Unidad VI. Administración de recursos
Por las situaciones ya vistas en la ejecución concurrente de procesos, es necesario bloquear procesos. En concreto, en el acceso a recursos no compartibles por parte de varios procesos se debe utilizar el bloqueo:
- SOLICITAR RECURSO
- UTILIZAR RECURSO
- LIBERAR RECURSO
6.1 Sistemas de administración de recursos
La comunicación no solo depende de la cantidad de información enviada. Cada comunicación tiene un costo fijo de arranque. Reduciendo el número de mensajes, a pesar de que se envíe la misma cantidad de información, puede ser útil. Así mismo se puede intentar replicar cómputos y/o datos para reducir los requerimientos de comunicación. Por otro lado, también se debe considerar el costo de creación de tareas y el costo de cambio de contexto12 (context switch) en caso de que se asignen varias tareas a un mismo procesador.
En caso de tener distintas tareas corriendo en diferentes computadores con memorias privadas, se debe tratar de que la granularidad sea gruesa: exista una cantidad de cómputo significativa antes de tener necesidades de comunicación. Esto se aplica a máquinas como la SP2 y redes de estaciones de trabajo. Se puede tener granularidad media si la aplicación correrá sobre una máquina de memoria compartida. En estas máquinas el costo de comunicación es menor que en las anteriores siempre y cuando en número de tareas y procesadores se mantenga dentro de cierto rango. A medida que la granularidad decrece y el número de procesadores se incrementa, se intensifican la necesidad de altas velocidades de comunicaciones entre los nodos. Esto hace que los sistemas de grano fino por lo general requieran máquinas de propósito específico. Se pueden usar máquinas de memoria compartida si el número de tareas es reducido, pero por lo general se requieren máquinas masivamente paralelas conectadas mediante una red de alta velocidad (arreglos de procesadores o máquinas vectoriales).
6.2 Comportamiento y balanceo de carga
Los puntos resaltantes que se deben considerar en esta etapa son:
Cada vez que el procesador cambia de tarea, se deben cargar registros y otros datos de la tarea que correrá.
En esta última etapa se determina en que procesador se ejecutará cada tarea. Este problema no se presenta en máquinas de memoria compartida tipo UMA. Estas proveen asignación dinámica de procesos y los procesos que necesitan de un CPU están en una cola de procesos listos. Cada procesador tiene acceso a esta cola y puede correr el próximo proceso. No consideraremos más este caso.
Por el momento no hay mecanismos generales de asignación de tareas para máquinas distribuidas. Esto continúa siendo un problema difícil y que debe ser atacado explícitamente a la hora de diseñar algoritmos paralelos.
La asignación de tareas puede ser estática o dinámica. En la asignación estática, las tareas son asignadas a un procesador al comienzo de la ejecución del algoritmo paralelo y corren ahí hasta el final. La asignación estática en ciertos casos puede resultar en un tiempo de ejecución menor respecto a asignaciones dinámicas y también puede reducir el costo de creación de procesos, sincronización y terminación.
En la asignación dinámica se hacen cambios en la distribución de las tareas entre los procesadores a tiempo de ejecución, o sea, hay migración de tareas a tiempo de ejecución. Esto es con el fin de balancear la carga del sistema y reducir el tiempo de ejecución. Sin embargo, el costo de balanceo puede ser significativo y por ende incrementar el tiempo de ejecución.
Balanceo de carga (definición): Es el esquema aplicado al procesamiento distribuido y/o al sistema de comunicación con el fin de que un dispositivo no se sature.
- Especialmente importante en redes donde es muy difícil predecir el número de peticiones que se van a cursar a un servidor.
- Por ejemplo, los sitios web muy demandados suelen emplear dos o más servidores bajo un esquema de balanceo de carga.
- Si un servidor comienza a saturarse las peticiones son redireccionadas a otro(s).
- El balanceo de carga puede referirse también a los canales de comunicación.
6.3 Algoritmos para balanceo de cargas
Entre los algoritmos de balanceo de carga están los siguientes:
Balanceo centralizado: un nodo ejecuta el algoritmo y mantiene el estado global del sistema. Este método no es extensible a problemas más grandes ya que el nodo encargado del balanceo se convierte en un cuello de botella.
Balanceo completamente distribuido: cada procesador mantiene su propia visión del sistema intercambiando información con sus vecinos y así hacer cambios locales. El costo de balanceo se reduce pero no es óptimo debido a que solo se dispone de informacio'n parcial.
Balanceo semi-distribuido: divide los procesadores en regiones, cada una con un algoritmo centralizado local. Otro algoritmo balancea la carga entre las regiones.
El balanceo puede ser iniciado por envío o recibimiento. Si es balanceo iniciado por envío, un procesador con mucha carga envía trabajo a otros. Si es balanceo iniciado por recibimiento, un procesador con poca carga solicita trabajo de otros. Si la carga por procesador es baja o mediana, es mejor el balanceo iniciado por envío. Si la carga es alta se debe usar balanceo iniciado por recibimiento. De lo contrario, en ambos casos, se puede producir una fuerte migración innecesaria de tareas.
Entre los puntos que hay que revisar en esta etapa encontramos:
Situación que se produce cuando ningún proceso puede continuar su ejecución ni liberar recursos.
Modelo de interbloqueo
Holt indicó una forma de modelar la asignación de recursos mediante gráficas dirigidas (Gráficas de recursos).

Las estrategias de prevención del interbloqueo son muy conservadoras; solucionan el problema del interbloqueo limitando el acceso a los recursos e imponiendo restricciones a los procesos. En el lado opuesto, las estrategias de detección del interbloqueo no limitan el acceso a los recursos ni restringen las acciones de los procesos. Con detección del interbloqueo, se consideran los recursos que los procesos necesiten siempre que sea posible. Periódicamente, el sistema operativo ejecuta un algoritmo que permite detectar la condición de círculo vicioso de espera. Puede emplearse cualquier algoritmo de detección de ciclos en grafos dirigidos.
El control del interbloqueo puede llevarse a cabo tan frecuentemente como las solicitudes de recursos o con una frecuencia menor, dependiendo de la probabilidad de que se produzca el interbloqueo. La comprobación en cada solicitud de recurso tiene dos ventajas: Conduce a una pronta detección y el algoritmo es relativamente simple, puesto que está basado en cambios increméntales del estado del sistema. Por otro lado, tal frecuencia de comprobaciones consume un tiempo de procesador considerable.
6.6 Mecanismos para la migración de recursos
Se refiere en hacer que los recursos locales y remotos de una manera efectiva y fácil. Esta localización de recursos debe ser transparente para el usuario. Los recursos deben estar disponibles de la siguiente manera:
Migración de datos:
Los datos son traídos al lugar del sistema donde son necesitados, pueden llegar a ser desde un archivo (local o remoto) o hasta el contenido de una memoria física.
Características:
Migración de Cálculos:
Los cálculos procesados son llevados hacia otra localización y puede ser eficiente bajo ciertas circunstancias, por ejemplo: Cuando se requiere información de un directorio remoto es más eficiente enviar el mensaje solicitando la información necesaria y recibiéndola de regreso.
Planeación Distribuida:
Los procesos son transferidos de una computadora a otra dentro del sistema distribuido, esto es que un proceso puede ser ejecutado en una computadora diferente de donde fue originado.
Este proceso de relocalización puede ser deseable si la computadora donde se origino se encuentra sobrecargada o no posee los recursos necesarios.
La planeación distribuida es la responsable de todos los procesos distribuidos que se lleven a cabo entre computadoras sean efectuados con criterio y transparencia para obtener el máximo rendimiento.
6.7 Resolución de interbloqueo
Una vez detectado el interbloqueo, hace falta alguna estrategia de recuperación. Las técnicas siguientes son posibles enfoques, enumeradas en orden creciente de sofisticación:
- Abandonar todos los procesos bloqueados. Esta es, se crea o no, una de las soluciones más comunes, si no la más común, de las adoptadas en un sistema operativo.
- Retroceder cada proceso interbloqueado hasta algún punto de control definido previamente y volver a ejecutar todos los procesos. Es necesario que haya disponibles unos mecanismos de retroceso y reinicio en el sistema. El riesgo de esta solución radica en que puede repetirse el interbloqueo original. Sin embargo, el no determinismo del procesamiento concurrente asegura, en general, que esto no va a pasar.
- Abandonar sucesivamente los procesos bloqueados hasta que deje de haber interbloqueo. El orden en el que se seleccionan los procesos a abandonar seguirá un criterio de mínimo coste. Después de abandonar cada proceso, se debe ejecutar de nuevo el algoritmo de detección para ver si todavía existe interbloqueo.
- Apropiarse de recursos sucesivamente hasta que deje de haber interbloqueo. Como en el punto 3, se debe emplear una selección basada en coste y hay que ejecutar de nuevo el algoritmo de detección después de cada apropiación. Un proceso que pierde un recurso por apropiación debe retroceder hasta un momento anterior a la adquisición de ese recurso.
Para los puntos 3 y 4, el criterio de selección podría ser uno de los siguientes, consistentes en escoger el proceso con:
- La menor cantidad de tiempo de procesador consumido hasta ahora
- El menor número de líneas de salida producidas hasta ahora
- El mayor tiempo restante estimado
- El menor número total de recursos asignados hasta ahora
- La prioridad más baja
Algunas de estas cantidades son más fáciles de medir que otras. El tiempo restante estimado deja lugar a dudas, especialmente. Además, aparte de las medidas de prioridad, no existe otra indicación del "coste" para el usuario frente al coste para el sistema en conjunto.
Detección : Se representa la gráfica de recursos
ciclo - Interbloqueo
no ciclo - No interbloqueo
Recuperación :
- Mediante apropiación: Consiste en arrebatarle temporalmente un recurso a un proceso y, posteriormente, reasignárselo. Problemas: Esta acción depende de la naturaleza del recurso, la elección del proceso a suspender depende de los recursos y la recuperación es muy difícil.
- Mediante rollback: Se basa en la verificación periódica de los procesos (recursos asignados a cada uno). Cuando se alcanza una situación de interbloqueo se vuelve a una configuración anterior, y se evita la asignación del mismo recurso al mismo proceso.
- Mediante eliminación de procesos: Se basa en eliminar un proceso conflictivo (bien del ciclo o bien que posea recursos necesarios para otro proceso). Problema: La eliminación de un proceso a mitad de su ejecución para su posterior ejecución completa, puede conducir a resultados incorrectos (ej. un proceso que incrementa en 1 el valor de un campo de un registro de una base de datos).
- Evitar los interbloqueos : Se basa en asignar los recursos de forma cuidadosa. Los algoritmos que evitan los interbloqueos se basan en el concepto de estado seguro.
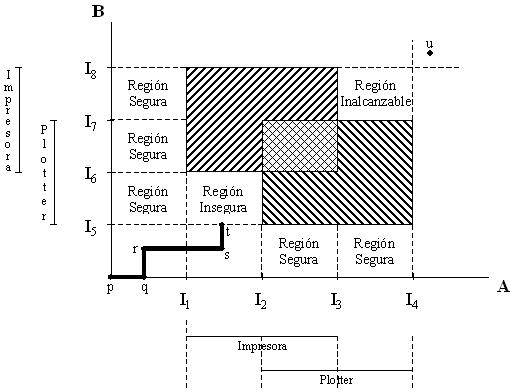
Trayectorias de recursos: Muestran de forma gráfica la seguridad de los estados en la ejecución concurrente de procesos. Ejemplo: 2 procesos y 2 recursos.
Definición de estado seguro: Un estado es seguro si no está bloqueado y existe una forma de satisfacer todas las solicitudes pendientes, mediante la ejecución de los procesos en cierto orden.
Ejemplos para 1 tipo de recurso:
- Estado seguro:
Asig
Máx
Asig
Máx
Asig
Máx
Asig
Máx
Asig
Máx
A
3
9
A
3
9
A
3
9
A
3
9
A
3
9
B
2
4
B
4
4
B
0
-
B
0
-
B
0
-
C
2
7
C
2
7
C
2
7
C
7
7
C
0
-
Libres : 3
Libres : 1
Libres : 5
Libres : 0
Libres : 7
- Estado inseguro:
Asig
Máx
Asig
Máx
Asig
Máx
Asig
Máx
Ningún proceso puede avanzar su ejecución hasta terminar, a no ser que alguno libere
A
3
9
A
4
9
A
4
9
A
4
9
B
2
4
B
2
4
B
4
4
B
0
-
C
2
7
C
2
7
C
2
7
C
2
7
Libres : 3
Libres : 2
Libres : 0
Libres : 4
Un estado inseguro no es estado de interbloqueo, pero puede conducir a éste. Diferencia entre estado seguro e inseguro:
- A partir de un estado seguro, el sistema puede garantizar la conclusión de todos los procesos.
- A partir de un estado inseguro, no se puede garantizar.
Algoritmo del banquero: El banquero tiene créditos disponibles y los reparte entre sus clientes de forma que siempre pueda satisfacer todos los créditos de, al menos, uno de ellos.
- Para un tipo de recurso:
Asig
Máx
Asig
Máx
Asig
Máx
A
0
6
A
1
6
A
1
9
B
0
5
Libres: 10
B
1
5
Libres: 2
B
2
-
Libres: 1
C
0
4
C
2
4
C
2
D
0
7
D
4
7
D
4
7
Est. Seguro
Est. Seguro
Est. Inseguro
- Para varios tipos de recursos:
Proc.
Un. Cinta
Plotter
Impres.
CD-ROM
Proc.
Un. Cinta
Plotter
Impres.
CD-ROM
Rec. Existentes
A
3
0
1
1
A
1
1
0
0
E = (6 3 4 2)
B
0
1
0
0
B
0
1
1
2
Rec. Asignados
C
1
1
1
0
C
3
1
0
0
A = (5 3 2 2)
D
1
1
0
1
D
0
0
1
0
Rec. Disponibles
E
0
0
0
0
E
2
1
1
0
D = (1 0 2 0)
Recursos asignados
Recursos necesarios
Algoritmo:
- Buscar una fila cuyos recursos necesarios sean inferiores o iguales que el vector de disponibles. Si no existe, se producirá interbloqueo.
- Suponemos que el proceso elegido solicita todos los recursos necesarios y termina (libera todos y se añaden al vector de disponibles).
- Repetir 1 y 2 hasta que todos los procesos se señalen como concluidos (estado inicial seguro) u ocurra un interbloqueo (estado inicial inseguro).