(comunicaciones_primera_parte.pdf)
NOTA: para el exámen del día lunes 19 de septiembre no solo es la unidad II, también incluye los temas: multiprocesadores con comutador y multiprocesadores con red omega.
2.1 Panorama de las comunicaciones
Si varias máquinas están interconectadas por medio de una red, los usuarios tienen la posibilidad de intercambiar información. A través del pasaje de mensajes la funcionalidad en una máquina independiente se puede ampliar a un sistema distribuido. Algunos de los beneficios que podemos obtener son la transferencia de archivos y el uso del correo.
a ventaja de un sistema operativo distribuido es que muchas de las funciones mencionadas pueden efectuarse a grandes distancias. Dos personas en diferentes zonas geográficas pueden trabajar en un mismo proyecto. Con la transferencia de archivos se pueden transferir programas e intercambiar correspondencia para coordinar el trabajo.
Introducción a la comunicación en los sistemas distribuidos
La diferencia más importante entre un sistema distribuido y un sistema de único procesador es la comunicación entre procesos.
En un sistema de un solo procesador la comunicación supone implícitamente la existencia de la memoria compartida:
Ejemplo: Problema de los productores y los consumidores, donde un proceso escribe en un buffer compartido y otro proceso lee de él.
En un sistema distribuido no existe la memoria compartida y por ello toda la naturaleza de la comunicación entre procesos debe replantearse.
Los procesos para comunicarse, deben apegarse a reglas conocidas como protocolos.
Para los sistemas distribuidos en un área más amplia, estos protocolos toman frecuentemente la forma de varias capas y cada capa tiene sus propias metas y reglas.
Los mensajes se intercambian de diversas formas, existiendo muchas opciones de diseño al respecto; una importante opción es la "llamada a un procedimiento remoto".
También es importante considerar las posibilidades de comunicación entre grupo de procesos, no solo entre dos procesos.
Notas:
- Sistema de comunicación: Espina dorsal del SD.
- Modelos de comunicación entre procesos:
- Memoria compartida: no factible, en principio (DSM), en SD
- Paso de mensajes.
- Nivel de abstracción en comunicación con paso de mensajes:
- Paso de mensajes puro.
- Llamadas a procedimientos remotos.
- Modelos de objetos distribuidos.
- Arquitectura de comunicaciones
- Modelo cliente/servidor
- con proxy o caché
- múltiples capas
- código móvil
- Modelo peer-to-peer
Modelo cliente/servidor
Dos roles diferentes en la interacción:
- Cliente: Solicita servicio. Petición: Operación + Datos
- Servidor: Proporciona servicio. Respuesta: Resultado
Modelo con proxy o caché
Tres roles diferentes en la interacción:
- Cliente: Solicita servicio.
- Servidor: Proporciona servicio.
- Proxy: Intermediario (si tiene memoria se denomina caché)

Modelo multicapa
- Servidor puede ser cliente de otro servidor
- Típico en aplicaciones web:
- Presentación + Lógica de negocio + Acceso a datos
- En Microsoft: ASP + COM + ADO
- En Java: JSP + EJB + JDBC
Código móvil
- Modelo cliente/servidor alternativo:
- Viaja" el código en vez de los datos.
- Requiere máquinas homogéneas o "Máquinas virtuales": (ej. applet).
- Problemas de seguridad.
- Agentes móviles:
- Programa que viaja por el SD realizando una tarea.
- En cada nodo procesa datos locales.
- Se transfiere programa en vez de datos.
- Ejemplo: Data mining en base de datos distribuida
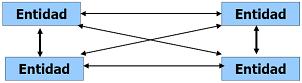
Modelo peer-to-peer
- Un único rol: Entidad
- Protocolo de diálogo:
- Entidades se coordinan entre sí.
- Ejemplo: simulación paralela, al final de cada etapa las entidades se sincronizan e intercambian información

2.2 Comunicación a través de mensajes
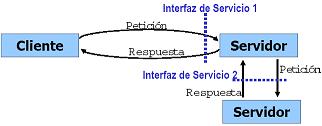
El "modelo cliente-servidor" se basa en un "protocolo solicitud/respuesta":
Es sencillo y sin conexión.
- No es complejo y orientado a la conexión como OSI o TCP/IP.
- El cliente envía un mensaje de solicitud al servidor pidiendo cierto servicio.
- El servidor:
- Ejecuta el requerimiento.
- Regresa los datos solicitados o un código de error si no pudo ejecutarlo correctamente.
- No se tiene que establecer una conexión sino hasta que ésta se utilice.
- La pila del protocolo es más corta y por lo tanto más eficiente.
- Si todas las máquinas fuesen idénticas solo se necesitarían tres niveles de protocolos.
Direccionamiento en C-S
Para que un cliente pueda enviar un mensaje a un servidor, debe conocer la dirección de éste.
Un esquema de direccionamiento se basa en la dirección de la máquina destinataria del mensaje: es limitativo si en una máquina destinataria se ejecutan varios procesos, pues no se sabría para cuál de ellos es el mensaje.
Primitivas SEND y RECEIVE
El envío de un mensaje a un grupo no se puede modelar como una llamada a un procedimiento. Con la comunicación en grupo existen en potencia "n" respuestas diferentes y no resulta aplicable el esquema de RPC.
Se utilizan llamadas explícitas para el envío y recepción (modelo de un solo sentido).
Si se unifican las primitivas puntuales y grupales para send:
- Uno de los parámetros indica el destino:
- Si es una dirección de un proceso, se envía un único mensaje a ese proceso en particular.
- Si es una dirección de grupo (o un apuntador a una lista de destinos). Se envía un mensaje a todos los miembros del grupo.
- Un segundo parámetro apunta al mensaje por enviar:
Si se fusionan las primitivas puntuales y grupales para receive:
- La operación concluye cuando llega un mensaje puntual o un mensaje de grupo.
Si es necesario que las respuestas estén asociadas a solicitudes previas:
- Se envía un mensaje.
- Se efectúa varias veces un proceso get_reply para recolectar todas las respuestas, una a la vez.
Aspectos del diseño de sistemas con transferencia de mensajes:
Como protección contra la pérdida de mensajes en la red, el emisor y el receptor pueden convenir en que tan pronto se reciba el mensaje, el receptor envíe de regreso un mensaje especial de confirmación. Si el emisor no ha recibido una confirmación después de cierto tiempo, retransmite el mensaje.
Los sistemas con mensajes también deben enfrentar la cuestión de los nombres de los procesos, de forma que no haya ambigüedad en el proceso dado en una llamada SEND o RECEIVE. Con frecuencia se utiliza un esquema tal como "proceso@maquina" o "maquina:proceso".
Si el número de máquinas es muy grande y no existe una autoridad central que establezca los nombres de las máquinas, podría ocurrir que dos máquinas tuvieran el mismo nombre. La posibilidad de conflictos se puede reducir en forma considerable al agrupar las máquinas en dominios y dirigirse a los procesos como "proceso@maquina.dominio". En este esquema no hay problema si dos máquinas tienen el mismo nombre, siempre que estén en dominios diferentes. El nombre del dominio también debe ser único.
La autentificación también es otro aspecto de los sistemas con mensajes, en este punto, puede ser de utilidad el ciframiento de mensajes con una clave que solo conozcan los usuarios autorizados.
También existen aspectos importantes del diseño en el caso que el emisor y el receptor se encuentren en la misma máquina, uno de los cuales es el desempeño del sistema. El copiar mensajes de un proceso a otro siempre es más lento que la realización de una operación de semáforo o la entrada a un monitor. Se ha trabajo mucho para lograr que la transferencia de mensajes sea eficaz.
El problema del productor y el consumidor con transferencia de mensajes
Existen muchas variantes para la transferencia de mensajes. Una forma consiste en asignar a cada proceso una dirección única y que las direcciones de los mensajes estén ligadas a procesos. Otra alternativa es inventar una nueva estructura de datos llamada buzón. Un buzón es un lugar donde almacenar un número determinado de mensajes, los cuales se especifican al crear el buzón. Al utilizar los buzones, los parámetros de dirección en las llamadas SEND y RECEIVE son buzones, no procesos. Cuando un proceso intente enviar un mensaje a un buzón completamente ocupado, se suspende hasta que se elimina un mensaje de dicho buzón. Al utilizar buzones, el mecanismo de almacenamiento de destino pero tales que no hayan sido aceptados todavía.
El caso opuesto al uso de buzones es la eliminación del almacenamiento. Desde ese punto de vista, si se ejecuta SEND antes de RECEIVE, el proceso emisor se bloquea hasta la ejecución de RECEIVE, momento en el que el mensaje se puede copiar en forma directa del emisor al receptor sin almacenamiento intermedio. En forma análoga, si se ejecuta primero RECEIVE, el receptor se bloquea hasta que se ejecute SEND. Esta estrategia se conoce como "rendezvous". Es más fácil de implantar que el esquema de mensajes almacenados; pero es menos flexible, puesto que el emisor y receptor se ven forzados a ejecutarse al mismo paso.
La comunicación entre procesos del usuario de UNIX se lleva a cabo mediante tubos que en realidad son buzones. La única diferencia real entre un sistema de mensajes con buzones y el mecanismo de tubos es que estos no preservan las fronteras de los menajes. En otras palabras, si un proceso escribe 10 mensajes de 100 bytes en un tubo y otro proceso lee 1000 bytes de ese tubo, el lector obtendrá 10 mensajes de una sola vez. Con un sistema real de mensajes, cada READ debe regresar solo un mensaje.
Equivalencia de primitivas
Existe otro método de comunicación entre procesos llamado de secuenciadores descrito por Reed y Kanodia en el año de 1979. Campbell y Habermann en 1974 analizaron el método de expresiones de trayectorias. Atkinson y Hewitt en 1979 introdujeron los serializadores. Aunque la lista de métodos distintos no es infinita, ciertamente es larga, además, todo el tiempo se sueña con alguna de ellas.
A través de los años, cada uno ha acumulado simpatizantes, los cuales afirman que el mejor método es el suyo. La verdad es que todos los métodos son en esencia equivalentes desde el punto de vista de la semántica. Se puede utilizar cualquiera de ellos para construir los demás.
2.3 Llamada a procedimientos remotos (RPC)
El modelo cliente-servidor es una forma conveniente de estructurar un sistema operativo distribuido, pero posee una falencia:
- El paradigma esencial en torno al que se construye la comunicación es la e/s.
- Los procedimientos send / receive están reservados para la realización de e/s.
Una opción distinta fue planteada por Birrel y Nelson:
- "Permitir a los programas que llamasen a procedimientos localizados en otras máquinas".
- Cuando un proceso en la máquina "A" llama a un procedimiento en la máquina B":
- El proceso que realiza la llamada se suspende.
- La ejecución del procedimiento se realiza en "B".
- La información se puede transportar de un lado al otro mediante los parámetros y puede regresar en el resultado del procedimiento.
- El programador no se preocupa de una transferencia de mensajes o de la e/s.
- A este método se le denomina llamada a procedimiento remoto o RPC.
- El procedimiento que hace la llamada y el que la recibe se ejecutan en máquinas diferentes, es decir que utilizan espacios de direcciones distintos.
Operación básica de RPC
Una llamada convencional a un procedimiento, es decir en una sola máquina, funciona de la siguiente manera:
- Fd es un entero; buf es un arreglo de caracteres; nbytes es otro entero.
- Coloca el valor de regreso en un registro.
- Elimina la dirección de regreso.
- Transfiere de nuevo el control a quien hizo la llamada.
Quien hizo la llamada elimina los parámetros de la pila y regresa a su estado original.Los parámetros pueden llamarse por valor o por referencia.
Un parámetro por referencia:
Otro mecanismo para el paso de parámetros es la llamada por copiar/restaurar:
- Quien recibe la llamada copia la variable en la pila, como en la llamada por valor.
- La copia de nuevo después de la llamada, escribiendo sobre el valor original.
Fallos del cliente
La cuestión es qué ocurre si un cliente envía una solicitud a un servidor y falla antes de que el servidor responda.
Se genera una solicitud de trabajo o cómputo que al fallar el cliente ya nadie espera; se dice que se tiene un cómputo huérfano.
Los principales problemas generados por cómputos huérfanos son los siguientes:
- Desperdicio de ciclo de CPU.
- Posible bloqueo de archivos.
- Apropiación de recursos valiosos.
- Posible confusión cuando:
- El cliente rearranca y efectúa de nuevo la RPC.
- La respuesta del huérfano regresa inmediatamente luego.
Las soluciones a los cómputos huérfanos son las siguientes:
- Exterminación:
- Se crea un registro que indica lo que va a hacer el resguardo del cliente antes de que emita la RPC.
- El registro se mantiene en disco.
- Luego del rearranque se verifica el contenido del registro y se elimina el huérfano explícitamente.
- La desventaja es la sobre carga en e/s generada por la grabación previa a cada RPC.
- Fallaría si los huérfanos generan RPC, creando huérfanos de huérfanos:
- Sería imposible localizarlos.
- Ante ciertos fallos en la red sería imposible eliminarlos aunque se los localice.
- Reencarnación:
- Resuelve los problemas anteriores sin necesidad de escribir registros en disco.
- Consiste en dividir el tiempo en épocas numeradas de manera secuencial.
- Cuando un cliente rearranca envía un mensaje a todas las máquinas declarando el inicio de una nueva época.
- Al recibirse estos mensajes se eliminan todos los cómputos remotos.
- Si se divide la red mediante particiones por fallas, podrían sobrevivir ciertos huérfanos:
- Cuando se reconecten y vuelvan a reportarse sus respuestas contendrán un número de época obsoleto y se los podrá detectar y eliminar.
- Reencarnación sutil:
- Cuando llega un mensaje de cierta época:
- Cada máquina verifica si tiene cómputos remotos:
- En caso afirmativo intenta localizar a su poseedor.
- Si no se localiza al poseedor se elimina el cómputo.
- Expiración:
- A cada RPC se le asigna una cantidad estándar de tiempo "t" para que realice su trabajo.
- Si el tiempo es insuficiente debe pedir explícitamente otro quantum, pero esto es un inconveniente.
- Si luego del fallo el servidor espera "t" antes de rearrancar, todos los huérfanos habrán desaparecido.
- El problema es elegir un "t" razonable, ya que pueden existir RPC con requisitos diversos.
2.4 Comunicación a través de transacciones
Un proceso anuncia que desea comenzar una transacción con uno o más procesos. Puede negociar varias opciones, crear y eliminar ciertos objetos y llevar a cabo ciertas operaciones durante unos momentos. Entonces el iniciador anuncia que todos los demás se comprometan con el trabajo realizado hasta entonces.
Si todos coinciden, los resultados se vuelven permanentes. Si uno o más procesos se niegan (o fallan antes de expresar su acuerdo), entonces la situación regresa al estado que presentaba antes de comenzar la transacción, sin que existan efectos colaterales en los objetos, archivos, bases de datos, etc. Esta propiedad del todo o nada facilita el trabajo del programador.
La comunicación es por lo general no confiable en el sentido de que se pueden perder mensajes, pero los niveles inferiores pueden utilizar un protocolo de tiempos de espera y retransmisión.
Primitivas de transacción
La programación con uso de transacciones requiere de primitivas especiales, las cuales deben ser proporcionadas por el sistema operativo o por el compilador del lenguaje:
- BEGIN_TRANSACTION: Señala el inicio de una transacción.
- END_TRANSACTION: Termina la transmisión y se intenta un compromiso.
- ABORT_TRANSACTION: Se elimina la transacción; se recuperan los valores anteriores.
- READ: Se leen los datos de un archivo (o algún otro objeto).
- WRITE: Se escriben los datos de un archivo (o algún otro objeto).
Atomicidad
La mayoría de los sistemas de comunicación en un grupo están diseñados para que los mensajes enviados al grupo lleguen correctamente a todos los miembros o a ninguno de ellos:
- Esta propiedad de "todo o nada" en la entrega se llama atomicidad o transmisión atómica.
- Facilita la programación de los sistemas distribuidos.
- Es de gran importancia para garantizar la consistencia de las bases de datos y de los archivos distribuidos y duplicados.
La única forma de garantizar que cada destino recibe todos sus mensajes es pedirle que envíe de regreso un reconocimiento después de recibir el mensaje:
- Esto funciona si las máquinas no fallan.
- Si fallan:
- Algunos miembros del grupo habrán recibido el mensaje y otros no; esto es inaceptable.
- Los miembros que no recibieron el mensaje ni siquiera saben que les falta algo, por lo que no pedirán una retransmisión; además, si pudieran detectar el faltante pero fallara el emisor, no podrán recibir el mensaje.
2.5 Comunicación, interprocesos y manejo de memoria (Comunicación en grupo)
Una hipótesis subyacente e intrínseca de RPC es que la comunicación solo es entre dos partes: el cliente y el servidor.
A veces existen circunstancias en las que la comunicación es entre varios procesos y no solo dos:
- Ejemplo: un grupo de servidores de archivo que cooperan para ofrecer un único servicio de archivos tolerante a fallos:
- Sería recomendable que un cliente envíe el mensaje a todos los servidores para garantizar la ejecución de la solución aunque alguno falle.
- RPC no puede controlar la comunicación de un servidor con muchos receptores, a menos que realice RPC con cada uno en forma individual.
Un grupo es una colección de procesos que actúan juntos en cierto sistema o alguna forma determinada por el usuario.
La propiedad fundamental de todos los grupos es que cuando un mensaje se envía al propio grupo, todos los miembros del grupo lo reciben.
Se trata de una comunicación uno - muchos (un emisor, muchos receptores), que se distingue de la comunicación puntual o punto a punto (un emisor, un receptor).
Los grupos son dinámicos:
- Se pueden crear y destruir.
- Un proceso se puede unir a un grupo o dejar a otro.
- Un proceso puede ser miembro de varios grupos a la vez.
La implantación de la comunicación en grupo depende en gran medida del hardware:
- En ciertas redes es posible crear una dirección especial de red a la que pueden escuchar varias máquinas:
- Cuando se envía un mensaje a una de esas direcciones se lo entrega automáticamente a todas las máquinas que escuchan a esa dirección.
- Esta técnica se denomina multitransmisión.
- Cada grupo debe tener una dirección de multitransmisión distinta.
Grupos cerrados Vs. Grupos abiertos
En los grupos cerrados:
- Solo los miembros del grupo pueden enviar hacia el grupo.
- Los extraños no pueden enviar mensajes al grupo como un todo, peor pueden enviar mensajes a miembros del grupo en lo individual.
En los grupos abiertos:
- Cualquier proceso del sistema puede enviar a cualquier grupo.
Los grupos cerrados se utilizan generalmente para el procesamiento paralelo:
- Ejemplo: un conjunto de procesos que trabajan de manera conjunta, tienen su propio objetivo y no interactúan con el mundo exterior.
Notas:
- Un proceso pertenece a un grupo por su naturaleza propia.
- Si no se lleva un control puede: provocar caos, inestabilidades del sistema, falla total, etc.
- Destino de mensaje es un grupo de procesos: multidifusión.
- Posibles usos en los sistemas distribuidos:
- Uso de datos replicados: actualizaciones múltiples.
- Uso de servicios replicados.
- Operaciones colectivas en cálculo paralelo.
- Implementación depende de si red proporciona multicast:
- Si no, se implementa enviando N mensajes
- Un proceso puede pertenecer a varios grupos.
- Existe una dirección de grupo.
- El grupo suele tener carácter dinámico.
- Se pueden incorporar y retirar procesos del grupo.
- Gestión de pertenencia debe coordinarse con la comunicación
Aspectos de diseño en la comunicación en grupos
Modelos de grupos:
Grupo abierto :
- Proceso externo puede mandar mensaje al grupo
- Suele usarse para datos o servicios replicados
Grupo cerrado :
- Sólo procesos del grupo pueden mandar mensajes.
- Suele usarse en procesamiento paralelo (modelo peer-to-peer)
Atomicidad:
- O reciben todos los procesos el mensaje o ninguno.
Orden de recepción de los mensajes: tres alternativas:
- Orden FIFO: Los mensajes de una misma fuente llegan a cada receptor en el orden que son enviados.
- No hay ninguna garantía sobre mensajes de distintos emisores
- Ordenación causal: Si entre los mensajes enviados por dos emisores existe una posible relación "causa-efecto", todos los procesos del grupo reciben primero el mensaje "causa" y después el mensaje "efecto".
- Si no hay relación, no se garantiza ningún orden de entrega.
- Ordenación total: Todos los mensajes (de varias fuentes) enviados a un grupo son recibidos en el mismo orden por todos los elementos.
Bibliografía:
- Apuntes tomados de la clase del Lic. Marco Antonio Salas Quiñonez del Instituto Tecnológico de Los Mochis.
- Comunicación a través de mensajes; Elda Noemí Beltran Castro, Samara Lizeth Inzunza Castro, Alma Cristina Martínez López.
- Sistemas Operativos Distribuidos, Andrew S. Tanenbaum, editorial Prentice Hall.