Unidad III. Sincronización
Aunque la comunicación es importante, no es todo lo que hay que considerar. Íntimamente relacionada con esto está la forma en que los procesos cooperan y se sincronizan entre sí. Por ejemplo, la forma de implantar las regiones críticas o asignar recursos en un sistema distribuido.
En los sistemas con un CPU, los problemas relativos a las regiones críticas, la exclusión mutua y la sincronización se resuelven en general por mediante métodos tales como los semáforos y los monitores. Estos métodos no son adecuados para su uso en los sistemas distribuidos, puesto que siempre se basan en la existencia de la memoria compartida.
El tiempo y la forma de medirlo juega un papel fundamental en algunos modelos de sincronización.
3.2 Ordenamiento y 3.3 Sincronización
Sincronización de relojes
La sincronización es más compleja en los sistemas distribuidos que en los centralizados, puesto que los primeros deben utilizar algoritmos distribuidos.
Los algoritmos distribuidos tienen las siguientes propiedades:
- La información relevante se distribuye entre varias máquinas.
- Los procesos toman las decisiones sólo con base en la información disponible en forma local.
- Debe evitarse un punto de fallo en el sistema.
- No existe un reloj común o alguna otra fuente precisa del tiempo global.
Los primeros tres puntos indican que es inaceptable reunir toda la información en un lugar para su procesamiento. Lo ideal es que un sistema distribuido debería ser más confiable que las máquinas individuales Si alguna de ellas falla, el resto puede continuar su funcionamiento. El último punto de la lista también es crucial. En un sistema centralizado, el tiempo no tiene ambigüedades. Cuando un proceso desea conocer la hora, llama al sistema y el núcleo se la dice. En un sistema distribuido, no es trivial poner de acuerdo a todas las máquinas en la hora.
uesto que el tiempo es fundamental para la forma de pensar de la gente y el efecto carecer de sincronización en los relojes puede ser muy drástico.
Relojes lógicos
Casi todas las computadoras tienen un circuito para el registro del tiempo. A pesar del uso generalizado de la palabra "reloj" para hacer referencia a dichos dispositivos, en realidad no son relojes en el sentido usual. Cronómetro sería una mejor palabra. Un cronómetro de computadora es por lo general un cristal de cuarzo trabajado con precisión. Cuando se mantiene sujeto a tensión, un cristal de cuarzo oscila con frecuencia bien definida, que depende del tipo de cristal, la forma en que se corte y la magnitud de la tensión. A cada cristal se le asocian dos registros, un contador y un registro mantenedor. Cada oscilación del cristal disminuye en 1 al contador. Cuando el contador toma el valor de 0, se genera una interrupción y el contador se vuelve a cargar mediante el registro mantenedor. De esta forma, es posible programar un cronómetro de modo que genere una interrupción 60 veces por cada segundo o con cualquier frecuencia que se desee. Cada interrupción recibe el nombre de marca de reloj.
En el caso de una computadora y un reloj, no importa si éste se desfasa un poco. Puesto que todos los procesos de la máquina utilizan el mismo reloj, tendrán consistencia interna. Todo lo que importa son los tiempos relativos.
Tan pronto se comienza a trabajar con varias máquinas, cada una con su propio reloj, la situación es distinta. Aunque la frecuencia de un oscilador de cristal es muy estable, es imposible garantizar que los cristales de computadoras distintas oscilen precisamente con la misma frecuencia. En la práctica, cuando un sistema tiene n computadoras, los n cristales correspondientes oscilarán a tasas un poco distintas, lo que provoca una pérdida de sincronía en los relojes (de software) y que al leerlos tengan valores distintos. La diferencia entre los valores de tiempo se llama distorsión del reloj . Como consecuencia de esta distorsión podrían fallar los programas que esperan que el tiempo asociado a un archivo, objeto, proceso o mensaje sea correcto e independiente del sitio donde haya sido generado (es decir, del reloj utilizado).
Lamport (1978) demostró que la sincronización de relojes es posible y presentó un algoritmo para lograr esto.
Algoritmo de Lamport
Lamport señaló que la sincronización de relojes no tiene que ser absoluta. Si dos procesos no interactúan, no es necesario que sus relojes estén sincronizados, puesto que la carencia de sincronización no sería observable y por lo tanto no podría provocar problemas. Además señaló que lo que importa por lo general, no es que todos los procesos concuerden de manera exacta en la hora, sino que coincidan en el orden en que ocurren los eventos.
Para la mayoría de los fines, basta que todas las máquinas coincidan en la misma hora. No es esencial que esta hora también coincida con la hora real, lo que importa es la consistencia interna de los relojes, no su particular cercanía al tiempo real. Para estos algoritmos, conviene hablar de los relojes como relojes lógicos.
Cuando existe la restricción adicional de que los relojes no sólo deben ser iguales, sino que además no se desvíen del tiempo real más allá de cierta magnitud, los relojes reciben el nombre de relojes físicos.
Para sincronizar los relojes lógicos, Lamport definió una relación llamada ocurre antes de . La expresión a->b se lee: "a ocurre antes de b" e indica que todos los procesos coinciden en que primero ocurre el evento a y después el evento b. La relación "ocurre antes de" se puede observar de manera directa en dos situaciones:
- Si a y b son eventos en el mismo proceso y a ocurre antes de b , entonces a->b es verdadero.
- Si a es el evento del envío de mensaje por un proceso y b es el evento de la recepción del mensaje por otro proceso, entonces a->b también es verdadero. Un mensaje no se puede recibir antes de ser enviado o al mismo tiempo en que se envía, puesto que tarda en llegar una cantidad finita de tiempo.
Procesos diferentes que no intercambian mensajes ni si quiera en forma indirecta por medio de un tercero se dice que estos eventos son concurrentes , lo que significa que nada se puede decir (o se necesita decir) acerca del momento en el que ocurren o cuál de ellos es el primero.
Lo que necesitamos es una forma de medir el tiempo tal que, a cada evento a , le podamos asociar un valor de tiempo C (a) en el que todos los procesos estén de acuerdo. Estros valores del tiempo deben tener la propiedad de que si a->b, entonces C(a)<C(b).
demás, el tiempo del reloj, C , siempre debe ir hacia delante (creciente), y nunca hacia atrás (decreciente). Se pueden hacer correcciones al tiempo al sumar un valor positivo al reloj, pero nunca se le debe restar un valor positivo. En dado caso ralentizar el reloj para que vaya perdiendo esa diferencia, pero nunca atrasarlo.
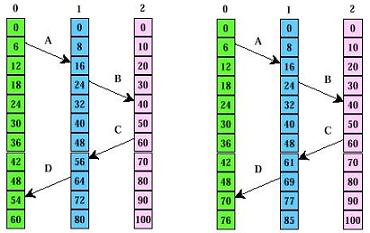
Consideramos tres procesos que se ejecutan en diferentes máquinas , cada una con su propio reloj y velocidad:
- El proceso "0" envía el mensaje "a" al proceso "1" cuando el reloj de "0" marca "6".
- El proceso "1" recibe el mensaje "a" cuando su reloj marca "16".
- Si el mensaje acarrea el tiempo de inicio "6" , el proceso "1" considerará que tardó 10 marcas de reloj en viajar.
- El mensaje "b" de "1" a "2" tarda 16 marcas de reloj.
- El mensaje "c" de "2" a "1" sale en "60" y llega en "56" , tardaría un tiempo negativo , lo cual es imposible.
- El mensaje "d" de "1" a "0" sale en "64" y llega en "54".
- Lamport utiliza la relación "ocurre antes de":
- Si "c" sale en "60" debe llegar en "61" o en un tiempo posterior.
- Cada mensaje acarrea el tiempo de envío, de acuerdo con el reloj del emisor.
- Cuando un mensaje llega y el reloj del receptor muestra un valor anterior al tiempo en que se envió el mensaje:
- El receptor adelanta su reloj para que tenga una unidad más que el tiempo de envío.
En ciertas situaciones, existe un requisito adicional: dos eventos no ocurren exactamente al mismo tiempo. Para lograr esto, podemos asociar el número del proceso en que ocurre el evento y el extremo inferior del tiempo, separados por un punto decimal. Así, si ocurren eventos en los procesos 1 y 2, ambos en el tiempo 40, entonces el primero se convierte en 40.1 y el segundo en 40.2.
En resumen:
Por medio de este método, tenemos ahora una forma de asignar un tiempo a todos los eventos en un sistema distribuido, con las siguientes condiciones:
- Si a ocurre antes de b en el mismo proceso, C(a)<C(b) .
- Si a y b son el envío y la recepción de un mensaje, C(a)<C(b) .
- Para todos los eventos a y b , C(a) <>C(b) .
Este algoritmo es una forma de obtener un orden total de todos los eventos en el sistema.
Relojes físicos
Aunque el algoritmo de Lamport proporciona un orden de eventos sin ambigüedades los valores de tiempo asignados a los eventos no tiene que ser cercanos a los tiempos reales en los que ocurren. En ciertos sistemas (por ejemplo, los sistemas de tiempo real como vuelos, navegación, etc.), es importante la hora real del reloj. Para estos sistemas se necesitan relojes físicos externos.
Un poco de historia... la forma en que se mide en realidad el tiempo.
Desde la invención de los relojes mecánicos el tiempo se ha medido de manera astronómica. Cada día, el sol parece levantarse en el horizonte del este, sube hasta una altura máxima en el cielo y desciende en el oeste. El evento en que el sol alcanza su punto aparentemente más alto en el cielo se llama tránsito del sol. Este evento ocurre aproximadamente a las doce del día de cada día. El intervalo entre dos tránsitos consecutivos del sol se llama el día solar. Puesto que existen 24 horas en un día, cada una de las cuales contiene 3,600 segundos, el segundo solar se define exactamente como 1/18,400 de un día solar.
En la década de 1940, se estableció que el período de rotación de la tierra no es constante. La Tierra está disminuyendo su velocidad, debido a la fricción tidal y el arrastre atmosférico. Con base en estudios de los patrones de crecimiento del coral antiguo, los geólogos piensan que ahora que hace 300 millones de años existían cerca de 400 días al año. La duración del año, es decir, el tiempo que tarda la Tierra en dar una vuelta alrededor del sol, no ha cambiado; sólo ocurre que los días se hacen más largos. Además de esta tendencia a largo plazo, también ocurren pequeñas variaciones a corto plazo en la duración del día, lo cual probablemente se deba a una turbulencia originada en el centro de acero fundido de la Tierra.
Estas revelaciones han llevado a los astrónomos a calcular la longitud del día mediante la medición de un gran número de días y tomar su promedio antes de dividir entre 86,400. La cantidad resultante se llama el segundo solar promedio.
Con la invención del reloj atómico en 1948, fue posible medir el tiempo de manera mucho más exacta y en forma independiente de todo el ir y venir de la Tierra, al contar las transiciones del átomo de cesio 133. Los físicos retomaron de los astrónomos la tarea de medir el tiempo y definieron el segundo como el tiempo que tarda el átomo de cesio 133 en hacer exactamente 9,192,631,770 transiciones. La elección de 9,192,631,770 fue hecha para que el segundo atómico fuera igual al segundo solar promedio en el año de su introducción. La oficina internacional de la hora en París hace un promedio de estos números para producir el tiempo atómico internacional , que se abrevia TAI . Así TAI es el promedio de las marcas de los relojes de cesio 133 a partir de la media noche del primero de enero de 1958 (principio del tiempo), dividido entre 9,192,631,770.El uso de TAI para el registro del tiempo significaría que, con el paso de los años, el mediodía sería cada vez más temprano, hasta llegar al momento en que el mediodía ocurriría en la mañana.
La BIH resolvió el problema mediante la introducción de segundos de saldo , siempre que la discrepancia entre TAI y el tiempo solar creciera hasta 800 milisegundos. Esta corrección da lugar a un sistema de tiempo basado en los segundos constantes TAI, pero que permanece en fase con el movimiento aparente del Sol. Se le llama tiempo coordenado universal, UTC. UTC es la base de todo el sistema de mantenimiento moderno de la hora. En lo esencial, ha reemplazado al estándar anterior, el tiempo del meridiano de Greenwich, que es un tiempo astronómico. El número total de segundos de salto introducido en UTC hasta ahora es cercano de 30.
Para proporcionar UTC a las personas que necesitan un tiempo preciso, el Instituto Nacional del Tiempo Estándar (NIST) opera una estación de radio de onda corta con las siglas WWV desde Fort Collins, Colorado. WWV transmite un pulso corto al inicio de cada segundo UTC. La precisión del propio WWV es de cerca de ± 1 milisegundo, pero debido a la fluctuación atmosférica aleatoria que puede afectar la longitud de la trayectoria de la señal, en la práctica la precisión no es mejor que ±1 0 milisegundos. Existen varios satélites terrestres que también ofrecen un servicio UTC como es el caso de GEOS.
3.4 Algoritmos para la sincronización de relojes
Si una máquina tiene un receptor WWV, entonces el objetivo es hacer que todas las máquinas se sincronicen con ella. Si ninguna máquina tiene receptores WWV, entonces cada máquina lleva el registro de su propio tiempo y el objetivo es mantener el tiempo de todas las máquinas tan cercano sea posible.
Algoritmo de Cristian
Este algoritmo es adecuado para los sistemas en los que una máquina tiene un receptor WWV y el objetivo es hacer que todas las máquinas se sincronicen con ella. Llamaremos a la máquina con el receptor WWV un servidor del tiempo . En forma periódica, en un tiempo que no debe ser mayor que d /2 r segundos, cada máquina envía un mensaje al servidor para solicitar el tiempo actual. Esa máquina responde tan pronto como puede con un mensaje que contiene el tiempo actual, C UTC .
Como primera aproximación, cuando el emisor obtiene la respuesta, puede hacer que su tiempo sea C UTC . Sin embargo, este algoritmo tiene dos problemas, uno mayor y otro menor.
El problema mayor es que el tiempo nunca debe correr hacia atrás. Si el reloj del emisor es más rápido, C UTC será menor que el valor actual de C del emisor. El simple traslado de C UTC podría provocar serios problemas, tales como tener un archivo objeto compilado justo después del cambio de reloj y que tenga un tiempo anterior al del archivo fuente, modificando justo antes del cambio del reloj. Tal cambio se debe introducir de manera gradual. Una forma es la siguiente:
Supongamos que el cronómetro se ajusta para que genere 100 interrupciones por segundo Lo normal sería que cada interrupción añadiera 10 milisegundos al tiempo. Al reducir la velocidad, la rutina de interrupción sólo añade 9 milisegundos cada vez, hasta que se haga la corrección. De manera similar, el reloj se puede adelantar de manera gradual, sumando 11 milisegundos en cada interrupción en vez de saltar hacia delante de una vez.
El problema menor es que el tiempo que tarda el servidor en responder al emisor es distinto de cero. Peor aún, este retraso puede ser de gran tamaño y varía con la carga de la red. La forma de enfrentar este problema por parte de Cristian es intentar mediarlo. Es muy fácil para el emisor registrar de manera precisa el intervalo de inicio, T 0 , como el tiempo final, T 1 , se miden con el mismo reloj, por lo que el intervalo será relativamente preciso, aunque el reloj del emisor esté alejado de UTC por una magnitud sustancial.
En ausencia de otra información, la mejor estimación del tiempo de propagación del mensaje es de ( T 1 -T 0 /2 ). Al llegar la respuesta, el valor en el mensaje puede ser incrementado por esta cantidad para dar una estimación del tiempo actual del servidor. Si se conoce el tiempo mínimo de propagación teórico, se pueden calcular otras propiedades de la estimación del tiempo.
Es estimación se puede mejorar si se conoce con cierta aproximación el tiempo que tarda el servidor del tiempo en manejar la interrupción y procesar el mensaje recibido. Llamaremos al tiempo para el manejo de interrupción I . Entonces la cantidad del tiempo desde T 0 hasta T 1 dedicada a al propagación del mensaje es T 1 -T 0 -I , por lo que una mejor estimación del tiempo de propagación en un sentido es la mitad de esta cantidad.
Para mejorar la precisión, Cristian sugirió hacer no una medición, sino varias. Cualquier medición en la que T 1 -T 0 exceda cierto valor límite se descarta, por ser considerada víctima del congestionamiento en la red por tanto no confiable. Las estimaciones obtenidas de las demás pruebas se pueden promediar para obtener mejor valor. Otra alternativa es que el mensaje que regrese más rápido se considere como el más preciso, pues supuestamente encontraría menos tráfico y por lo tanto sería el más representativo del tiempo de propagación puro.
Algoritmo de Berkeley
En el algoritmo de Cristian, el servidor de tiempo es pasivo. En este caso, el servidor de tiempo (en realidad, un demonio para el tiempo) está activo y realiza un muestreo periódico de todas las máquinas para preguntarles el tiempo. Con base en las respuestas, calcula un tiempo promedio y le indica a todas las demás máquinas que avancen su reloj a la nueva hora o que disminuyan la velocidad del mismo hasta lograr cierta reducción específica. Este método es adecuado para un sistema donde no exista un receptor de WWV. La hora del demonio para el tiempo debe ser establecida en forma manual por el operador, de manera periódica.Algoritmos con promedio
Los dos métodos anteriores son muy centralizados, con las desventajas usuales. Una clase de algoritmos centralizados trabaja al dividir el tiempo en intervalos de resincronización de longitud física. Al inicio de cada intervalo, cada máquina transmite el tiempo actual según su reloj. Puesto que los relojes de las diversas máquinas no funcionan con exactamente la misma velocidad, estas transmisiones no ocurrirán en forma simultánea.
Después de que una máquina transmite su hora, inicia un cronómetro local para reunir las demás transmisiones que lleguen en cierto intervalo S. Cuando llegan todas las transmisiones, se ejecuta un algoritmo para calcular una nueva hora para ellos.
El algoritmo más sencillo consiste en promediar los valores de todas las demás máquinas.
Una ligera variación es descartar primero los m valores más grandes y los m valores más pequeños, y promediar el resto. El hecho de descartar los valores más extremos se puede considerar como autodefensa contra m relojes fallidos que envían mensajes sin sentido.
Otra variación intenta corregir a cada mensaje al añadir una estimación del tiempo de propagación desde la fuente. Esta estimación se puede hacer a partir de la topología conocida de la red o al medir el tiempo que tardan en regresar ciertos mensajes de prueba.
Varias fuentes externas de tiempo
Para los sistemas que requieren sincronización en extrema precisa con UTC, es posible equiparlos con varios receptores de WWV, GEOS o algunas otras fuentes de UTC. Sin embargo, debido a la imprecisión inherente en la propia fuente de tiempo, así como a las fluctuaciones en la ruta de la señal, lo mejor que puede hacer el sistema operativo es establecer un rango (intervalo de tiempo) en el que caiga UTC. En general, las distintas fuentes de tiempo producirán distintos márgenes, lo que requiere un acuerdo entre las máquinas conectadas a ellas.
Para lograr este acuerdo, cada procesador con fuente UTC puede transmitir su rango en forma periódica; digamos, en el preciso inicio de cada minuto UTC. Ninguno de los procesadores obtendrá los paquetes de tiempo en forma instantánea. Peor aún, el retraso entre la transmisión y recepción depende de la distancia del cable y el número de compuertas que deben atravesar los paquetes, que es diferente para cada pareja (fuente de UTC, procesador). En fin pueden jugar un papel otros factores.
Uso de relojes sincronizados
Entrega de mensajes a lo más uno
Se refiere a la forma de reforzar la entrega de a los más uno mensaje a un servidor, incluso en presencia de fallas. El método tradicional es que cada mensaje tenga un número de mensaje, y que cada servidor guarde los números de los mensajes que ha visto, de modo que pueda establecer diferencia entre los mensajes nuevos y las retransmisiones. El problema con el algoritmo es que si un servidor falla y vuelve a arrancar, pierde su tabla con los números de mensajes. Además, ¿por cuánto tiempo deben conservarse los números de mensajes?
Con el uso del tiempo, el algoritmo se puede modificar de la siguiente manera. En este caso, cada mensaje tiene un identificador de conexión (elegido por el emisor) y una marca de tiempo. Para cada conexión, el servidor registra en una tabla la marca de tiempo más reciente que haya visto. Si el número de cualquier mensaje recibido en cierta conexión es menor que la marca de tiempo guardada en esa conexión, el mensaje se rechaza como un duplicado.
Para eliminar las marcas de tiempo anteriores, cada servidor mantiene de manera continua una variable global:
G = Tiempo Actual - Tiempo Máximo de Vida - Desviación Máxima del Reloj
En donde "Tiempo Máximo de Vida" es el tiempo máximo de vida de un mensaje y "Desviación Máxima del Reloj" es la peor distancia de alejamiento entre UTC y el reloj.
Cualquier marca de tiempo anterior a G se puede eliminar con seguridad de la tabla, pues todos los mensajes con esa edad ya han muerto.
Si un mensaje recibido tiene un identificador de conexión desconocido, se acepta si su marca de tiempo es más reciente que G y rechazado si su marca de tiempo es anterior a G , puesto que todo lo anterior seguramente es un duplicado.
- G es en resumen de los números de mensaje de todos los mensajes anteriores.
- Cada D T , el tiempo actual se escribe en disco.
- Cuando falla un servidor y vuelve a arrancar, vuelve a cargar a G del tiempo guardado en el disco y lo incrementa según el periodo de actualización, D T .
- Cualquier mensaje recibido con una marca anterior a G se rechaza como duplicado.
- Como consecuencia, se rechaza cada mensaje que podría ser aceptado antes de la falla.
- Algunos de los mensajes nuevos podrían rechazarse de manera incorrecta, pero bajo todas las condiciones, el algoritmo conserva la semántica a lo más uno.
Consistencia del caché con base en el reloj
Se refiere a la consistencia del caché en un sistema distribuido de archivos. Por razones de desempeño, es deseable que los clientes puedan ocultar archivos de manera local. Sin embargo, el ocultamiento introduce una potencial inconsistencia si dos clientes modifican el mismo archivo al mismo tiempo. La solución usual consiste en distinguir entre ocultar un archivo para su lectura o para su escritura. La desventaja de este esquema es que si un cliente tiene un archivo oculto para su lectura, antes de que otro cliente pueda obtener una copia para su escritura, el servidor tiene que solicitar al cliente de lectura que invalide su copia, incluso si la copia se realizó unas cuantas horas antes. Este costo adicional se puede eliminar mediante los relojes sincronizados.
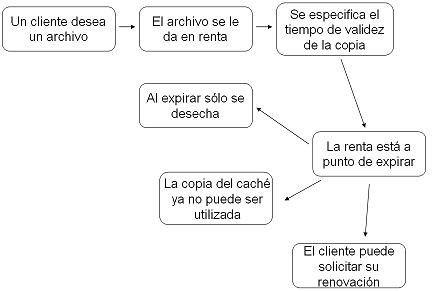
La idea básica es que, cuando un cliente desea un archivo, se la da en renta.
Si una renta expira y el archivo (aún en el caché) se necesita un poco de tiempo después, el cliente puede preguntar al servidor si la copia que tiene (identificada por una marca de tiempo) sigue siendo la activa. En tal caso, se genera una nueva renta, pero sin retransmitir el archivo.
Si uno o más clientes tienen un archivo en caché para su lectura y entonces otro cliente desea escribir en el archivo, el servidor debe solicitar a los lectores que terminen sus rentas de manera prematura. Si uno o más de ellos ha sufrido una falla, el servidor sólo esperar hasta que expire la renta del servidor muerto.
En el algoritmo tradicional, donde el permiso para guardar el caché debe regresarse de manera explícita del cliente al servidor, ocurre un problema si el servido pide al cliente o clientes que regresen al archivo (es decir, que lo eliminen de su caché) y no hay respuesta. El servidor no puede determinar si el cliente está muerto o sólo es lento. Con el algoritmo basado en un cronómetro, el servidor puede esperar y dejar que expire la renta.
Con frecuencia, los sistemas con varios procesos se programan más fácilmente mediante las regiones críticas.
Cuando un proceso debe leer o actualizar ciertas estructuras de datos compartidas, primero entra a una región crítica para lograr la exclusión mutua y garantizar que ningún otro proceso utilice las estructuras de datos al mismo tiempo.
En los sistemas con un procesador, las regiones críticas se protegen mediante semáforos, monitores y construcciones similares. En sistemas distribuidos la cuestión es más compleja.
Un algoritmo centralizado
La forma más directa de lograr la exclusión mutua en un sistema distribuido es similar a la forma en que se lleva a cabo en un sistema con un procesador:
Se elige un proceso como el coordinador (por ejemplo, aquel que se ejecuta en la máquina con la máxima dirección en la red). Siempre que un proceso desea entrar a su región crítica, envía un mensaje de solicitud al coordinador, donde indica la región crítica a la que desea entrar y pide permiso. Si ningún otro proceso está por el momento en esa región crítica, el coordinador envía una respuesta otorgando el permiso.
Supongamos ahora que otro proceso 2, pide permiso para entrar a la misma región crítica. El coordinador sabe que un proceso distinto ya que se encuentra en esta región, por lo que no puede otorgar el permiso. El método exacto utilizado para negar el permiso depende del sistema. En este ejemplo, el coordinador sólo se abstiene de responder, con lo cual se bloquea el proceso 2, que espera respuesta. Otra alternativa consiste en enviar una respuesta que diga "permiso denegado". De cualquier manera, forma en una fila la solicitud de 2 por el momento.
Cuando el proceso 1 sale de la región crítica, envía un mensaje al coordinador para liberar su acceso exclusivo. El coordinador extrae el primer elemento de la fila de solicitudes diferidas y envía a ese proceso un mensaje otorgando el permiso. Si el proceso estaba bloqueado (es decir, éste es el primer mensaje que se le envía), elimina el bloqueo y entra a la región crítica. Si ya se envió un mensaje explícito negando el permiso, entonces el proceso debe hacer un muestreo de tráfico recibido o bloquearse posteriormente. De cualquier forma, cuando ve el permiso, puede entrar a la región crítica.
Es fácil ver que el algoritmo garantiza la exclusión mutua: el coordinador deja que un proceso esté en cada región crítica a la vez. También es justo, puesto que las solicitudes se aprueban en el orden en que se reciben. Ningún proceso espera por siempre (no hay inanición). Este esquema también es fácil de implantar y sólo requiere tres mensajes por cada uso de una región crítica (solicitud, otorgamiento, liberación). También se puede utilizar para una asignación de recursos más general, en vez de usarlo sólo para el manejo de las regiones críticas.
El método centralizado también tiene limitaciones. El coordinador es un punto de falla, por lo que si se descompone, todo el sistema se puede venir abajo. Si los procesos se bloquean por lo general después de realizar una solicitud, no pueden distinguir entre un coordinador muerto de un "permiso denegado", puesto que en ambos casos no reciben respuesta. Además, en un sistema de gran tamaño, un coordinador puede convertirse en un cuello de botella para el desempeño.
Un algoritmo distribuido
Con frecuencia, el hecho de tener un punto de falla es inaceptable, por lo cual los investigadores han buscado algoritmos distribuidos de exclusión mutua. El artículo de 1978 de Lamport relativo a la sincronización de los relojes presentó el primero de ellos. Ricart y Agrawala (1981) lo hicieron más eficiente.
El algoritmo de Ricart y Agrawala requiere de la existencia de un orden total de todos los eventos del sistema. Es decir, para cualquier pareja de eventos, como los mensajes, debe quedar claro cuál ocurrió primero. El algoritmo de Lamport es una forma de lograr este orden y se puede utilizar para proporcionar marcas de tiempo para la exclusión mutua distribuida.
El algoritmo funciona como sigue. Cuando un proceso desea entrar a una región crítica, construye un mensaje con el nombre de ésta, su número de proceso y la hora actual. Entonces envía el mensaje a todos los demás procesos y de manera conceptual a él mismo. Se supone que el envío de mensajes es confiable; es decir, cada mensaje tiene su reconocimiento. Si se dispone de una comunicación en grupo confiable, entonces ésta se puede utilizar en vez del envío de mensajes individuales.
Cuando un proceso recibe un mensaje de solicitud de otro proceso, la acción que realice depende de su estado con respecto de la región crítica nombrada en el mensaje. Hay que distinguir tres casos:
- Si el receptor no está en la región crítica y no desea entrar a ella, envía de regreso un mensaje OK al emisor.
- Si el receptor ya está en la región crítica, no responde, sino que forma la solicitud en una fila.
- Si el receptor desea entrar a la región crítica, pero no lo ha logrado todavía, compara la marca de tiempo en el mensaje recibido con la marca contenida en el mensaje que envió a cada uno. La menor de las marcas gana. Si el mensaje recibido es menor, el receptor envía de regreso un mensaje OK. Si su propio mensaje tiene una marca menor, el receptor forma la solicitud en una fila y no envía nada.
Después de enviar las solicitudes que piden permiso para entrar a una región crítica, un procesador espera hasta que alguien más obtiene el permiso. Tan pronto llegan todos los permisos, puede entrar a la región crítica. Cuando sale de ella, envía mensajes OK a todos los procesos en su fila y elimina a todos los elementos de la fila.
El algoritmo funciona, puesto que en caso de un conflicto, gana la menor de las marcas y todos coinciden en el orden de las marcas de tiempo.
El número de mensajes necesarios por entrada es ahora 2(n-1), donde n es el número total de procesos en el sistema. Lo mejor es que no existe un punto de falla.
Por desgracia, el único punto de falla es remplazado por n puntos de falla. Si cualquier proceso falla, no podrá responder a las solicitudes. Este silencio será interpretado (incorrectamente) como negación del permiso, con lo que se bloquearán los siguientes intentos de los demás procesos por entrar a todas las regiones críticas.
El algoritmo se puede mejorar mediante el mismo truco propuesto antes. Al llegar una solicitud, el receptor siempre envía una respuesta, otorgando o negando el permiso. Siempre que pierda una solicitud o una respuesta, el emisor espera y sigue intentando hasta que regresa una respuesta o el emisor concluye que el destino está muerto. Después de negar una solicitud, el emisor debe bloquearse en espera de un mensaje OK posterior.
Otro problema con este algoritmo es que debe utilizar una primitiva de comunicación en grupo; o bien, cada proceso debe mantener por sí mismo la lista de membresía del grupo, donde se incluyan los procesos que ingresan al grupo, los que salen de él y los que fallan. El método funciona mejor con grupos pequeños de procesos que nunca cambian sus membresías de grupo.
En el algoritmo distribuido, todos los procesos participan en todas las decisiones referentes a la entrada en las regiones críticas. Si un proceso no puede manejar esta tarea, es poco probable que obligar a todos a que realicen lo mismo en paralelo sea de mucha ayuda.
Un algoritmo de anillo de fichas
Se tiene una red basada en un bus (por ejemplo, Ethernet), sin un orden inherente en los procesos. En software, se construye un anillo lógico y cada proceso se le asigna una posición en el anillo. Las posiciones en el anillo se pueden asignar según el orden numérico de las direcciones de la red o mediante algún otro medio. No importa cómo sea el orden. Lo importante es que cada proceso sepa quién es el siguiente en la fila después de él.
Al iniciar el anillo, se le da al proceso 0 una ficha , la cual circula en todo el anillo. Se transfiere del proceso k al proceso k+1 (módulo el tamaño del anillo) en mensajes puntuales. Cuando un proceso obtiene la ficha de su vecino, verifica si intenta entrar a una región crítica. En ese caso, el proceso entra a la región, hace todo el trabajo necesario y sale de la región. Después de salir, para la ficha a lo largo del anillo. No se permite entrar a una segunda región crítica con la misma ficha.
Si un proceso recibe la ficha de su vecino y no está interesado en entrar a una región crítica, sólo la vuelve a pasar. En consecuencia, cuando ninguno de los procesos desea entrar a una región crítica, la ficha sólo circula a gran velocidad en el anillo.
Es evidente que el algoritmo es correcto. En un instante dado, sólo uno de los procesos tiene la ficha, por lo que sólo un proceso puede estar en una región crítica. Puesto que las fichas circulan entre los procesos en orden bien definido, no puede existir la inanición. Una vez que un proceso decide entrar a una región crítica, lo peor que puede ocurrir es que deba esperar a que los demás procesos entren y salga de ella.
Como es usual, también este algoritmo tiene problemas. Si la ficha llega a perderse, debe ser regenerada. De hecho, es difícil detectar su pérdida, puesto que la cantidad de tiempo entre las apariciones sucesivas de la ficha en la red no está acotada. El hecho de que la ficha no se haya observado durante una hora no significa su pérdida; tal vez alguien la esté utilizando.
El algoritmo también tiene problemas si falla un proceso, pero la recuperación es más sencilla que en los demás casos. Si pedimos un reconocimiento a cada proceso que reciba la ficha, entonces detectará un proceso muerto si su vecino intenta darle la ficha y fracasa en el intento. En ese momento, el proceso muerto se puede eliminar del grupo y el poseedor de la ficha puede enviar ésta por encima de la cabeza del proceso muerto al siguiente miembro, y así sucesivamente, en caso necesario. Por supuesto, esto requiere que todos mantengan la configuración actual del anillo.
Comparación de los tres algoritmos
Algoritmo
Mensajes por dato/salida
Retraso antes del dato (en tiempo de mensajes)
Problemas
Centralizado
3
2
Fallo del coordinador.
Distribuido
2(n-1)
2(n-1)
Fallo de cualquier proceso.
Anillo de elementos
1 a 8
0 a n-1
Ficha perdida, falla del proceso.
Los tres algoritmos sufren en caso de fallas. Se pueden utilizar medidas especiales y complejidad adicional, para evitar que una falla haga que todo el sistema se venga abajo. Es un poco irónico que los algoritmos distribuidos sean más sensibles a las fallas que los centralizados. En un sistema tolerante de fallas, ninguno de éstos sería adecuado, pero si las fallas son poco frecuentes, todos son aceptables.
Algoritmos de elección
Muchos de los algoritmos distribuidos necesitan que un proceso actúe como coordinador, iniciador, secuenciador o que desempeñe de cierta forma algún papel especial. En general, no importa cuál de los procesos asuma esta responsabilidad especial, pero uno de ellos debe hacerlo.
Si todos los procesos son idénticos, sin alguna característica que los distinga, no existe forma de elegir uno de ellos como especial. En consecuencia, supondremos que cada proceso tiene un número único; por ejemplo, su dirección en la red (supondremos que existe un proceso por cada máquina). En general, los algoritmos de elección intentan localizar al proceso con el máximo número de proceso y de designarlo como coordinador. Los algoritmos difieren en la forma en que lo llevan a cabo.
Además también supondremos que cada proceso conoce el número de proceso de todos los demás. Lo que el proceso desconoce es si los procesos están activos o inactivos. El objetivo de un algoritmo de elección es garantizar que al inicio de una elección, ésta concluya con el acuerdo de todos los procesos con respecto a la identidad del nuevo coordinador. Se conocen varios algoritmos los más conocidos son:
El algoritmo del grandulón
Como primer ejemplo, consideremos al algoritmo del grandulón , diseñado por García-Molina (1982). Cuando un proceso observa que el coordinador ya no responde a las solicitudes, inicia una elección. Un proceso P realiza una elección de la siguiente manera:
- P envía un mensaje de ELECCIÓN a los demás procesos con un número mayor.
- Si nadie responde, P gana la elección y se convierte en el coordinador.
- Si uno de los procesos con un número mayor responde, toma el control. El trabajo de P termina.
En cualquier momento, un proceso puede recibir un mensaje de ELECCIÓN de uno de sus compañeros con un número menor. Cuando llega dicho mensaje, el receptor envía de regreso un mensaje OK al emisor para indicar que está vivo y que tomará el control. El receptor realiza entonces una elección, a menos que ya esté realizando alguna. En cierto momento, todos los procesos se rinden, menos uno, el cual se convierte en el nuevo coordinador. Anuncia su victoria al enviar un mensaje a todos los procesos para indicarles que a partir de ese momento es el nuevo coordinador.
Si un proceso inactivo se activa, realiza una elección. Si ocurre que es el proceso en ejecución con el número máximo, ganará la elección y tomará para sí el trabajo del coordinador. Así, siempre gana el tipo más grande del pueblo, de ahí el nombre "algoritmo del grandulón".
Un algoritmo de anillo
Otro algoritmo de elección se basa en el uso de un anillo, sólo que a diferencia del anillo anterior, éste no utiliza una ficha. Suponemos que los procesos tienen un orden, físico o lógico, de modo que cada proceso conoce a su sucesor. Cuando algún proceso observa que el coordinador no funciona, construye un mensaje de ELECCIÓN con su propio número de proceso y envía el mensaje a su sucesor. Si éste está inactivo, el emisor pasa sobre el sucesor y va hacia el siguiente número del anillo o al siguiente de éste, hasta que localiza un proceso en ejecución. En cada paso, el emisor añade su propio número de proceso a la lista del mensaje.
En cierto momento, el mensaje regresa a los procesos que lo iniciaron. Ese proceso reconoce este evento cuando recibe un mensaje de entrada con su propio número de proceso. En este punto, el mensaje escrito cambia a COORDINADOR y circula de nuevo, esta vez para informar a todos los demás quién es el coordinador (el miembro de la lista con el número máximo) y quiénes son los miembros del nuevo anillo. Una vez circulando el mensaje, se elimina y todos se ponen a trabajar.
Propiedades de las transacciones
- Atómicas: Para el mundo exterior, la transacción ocurre de manera indivisible.
- Consistentes: La transacción no viola las invariables del sistema.
- Aisladas: Las transacciones concurrentes no interfieren entre sí.
- Durables: Una vez comprometida una transacción, los cambios son permanentes.
• Atómicas : Garantiza que cada transacción no ocurre, o bien, se realiza en su totalidad; en este segundo caso, se presenta como acción instantánea e indivisible. Mientras se desarrolla una transacción, otros procesos no pueden ver los estados intermedios.
• Consistentes : Si el sistema tiene ciertos invariantes que deben conservarse siempre, si estos se conservan antes de la transacción, entonces también deben conservarse después de ellos.
• Aisladas o serializables : Si dos o más transacciones se ejecutan al mismo tiempo, para cada una de ellas y para los demás procesos, el resultado final aparece como si todas las transacciones se ejecutasen de manera secuencial en cierto orden (dependiente del sistema).
• Durables : Se refiere al hecho de que una vez comprometida la transacción, no importa lo que ocurra, la transacción sigue adelante y los resultados se vuelven permanentes. Ninguna falla después del compromiso puede deshacer los resultados o provocar la pérdida de los mismos.
Esquemas de planificación : Son ordenamientos, según los cuales se pueden intercalar los procesos.
Transacciones anidadas : Las transacciones pueden contener subtransacciones. La transacción de nivel superior puede producir hijos que se ejecuten en paralelo entre sí, en procesadores distintos. Cada uno de estos hijos puede ejecutar una o más subtransacciones o bien producir sus propios hijos.
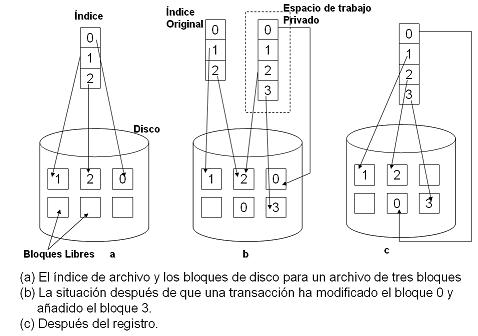
Espacio de trabajo privado : Cuando un proceso inicia una transacción, se le otorga un espacio de trabajo privado, el cual contiene todos los archivos (y otros objetos) a los cuales tiene acceso. Hasta que una transacción se comprometa o aborte, todas sus lecturas y escrituras irán al espacio de trabajo particular, en vez del espacio "real", donde éste último es el sistema de archivos normal.
En vez de copiar todo el archivo, sólo se copia el índice del archivo en el espacio de trabajo particular. El índice es el bloque de datos asociados a cada archivo, en el cual se indica la localización de sus bloques en disco. El bloque se puede actualizar entonces sin afectar al original. También se manejan de esta forma los bloques añadidos. Los nuevos bloques reciben a menudo el nombre de bloques sombra.
Bitácora de escritura anticipada
A veces conocida como lista de intenciones. Los archivos en realidad se modifican, pero antes de cambiar cualquier bloque, se escribe un registro en la bitácora de escritura anticipada en un espacio de almacenamiento estable para indicar la transacción que realiza el cambio, el archivo y bloque modificados y los valores anterior y nuevo.
Con este método, los archivos en realidad se modifican, pero antes de cambiar cualquier bloque, se escribe un registro en la bitácora de escritura anticipada en un espacio de almacenamiento estable para indicar la transacción que realiza el cambio el archivo y bloque modificados y los valores anterior o nuevo.
Si la transacción tiene éxito y se establece un compromiso, se escribe un registro de este último en la bitácora, pero las estructuras de datos no tienen que modificarse, puesto que ya han sido actualizadas. Si la transacción aborta, se puede utilizar la bitácora para respaldar el edo. original. A partir del final y hacia atrás, se lee cada registro de la bitácora y se deshace cada cambio descrito en el. Esta acción se llama Retroalimentación.
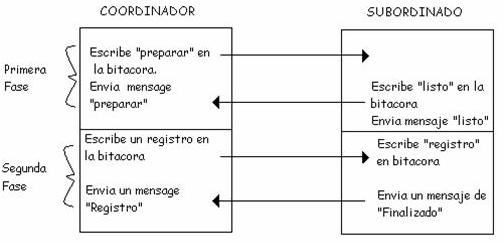
Protocolo de compromiso de dos fases
Uno de los procesos que intervienen en este caso es el coordinador. Por lo general, éste es quien ejecuta la transacción. El protocolo de compromiso comienza cuando el coordinador escribe una entrada en la bitácora para indicar que inicia dicho protocolo, seguido del envío de un mensaje a cada uno de los procesos implicados (subordinados) para que estén listos para el compromiso.
Cuando un subordinado recibe el mensaje, verifica si está listo para comprometerse, escribe una entrada en la bitácora y envía de regreso su decisión. Cuando el coordinador ha recibido todas las respuestas, sabe si se establece el compromiso o aborta. Si todos los procesos están listos para comprometerse, entonces se cierra la transacción. Si uno o más procesos no se comprometen (o no responden), la transacción se aborta. De cualquier modo, el coordinador escribe una entrada en la bitácora y envía entonces un mensaje a cada subordinado para informarle de la decisión. Esta escritura en la bitácora la que en realidad cierra la transacción y hace que proceda sin importar ya lo ocurrido antes.
Es resistente mucho a la presencia de (varias) fallas.
Control de concurrencia
• Algoritmo de control de concurrencia: Cierto mecanismo para mantener a cada proceso lejos del camino de otro proceso.
• Cerradura: El algoritmo más antiguo y de más amplio uso. En su forma más sencilla, cuando un proceso necesita leer o escribir en un archivo (u otro objeto) como parte de una transacción, primero cierra el archivo.
* no está terminada
Bibliografía: