Problem Description
Nowadays, XML-aware components use two most widely recognized standards --- SAX and DOM (for more about SAX and DOM see the references [10] [11] and [12]. One could think of these standards as a communication protocol used when components want to talk XML. Figure 3.1 shows a generic data flow: an input data in XML format ("InputDocument") flows into an application ("Application") which transforms the data and then either stores them ("OutputDocument") or sends them to other application ("Application"). All the interaction is realized through XML interface, either SAX or DOM.
Throughout the rest of this chapter, the document entering an interaction via XML interface will be frequently referred to as "InputDocument".

Figure 3.1: Data Flow Diagram: generic example of XML data flow
Figure 3.2 shows the same diagram, but for more specific situation. It is XSLT transformation performed by "XSLT engine" which takes data document in XML and a style-sheet document in XSL and produces HTML file. In the example, both input data (XML and XSL) are read by a parser which uses DOM for the XML document and SAX for XSL document. The result is produced through SAX which uses "FileDocumentHandler" which stores the output in a file.
Just note that this figure should illustrate more specific realization of the XML data flow --- the realizations of XML interface --- shown in previous figure 3.1.
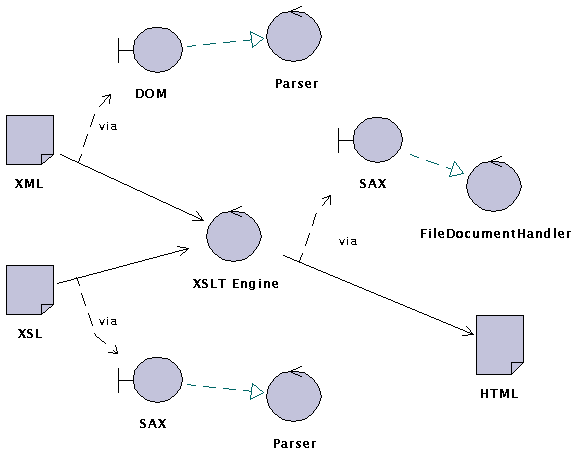
Figure 3.2: Data Flow Diagram: rendering XML document into HTML file using XSL style sheet
This scenario is straightforward when dealing with all text documents. All necessary components --- parser, handler --- are in place and well adopted. Example is: xercies, xalan, saxon, etc.
The difficulties might occur when the "InputDocument" is either not in XML format and/or reside in various sources: DB, business object, data structures, streams, other data storages like search engine DBs, etc; and the worst of all, the combination of all of above.
In this case the strategies miss any kind of concept. The most typical solution is generation of a string (text held in memory) containing XML representation of the desired input data.
For better understanding, let's illustrate more complex example where the "InputDocument"'s elements come from various sources and their original format is both XML and non XML.
Figure 3.3 shows the example and the "InputDocument"'s elements data sources, figure 3.4 shows detailed listings of the XML structure of the "InputDocument", produced once all the data are retrieved from their original data sources and converted into XML.

Figure 3.3: Example: "InputDocument"'s elements data sources
The "InputDocument" consist of root element "page" which in turn consist of four sub-elements: "content-info", "content", "nav-bar" and "footer". Let's describe the sub-elements in more detail:
"content-info": is one-child-only element which content is invariant and resides in a string held in memory heap.
"content": contains the content of the page. The actual content resides in relation database. The content could be complex hierarchical structure mapped in number of database tables such as: "articles" table containing publications; referring to "contributors" table containing authors, editors, illustrators; also referring to "contributions" table containing reviews, feedbacks, etc.
The just described example of the element should only illustrate possible need of transformation of complex data stored in relational database into hierarchically structured XML. To keep our example simple, "content" element will contain only one simple sub-element "article".
"nav-bar": is an example where the data is stored in an object residing in computer memory. The object provides the data accordingly to its current state, in this case it shows which one is the selected item in the navigation bar.
Notice that the object is responsible in providing the data in XML format, but it can store them in whatever internal form --- probably vector of "Item" instances.
"footer": contains rich text displayed at the bottom of each page. The content resides in a file and is already in XML format.

Figure 3.4: Example: detailed listings of the "InputDocument"'s resulting XML structure
Now, there is number of strategies how to compose the resulting structure (shown in figure 3.4) out of the data sources (shown in figure 3.3). The next two sections shows first a typical and most usual solution and then proposed solution - the idea of xObjects. Both sections also discuss the advantages and disadvantages of each other.