Proposed approach of DataInstance
As stated earlier, most applications are about data transformations. What are the data in applications? In most cases, they are the business entities represented in a computer form --- computerized models (see figure 2.1 explaining used terminology).
The approach of "DataInstance" completely changes the way the data model realizations are treated. They are no longer being addressed to as data structures, set of variables holding various parts of the data model, data streams, hash tables, vectors, lists, XML structures, HTTP parameters, ResultSets (component used for accessing relational database data), etc. All these model realizations are being unified and treated as a "DataInstance".

Figure 2.8: Class Diagram: Where does DataInstance fit?
Let's do a little ideological summary, illustrated in figure 2.8. "DataInstance" is an instance of (realizes) "Model Realization" which models (represents) "Business Entity". "DataClass" then holds "DataInstance"'s metadata such as its properties, relationship definitions, etc.
Since this is a key to the whole concept, an example is provided for better understanding. The example consist of three figures, each showing one form of the same *situation*. The forms are related to the term introductory shown in figure 2.1 and also in this section in figure 2.8. The first form shows a real-world situation ("Business Entities"), the second one shows a model of it and the third one shows a model realization using proposed "DataInstance".

Figure 2.9: Real world situation: group of people and a men with contact book
Figure 2.9 shows a real-world situation. There is a group of people, all somehow related together. There could be a mother with her baby-boy, her husband, her neighbour, the husband's colleague from work with his boss, etc. Each of them has name, has been born at certain point in time, is either male or female and has other personal characteristics. Besides the personal characteristic, all of them are somehow reachable: snail mail, email, phone, fax, pager or cell phone; where all these contacts could refer to either home, work, vacation or other location.
The irresolute man on the other side of the picture must use appropriate contact information when he wants to reach some of them.
According to our classification shown in figure 2.1, this real-world situation consist of business entities: people, their characteristic, their relationships and their contact information.

Figure 2.10: Model Diagram: The model of the real world situation
Next figure 2.10 shows a model of the previous real-world situation. The model lacks certain information, such as the people's hair color, their clothing, the mood they are in, etc. All this information exists in the real-world, but is irrelevant for the reason the model has been created for.
By the nature of the information this model is providing, one could *judge* that the model was build for purposes of personal cataloging system: comprehending personal and contact information.
The model consists of an entity called "PersonalRecord" containing person's personal data such as first/last name, date of birth, etc. All possible relationships a person can have with other persons are modeled by many to many relation called "Relationship". The relation is more precisely defined by an attribute class. The attribute description is following:
name: identifies the relationship. Examples are: marriage, parentship, siblings, relatives, employment (boss, employee), etc,
constraints: carries information about possible constraints the relation can have. For example, if the relationship is "marriage" then the constraint could be multiplicity constraint "1 to 1" with "opposite sex" constraint, if monogamy is assumed. Obviously all the constraints would change if either of polygamy (no constrains at all), polyandry or polygyny is considered instead.
private flag: identifies whether the relationship is private (parentship, marriage, etc) or not (boss-employee, etc).
Next entity in the model is "ContactInfo" and is holding person's contact information. This entity is only an abstract one, representing a contact in general, but providing no information specific to any concrete contact type. It only holds the contact's name such as "email", "phone", "fax", etc; and "private flag" distinguishing public versus private kind of contacts.
A person's contacts are accessible via "contacts" relation between "PersonalRecord" and "ContactInfo" entities. The relation is qualified by "id" which enables qualified selection by contact's identifier. The identifier uniquely identifies one instance of "ContactInfo" from within the set (the multiplicity of the relation is 1 to many). Examples of the contact identifier (id) are: email_home, email_work, address_home, fax_office, etc.
All three entities extending "ContactInfo" represent specific contact type: Address, DialNumber and Email. Each of them extends the abstract "ContactInfo" with properties specific to its type.
The summary of the model description is: "PersonalRecord" holds personal information about individual which has many to many relation "Relationship" with other individuals. Relation "contacts" defines set of contacts for each individual. A contact can be either "Address", "DialNumber" or "Email".

Figure 2.11: Object Diagram: Model Realization by DataInstance and DataClass
The model presented in figure 2.10 is also referred to as a "Business Model". It models a real-world situation, but it provides only certain amount of information relevant to particular "business" requirements. Requirements for this model are to describe personal cataloging system, therefore only such information is provided by the model.
Once the business model is complete, it need to be implemented (realized). That is when designer come in place and creates his design how to implement the model. In our case the model is realized using "DataInstance"s. This is why "DataInstance" is referred to as instance of "ModelRealization".
The model realization is shown in figure 2.11. For better understanding an instance diagram is used. It shows set of instances of "DataInstance", one per each entity from the business model. An instance of "DataInstance" does not hold any information about the entity from model, it only holds instance values such as: first name = "Josef", last name = "Vosyka", date of birth = "01/11/1970", etc. The meta-information, shown in the model (entity properties and relations), is stored in the instances of "DataClass". In other words, instances of "DataClass" holds the model information and instances of "DataInstance" holds all values specific to an instance of the model.
More details about how "DataClass" maintains the metadata comes in the following section.
Since all the "ModelRealizations" were unified into "DataInstance", it implies many advantages. Let's discuss them in more detail:
data access unification / business entity representation ("ModelRealization") type unification
data storage technique generalization
ease of component-ation (common functionality encapsulation)
standard metadata access (classification)
solid design - no code specific to storage, only intuitive object interactions.
Let's go over the advantages and discuss them in more detail using examples.
Data access unification / business entity representation ("ModelRealization") type unification
This section addresses the weakness described in section "Data Type Diversity". As illustrated before, the obstacle of having un-uniform business object type is the need to adapt/accommodate all the existing types, see "HttpRequest", "Request", "3rdRequest" from figure 2.3. Next figure 2.12 shows the type unification using "DataInstance" accommodating (adapting) into three different types (where "types" means types (classes) of instances of "ModelRealizations"): "HTTP params", "Stream" and "FormFieldValueHolders".

Figure 2.12: Data Flow Diagram: Adaptation process into DataInstance
Figure 2.12 shows three possible model realizations: "HTTP params", "Stream" and "FormFieldValueHolders". All of them implement model "PersonalRecord" shown in figure 2.10. The model models a personal record originating from three different sources and then being consequently stored in a database by "StorePerson'sRecordProcedure" procedure. The three sources are: "HTTP service", "Socket" and "GUI edit form". Let's discuss the three cases in more detail, to emphasis their diversity:
HTTP params: "HTTP service" is a process residing on "HTTP server" and is taking care of processing HTTP requests. When user enters data in WWW form (edits the person's record) and submits the form to the server, then the form field data (representing a "ModelRealization" where "Model" is representing the person's record) are accessible on the server as HTTP parameters.
Stream: is a component providing sequential access to data. It also provides an abstraction of the data's origin. In our case the data are transmitted over the network through socket based transportation. An example could be a legacy system consolidating the personal records from various places and sending them to our server via Internet.
FormFieldValueHolders: serves as a holder of GUI form field values. GUI form consist of set of input fields of various types, such as simple/rich text box, single/multi choice, etc. When user enters appropriate data in the fields and submits the form (hits OK button), the entered data are placed in "FormFieldValueHolders".
In our case, the GUI form consist of five fields each dedicated for one property of "PersonalRecord" entity, which is part of the model shown in figure 2.10. When the form get submit, a set of five "FormFieldValueHolders" is initialized. The set represent the "ModelRealization". According to the terminology introduced in figure 2.1, it is "Discrete IDMR" --- "set of variables".
As one can see, all these various components represent the same business entity --- the "PersonalRecord" --- which is further processed by "StorePerson'sRecordProcedure" procedure. If there is no type unification, then the procedure would have to take it into account and be prepared for all possible types. On the other hand, if all the possible types adapt into unified "DataInstance", then the procedure must work with only one type --- "DataInstance".

Figure 2.13a: Class Diagram: The adapters
Figure 2.13a shows such an adaptation using well know "Adapter" design pattern. Each of the adapters implements "DataInstance" interface to unify the type and delegates all interaction to original (adapted) component.

Figure 2.13b: Class Diagram: Business Procedure signature
Since all the types are unified, the procedure accepts only one type -- "DataInstance", see figure 2.13b.

Figure 2.14: Interaction Diagram: operation delegation during the adaptation
The interaction diagram in figure 2.14 shows how the unified method invocations are delegated (adapted) through the adapter ("RequestDataInstanceAdapter") to the original object ("Request").
As need of new types arise, new adapter objects can be developed, with no affect to existing code.
Data storage technique generalization
The four basic data storage operations are:
lookup: lookups an instance or instance set from within the class.
insert: inserts an instance into the class.
update: modifies an instance already existing in the class.
remove: removes an instance from the class.
Implementation of all these operations depends on three factors:
particular storage technique, such as relational database, object database, XML file, CSV file, JavaTM properties file, etc.
structure and nature of the data being stored: every bit of the data has dedicated location where it resides in the storage. In case of RDB, each object may have dedicated one table or set of tables to be stored in and also particular mapping of its properties to table rows. There can be further customized logic when storing the data such as merging two properties into one database column, etc.
storing strategy: this is very similar to the previous item, but it has more strategic nature. For example, when an object need to be stored in relation database, several approaches can be used: specialized tables are used --- one per each object's class, or generic tables, where objects of all classes are stored, etc.
Now, what if an object is being retrieved from XML structured file, then is being modified and consequently placed into relational database? Or, what if an application is using relational database for storing the objects and now the requirement comes to switch to object oriented database? When traditional approach is in place then a lot a code modifications have to be done to fulfill the requirement. With generalized data storage technique on the other hand, the only need is to replace "ObjectStore" layer, which can be done in minutes.
The following text describes the technique of "data storage generalization".

Figure 2.15: Class Diagram: DataClass'es commands
As stated earlier, "DataClass" maintains the metadata of "DataInstance". One of the metadata is the information how to store "DataInstance"s in underlying storage place. The information is hold by instances of class "Command". They represent commands for all four storage operations: lookup, insert, update and remove. There is one set of the four commands for each environment identified by env_id. The environment represents combination of the three factors just discussed: storage technique, data structure and storage strategy. Examples of the environments are: relational database + specialized tables; relation database + generic tables (OO schema); object database; XML file; etc. Class diagram presenting just described approach is shown in figure 2.15.
Such a schema enables the underlying components --- responsible for storing the "DataInstance"s --- to choose the appropriate set of commands for given environment. This way, one particular "DataInstance" can be retrieved from XML file and consequently stored in an object database, without a need of developing extra code.

Figure 2.16: Class Diagram: Abstraction layers
In order to achieve the abstraction, certain abstraction layers were designed. Their schema is shown in figure 2.16. One can see that there are three abstraction layers. They are closely related to the three factors discussed at the beginning of this section: storage technique, data structure and storage strategy. Let's discuss the layers in more detail:
Data Type Abstraction: since "DataInstance" is widely used for all "ModelRealization"s in the application then all the "data types" designer/developer has to deal with is "DataInstance". Note that "data type" refer to the type (class) of given "ModelRealization". Since the rest of "ModelRealizations" (other then "DataInstance") are being unified into "DataInstance" by adapters, then the "Data Type Abstraction" is achieved. It means that it does not matter what "data type" is one dealing with, because they all end up being "DataInstance", which delegates all the interaction to the component of the original "data type".
Figure 2.16 shows "Data Type Abstraction" as a specific "Abstraction Layer" (inherits), which is realized by "DataInstance" and "DataClass".
Object Serialization Abstraction layer decomposes an object into series of object elements, which are then consequently stored by "Data Storage Layer". In other words, the layer contains the logic of how the object is decomposed/composed into/from elementary pieces. This enables the technique of switching between storing on object into the object's class specific database tables versus generic object oriented tables.
In the first case (class specific tables), the instances of the class "PersonalRecord" resp. "Address" are stored in table called "PersonalRecord" resp. "Address" and the relation between a person and his/her contacts is stored in "Contacts" table (see figure 2.10, where this example is taken from).
In the second case (object oriented tables), the instances of both "PersonalRecord" and "Address" classes are stored in table called "Instances" and the relation between a person and his/her contacts is stored in "Relations" table.
As one can see, there is a conceptual difference between the "class specific" and "object oriented" storage approach. If there is no "Object Serialization Layer" in place, then it requires extensive re-design and re-implementation with huge risk of stability of the application. On the other hand, if the "ObjectStore" is in place, then the change might require just a simple modification of the application property configuration.
Figure 2.16 shows "Object Serialization Abstraction" as a specific "Abstraction Layer" (inherits), which is realized by "ObjectStore".
Data Storage Abstraction layer takes care of the actual "storage" of the object's elements, produced by the upper layer. It does not know anything about the object structure nor about the meaning of the data, it simply stores what is requested to. As shown in figure 2.16, this abstraction layer is realized by "DataStore". Example implementations are: RelationalDBDataStore, ObjectDBDataStore, XMLFileDataStore, CSVFileDataStore, EJBDataStore, etc.
Figure 2.17 shows a class diagram of both the "ObjectStore" and "DataStore". One can see that the operations of "ObjectStore" are strictly object oriented. All of them either pass "DataInstance" as parameter or return one back as return value. In all cases a "DataClass" is passed as parameter, indicating the class of the "DataInstance". Since the "DataClass" contains the "DataInstance"'s metadata, it is crucial for the store process.
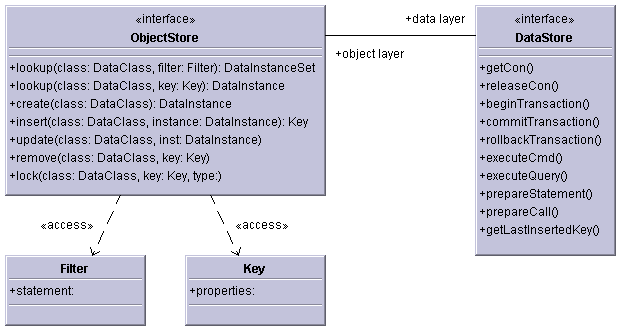
Figure 2.17: Class Diagram: ObjectStore and DataStore
The two helper classes, "Key" and "Filter", define the scope of instances within a set. Using "Key" class, one instance is uniquely identified from within a set. Using "Filter" class, a subset of instances is identified from within a set, using filtering rules, such as: all instances with value of property "first name" equal to "Josef".
The operations of "DataStore" are --- as opposed to "ObjectStore" --- data oriented. "DataStore" deals with elementary data such as strings, numbers, bits, dates, etc. "DataStore" operations are categorized into three groups. The first one takes care of obtaining and releasing connection to the underlying data source. If the data source has client-server architecture, then the connection represents the connection from client to the server, such as database connection, socket connection, etc.
The second category consist of transaction operations. Transactions are essential in multi-process environment and therefore the basic "begin", "commit" and "rollback" operations are provided, to *insure* the data consistency.
The third category consist of operations responsible for executing the elementary data storage commands, such as "SELECT", "INSERT", "UPDATE" and "DELETE" (relational database SQL commands), etc.
The following four interaction diagrams show the basic storage operations (lookup, insert, update and remove) discussed at the beginning of this section. An emphasis is given to interaction of the individual layers.

Figure 2.18: Interaction Diagram: lookup operation execution
Figure 2.18 shows the "lookup" operation, which retrieves one "DataInstance" --- uniquely identified by "Key" --- from the underlying data source (the actual storage place). There are two objects necessary for execution: "DataInstance" and "Key". "DataClass" contains the "DataInstance"'s metadata which (1) determines what "DataInstance"'s property should be initialized, (2) contains the appropriate storage commands, (3) may also contain specific storage rules, etc. The other parameter is "Key" which is used for unique identification of the instance to be retrieved from the set (class).
The interaction sequence begins with invoking "lookup" event on "ObjectStore" which is the "Object Serialization Layer". It obtains the elementary data from underlying "Data Storage Layer" (realized by "DataStore") and constructs an instance of the requested "DataInstance". In order to do that, "DataClass" is inquired for a command which is executed on a connection obtained from "DataStore". Once the command is executed, appropriate elementary data are retrieved and used for initialization of the new instance of "DataInstance", which is the returned result of the "lookup" operation. After the command execution is finished, the connection is returned back to "DataStore" so it can be used again by other processes.
Once the "DataInstance" is retrieved, its data (property values) are accessible via multiple calls of "getObject" operation.

Figure 2.19: Interaction Diagram: insert operation execution
Figure 2.19 shows the "insert" operation, which inserts one "DataInstance" into the underlying data source (the actual storage place).
The interaction sequence first shows how an instance of "DataInstance" is created and initialized. A "DataInstance" is instantiated by execution of "instantiate" operation on a specific "DataClass". After that, the instance is initialized by multiple calls of "setObject" operation.
Once there is an initialized "DataInstance", it can be inserted into "ObjectStore" by invoking "insert" operation. Again, "ObjectStore" is the "Object Serialization Layer" which breaks down the "DataInstance" into elementary data and makes appropriate calls to underlying "Data Storage Layer" (realized by "DataStore"). In order to do that, "DataClass" is inquired for a command which is executed on a connection obtained from "DataStore". The command is executed with the elementary data which results in the *actual* data insertion. After the command execution is finished, the connection is returned back to "DataStore" so it can be used again by other processes.

Figure 2.20: Interaction Diagram: update operation execution
The "update" operation, shown in figure 2.20, is very much the same like the "insert" one. The only difference is that the "update" operation expects an older instance of "DataInstance" already residing in the "ObjectStore". It means that "ObjectStore" has to identify the instance to be updated. As already stated, for the purpose of uniquely identifying an instance from within a set is used "Key" object. The "Key" together with the actual "DataInstance" is being beaked down, by "ObjectStore", into elementary data, which is consequently stored in "DataStore".
The interaction sequence is more complex then the '"update" operation only' version. It first retrieves a "DataInstance" --- identified by specific "Key" --- from "ObjectStore" using "lookup" operation. Then it alters the "DataInstance" by multiple invocations of "setObject" operation and then it persists the modifications by executing the "update" operation. The rest of the interaction is pretty much same like the already described one for "insert" operation.

Figure 2.21: Interaction Diagram: remove operation execution
The last operation "remove", shown in figure 2.21, is the simplest one. The only two parameters one needs to execute the "remove" operation are: "DataClass" and "Key". "DataClass" represents the class of "DataInstance"s, where the required instance --- uniquely identified by "Key" --- is removed from. Note that in this case, no "DataInstance" is necessary for completition of the "remove" operation. The "Key" holds sufficient information: just identifies the instance to be removed.
The sequence starts with invocation of "remove" operation on "ObjectStore". "ObjectStore" breaks down the "Key" object into elementary data. Next, "DataClass" is inquired for a command which is executed on a connection obtained from "DataStore". The command is executed with the elementary data which results in the actual data deletion. After the command execution is finished, the connection is returned back to "DataStore" so it can be used again by other processes.
Ease of component-ation (common functionality encapsulation)
Ease of component-ation (building components) highly depends on the previously discussed "ModelRealization type unification". With such unification, library components providing generic functionality can be build. Examples are: "Debug" - debugging utility dumping content of given "DataInstance" on given output device; "XDataInstance" - transforming "DataInstance" into XML format; "DataInstanceView" providing base functionality for displaying a "DataInstance" in a GUI based view; and many others.
"DataInstance" provides unification of the "BusinessObject" / "ModelRealization" type (class), but there still are variety of elementary (primitive) instance property value types, which application designer has to deal with. All the previous scenarios access the "DataInstance"'s property values by "getObject/setObject" operations, which assumes the value type as generic "Object". This is not sufficient in many occasions. In most cases, more primitive value types are required, for example: numbers (integers, floats), strings, dates, streams, etc.
Since there is such a wide variety of primitive types, then frequent type conversions are required. An example is the parameter processing scenario shown in figure 2.6. The original parameter value type is a "string", but other types are often required. In case of the "PersonalRecord" model, shown in figure 2.10, certain properties are of type string (first name, last name), but others need to be converted, for example: "date of birth" is date; "marital status" is enumeration of string values; "age" is an integer (not presented in the model though); etc.
Yet another level of differentiation of the access to property values is whether the values are only to be read (read-only "DataInstance") or whether the property values need to be changed. The reason for such a differentiation is that many approaches do not need nor provide the ability to set the property value and furthermore, it would require sophisticated coding to add the value modification functionality. Examples are "DataInstance"s built upon: "ResultSet", which is read-only component used for accessing results from SQL "SELECT" query; HTTP parameters providing read-only access to values entered into WWW form; "Properties" which is read-only JavaTM component used for accessing configuration properties; etc.
All these requirements: the need of easier "component-ation", the need of primitive value type conversion and the need of read-only versus full access, resulted into finer design of the "DataInstance". The class diagram is shown in figure 2.22.

Figure 2.22: Class Diagram: DataInstance hierarchy tree
The base component is "Model", it provides the means of "mutation" into required "DataInstance" type, this functionality is widely discussed in the following text. The "Model" also holds relation with "DataClass" which classifies instances of the "Model".
There are three aspects the objects in the class diagram are divided by. (Just note that the term "object" is used because the class diagram consist of: classes, interfaces, packages, relations, etc; and they are all considered objects). The aspects are:
Access to the "DataInstance"'s property values: read only versus full access (read + write).
All the components in the hierarchy tree are divided by this aspect into two categories: (1) "models" - representing read only "DataInstance"s and (2) "instances" - representing full access "DataInstance"s. The read-only access is represented by "get*" operations and the write access is represented by "set*" operations. The "*" (star) stands for the primitive type the operation deals with --- either returns or passes in as input parameter. Example of the operations is:
Integer getInteger (Object propertyKey); void setInteger (Object propertyKey, Integer value);Multiplicity of the instance: one single instance versus instance set.
All the "DataInstance"s requiring access to multiple instances are recognized by "ModelSet" interface.
"DataInstance"'s property value type variation: "Object" versus "String" versus one of "Integer", "Float", "Boolean", "Date" and "Stream".
The classification by this aspect is based on primitive value types, given "DataInstance" is dealing with. The "DataInstance"s are divided into three categories identified by the name prefix: "Object", "String" and "Data". As the name *says* the "DataInstances" from the "Object" category provide methods dealing with type "Object", the "String" category deals with type "String" and finally the category "Data" provides methods for dealing with all other basic value types such as: "Integer", "Float", "Date", "Boolean" and "Stream".
As of writing these lines, a naming collision was *encountered*. So far, "DataInstance" has been referred to as a proposed realization of a "Generic Business Object" which is successor of a "ModelRealization", see figure 2.1. Till now, it was assumed that there is only one component --- the "DataInstance" --- but after studying the class hierarchy in figure 2.22, one can see a whole lot of objects, including "DataInstance". Conceptually, all these objects represent "DataInstance" as known from previous text. Only since now on, a finer *differentiation* of "DataInstance" is defined and coincidently also contains object named "DataInstance".
Let's describe several cases, to shed some light on the just described classification by the three aspects. "StringModel" provides read-only access ("getString") to the property values. The returned value type is "String". "StringInstance" provides write access ("setString") to the property values and inherits the read-only access from "StringModel". The value type is "String". "DataInstance" provides write access to the property values and inherits the read-only access from "DataModel". The value types are "Interger", "Float", "Date", "Boolean" and "Stream". "DataInstance" is the *farthest* object in the inheritance tree, besides the "DataModel"'s operations, it also inherits full access (read and write) from "ObjectInstance" and "StringInstance".
Since there is so many different types, it is necessary to swap from one type into the other. For example from "StringModel" into "DataModel", this occurs when the original source of data is "string" oriented, such as XML file, but certain property value types are numeric and there is a need of performing numeric operations on them. An example is a date property "date of birth" which is used for calculation of person's age, in this case type "date" is in need rather then the original "string".
The mechanism of "swapping" one "DataInstance"'s type into the other is design pattern called "Adapter". It adapts into the required type by (1) realizing (implementing) given interface, (2) adding certain functionality to accommodate to the new type and (3) delegating appropriate interaction to the original object (of the original type). For more about "adapter" design pattern see [2].
The two following figures show examples of such adapters: "Model2ModelSetAdapter" and "String2DataModelAdapter". The first one (figure 2.23) adapts an instance into type "ModelSet". It extends class "ModelBaseImpl", which provides basic implementation of "Model"'s operations. Then it realizes "ModelSet" interface to achieve the required type which is what the adaptation is about. In other words, "ModelSet" is the required type that the new instance should adapt to. The "adaptation" relation holds the reference to the original instance --- the adaptee. The relation is used for operation delegation to the original instance.

Figure 2.23: Class Diagram: Model2ModelSetAdapter
Figure 2.24 shows class diagram for "String2DataModelAdapter". This one is widely used when the primary data source is "string" based (such as XML file, HTTP parameters, configuration property file, etc), but other primitive types are required. The "String2DataModelAdapter" holds all the conversion methods from string to all the other supported types: "Integer", "Float", "Date", "Boolean" and "Stream". It extends class "ModelBaseImpl", which provides basic implementation of "Model"'s operations. The "adaptation" relation holds the reference to the original instance --- the adaptee. Then it realizes "DataModel" interface to provide the required type.

Figure 2.24: Class Diagram: String2DataModelAdapter
All additional operations which need to be implemented in order to realize the "DataModel" interface contain the conversion from string to the type, specific for given operation: "Integer" for "getInteger", "Float" for "getFloat", etc. All these operations first obtain the string value from the original instance (adaptee) by calling "getString" operation and then convert the string to the requested value type.

Figure 2.25: Data Flow Diagram: Example of the type mutation
Since this is one of the key features of the "DataInstance" concept, an example is presented to demonstrate it in more detail. Figure 2.25 shows data flow diagram presenting consequent transformations of a model of "Person", taken from figure 2.10. An instance of a model of a "Person" is primarily stored in XML file. The file is being parsed by DOM parser which produces a node tree representing the XML structure of the "Person". The node tree is referenced in the diagram by its root node "DOM Node". For more about parsing XML see [10] or [12]. The DOM tree then adapts to "StringModel" using "DOMStringModelAdapter" which is one of the standard adapters which are part of the proposed architecture. The instance of "DOMStringModelAdapter" then enters a procedure "Business Procedure", which performs certain calculations upon given person's property values.

Figure 2.26: Class Diagram: Example of the type mutation
The procedure (shown in figure 2.26) is open and makes no assumptions about the type of the incoming "DataInstance". This is achieved by expecting generic type "Model", since this is the very root of the class hierarchy, there are no type restrictions. It is up to the body of the procedure to decide what type of "DataInstance" is required for its execution and swaps from "Model" to the required one. For this purpose, set of operations is provided by "Model", which support the mutation from one type to the other. All the operations have prefix "as" followed by name of the required type. Say, operation "asStringModel" returns instance of type "StringModel", etc. If the operation is called on an instance of type "StringModel" then such is returned, if not, existing instance is adapted into the required "StringModel" using already described design pattern called "Adapter".
Since this one can be a bit more difficult to understand, an interaction diagram is provided in figure 2.27.

Figure 2.27: Interaction Diagram: Example of the type mutation
The interaction diagram does not display the interaction for the complete sequence shown in the flow diagram in figure 2.25. It starts from the creation of "DOM Node". The first event is just a symbolic assignment, a starting point. Then an adapter from "DOM Node" to "StringModel" is created and initialized by the instance of "DOM Node".
Please note, that most of the instances in the diagram represent different variations of "ModelRealization" of model of a "Person" presented in figure 2.10. They are recognized by the name of the instance followed by name of its class (inside the green top boxes).
The reason of creating the "DOM2StringModelAdapter" is that the business procedure "calcAge" accepts an input parameter of type "Model", representing a person the age is calculated for. Since the "DOM Node" is not of type "Model", it need to be adapted. Next event is execution of the business procedure which passes the just created instance of "DOM2StringModelAdapter" as input parameter. As stated earlier, the procedure is open and makes no assumption about the type of the input parameter and accepts generic type "Model". Since the age is calculated out of "date of birth" property value which is of type "Date", then the "DataModel" type is required (the only one providing type "Date").
The "DataModel" is obtained by invoking event "asDataModel", which is consequently satisfied by creating "String2DataModelAdapter" and initializing it with a reference to self --- the instance of "DOM2StringModelAdapter". Then the invocation of "asDataModel" finishes by returning the instance of required type --- "DataModel" --- which is in fact the "String2DataModelAdapter" (realizing "DataModel" interface).
Once the "DataModel" is available, the person's age can be calculated ("calculateAge" event) by obtaining the person's "date of birth" and current date and performing the simple mathematics. The obtaining of the person's "date of birth" is slightly more complex and it is the last missing piece to the mosaic. When the "getDate" operation is called on the instance of "String2DataModelAdapter", then the adapter has to first obtain the string value from the original object --- the adaptee --- then convert it into "Date" type (by "convertString2Date") and then finally return it. The extra bit of the complexity is that the original object --- the adaptee --- is also an adapter, this time an adapter from "DOM Node" to "StringModel", therefore the "getString" operation gets delegated to the very original "getNodeValue" operation of the instance of "DOM Node".
To make the example complete, an instance diagram is provided to view the complexity of the adapter's relations. The diagram is shown in figure 2.28.

Figure 2.28: Object Diagram: Example of the type mutation
The overall picture would not be complete without a class diagram revealing the relationships and inheritance of the adapters classes. The class diagram is shown in figure 2.29.

Figure 2.29: Class Diagram: Example of the type mutation
The previous example is also an example of the "component-ation": the functionality of converting value types is build into the adapter and is reused whenever requested. There is no need to write the convertion code and then copy and paste it to all other locations. The logic is build into intuitive component --- "String2DataModelAdapter" --- and is used from there when it is appropriate: seamlessly and behind the scenes by mutating existing type of "DataInstance" into "StringModel" by calling convertion operation "asStringModel()".
There is set of five standard adapters providing sufficient ability to convert between all required types from the hierarchy tree presented in figure 2.22. The adapters are shown in class diagram shown in figure 2.30. Their intuitive names gives self-explaining description of what type are they adapting from and to. "Model2ModelSetAdapter", for example, adapts from "Model" to "ModelSet"; "Object2DataModelAdapter" adapts from "ObjectModel" to "DataModel"; etc.

Figure 2.30: Class Diagram: Available adapters
For the sake of complexity, a class diagram presenting all the adapters including their relations is shown in figure 2.31. One can see, that the relations made the overall picture very unclear, which is why new approach was re-designed and proposed on the next figure.

Figure 2.31: Class Diagram: all adapters, the complete picture
Figure 2.32 shows the redesigned adapter class diagram. The key to the improvement is the base class "Adapter" extending the "ModelBaseImpl" class to inherit all the basic implementation of "Model" methods. The relation "adaption" between the "Adapter" and generic "Model" represents the reference to the original adapted object --- the adaptee. All the specialized adapters then just extends the base "Adapter" class and realize (implement) the interface of the type they are adapting into.

Figure 2.32: Class Diagram: all the adapters, in new fashion
Standard metadata access (classification)
This feature has significant impact on the complexity of the overall solution. Since the "DataInstance"'s metadata represents the meaning of the data (it represents the model), then it has major influence in the possibility of building generic components. It means that if a component uses the metadata for its functionality execution, then the component is not tight to any specific class of "DataInstance"s and therefore it can be reused across all available classes without limitation. Examples are: "DataInstanceView", "XDataInstance", value validation routines, etc.
Let's say that there is a need to build user interface for the model shown in figure 2.10. If the application designer does not have access the the metadata information, then he/she is forced to build a component specific for the model, such as "PersonView". On the other hand, if the designer has the comfort of having the metadata information available, then building genericly reusable component "DataInstanceView" is straightforward. Such a component can then be reused for displaying the contact data such as "Address", "Email", "DialNumber" and also all the other "DataInstance"s available in the system.
The "XDataInstance" is a perfect example of using the metadata. It is used for converting a "DataInstance" into XML format. In this case is the metadata used to determine what are the properties to be read from the "DataInstance" and stored in the XML. The XML's DTD might be either generic object oriented following the same class schema the "DataInstance" have or it might be parametrized by custom DTD mapping.
The last example, the "value validation routines" is another great show case of using metadata for generic purpose functionality. Each "DataInstance"'s property can have value validation rules associated with it. These rules can be, for example, applied in the setter ("set*") methods of all the "*Instance"s, shown in the class diagram in figure 2.22. It has several advantages. First, the validation execution can be applied for all classes of "DataInstance". Second, when the validation rules get changed, then the change only need to be propagated to the metadata and it get reflected immediately without a need of changing the actual code.
The metadata must hold information about "DataInstance"'s properties, information about relationships with other "DataInstance"s and inheritance information. To capture all this, a set of classes has been designed. It is shown in figure 2.33.

Figure 2.33: Class Diagram: metadata model
Two already known elements are the interface "Model" --- representing the most abstract "DataInstance" --- and the class "DataClass". Since the "DataClass" holds the metadata of the "DataInstance" and conceptually represents the class of the "DataInstance"s then these two are in relation called "classification", where one "DataClass" can be related to many (0..*) instances of "Model".
All remaining elements in the diagram model the metadata which can be divided into two major categories: the properties and relations. The properties are available to the "DataClass" via "properties" relation qualified by "name" (the property name). Just note that "qualified" relation is relation with multiplicity "one to many", where an instance (from the "many" relation end) can be looked up by the qualifier (kind of a hash code). Each property holds its name, type (such as Integer, Float, Date, Boolean, ...), flag whether it is required or optional, scale, precision and value validation rule.
"DataClass"'s inheritance is also supported and modeled by "abstraction" relation with multiplicity "one to many", which means that multiple inheritance is possible. A super-class can be looked up by its name, which is modeled by the relation qualifier "name".
The relations a "DataClass" have with other ones are modeled by class "Relation" with relates to "DataClass" by qualified relation "relations". The class "Relation" maintains all classes participating in the Relation by relation "relatees". In order to support heterogeneous relations, the multiplicity of the relation "relatees" is "one to many". A "Relation" can also have an attribute class associated with it, which is modeled by "attribute" relation with "DataClass".
The "RelationKey" defines a set of properties realizing the relation hookup into the "DataClass"es participating in the "Relation" (the relatees). The "RelationKey" is specific to the Relation implementation.
The "lookup keys" relation between "DataClass" and "Key" defines a set of properties which the "DataInstance"s can be looked up by. This is used, for example, for definition of database indexes, etc.
Because the previous description got a bit polluted by the terminology conflicts, such as model relations versus the modeled relations, etc; an example is provided to clear as much misunderstanding as possible. It is an instance of the described class diagram presenting the model from figure 2.34.

Figure 2.34: Class Diagram: Example instance of the metadata model