Strategies For Successful Integrations
By JP Morgenthal
Optimize
Understanding information and application
requirements helps enterprises sort out integration challenges.
Integrating applications across enterprise systems is a priority for most
businesses because they can drive efficiencies between disparate users, both
internally and outside the enterprise, including customers, suppliers, and
partners. As a result, businesses significantly improve decision-making and
boost productivity.
But the move to apply an EAI or an EII (enterprise information integration)
strategy requires careful consideration. Identifying your information-technology
requirements correctly as either data or process integration is critical to
selecting the right software to fulfill business requirements.
Every integration strategy may require changes to one or more of the
following elements: process, supporting infrastructure, staffing resources, or
organizational structure. Additionally, other identifiers, described in detail
later, will guide you in selecting the solution that best fits your business
needs. Most importantly, all integrations are not the same and, therefore, can't
be accomplished using a single approach or toolset.
Early integrations were expensive and generated a significant amount of
one-off code. These projects, and subsequently the tools to simplify
integration, focused on moving data between applications, where each one needed
the data in a different structure and format. In addition, if the systems were
separated by geographical or physical boundaries—for example, across suppliers
and partners—the integration required reliable messaging to deliver the data.
Integrating systems in this manner significantly increased complexity,
leading to the rise of hubs and brokers to mediate connections and smoothly
integrate systems. This movement spawned the EAI tools that define the current
marketplace.
EAI tools were created to generically support the integration of enterprise
applications with legacy applications and to better support new-business
initiatives. Ignoring the differences in integration requirements—or being
misled about the capabilities of EAI tools by vendors—has caused delays and
budget overruns as high as 70% by some estimates.
For example, one financial-services company suffered $1 million to $2 million
in losses due to delays when integrating a newly acquired financial portfolio.
These delays ensued because the company used an EAI tool to enable their
analytics applications to access the new portfolio data. The company would have
integrated the new portfolio data faster using an extract, transform, and load
or data-integration tool, and it would have saved money.
Recently, the IT industry has recognized that data integration and process
integration are different enough practices to require different tools. This has
created a new practice called enterprise information integration. EII is
creating the need for tools beyond EAI services to provide additional
capabilities such as metadata management and federated-query optimization, which
provides unified access to information and databases.
Different Approaches
The EAI practice manages transactional context across two or more systems as
part of a single business event. In essence, the practice of EAI is to make two
or more applications operate as one. Examples include integrating an existing
accounting system and inventory system to provide customers with a single,
vendor-managed point of contact.
EII is defined as the automated process of turning data into information. Ted
Friedman, analyst with Gartner Inc., elaborates: "EII is a goal, not a
technology." EII tools create a unified view of data.
Given these definitions, it's unlikely that any practitioner would use the
tools designed for EAI to solve EII problems. However, this is exactly what's
been occurring in IT over the past five years. In fact, in my eight years'
experience working with major companies on integration projects, two-thirds of
supposed EAI projects were improperly identified as EII projects, such as
corporate dashboards and Web-based portals. But EAI and EII practices do share
some overlapping characteristics, namely in transformation, aggregation, and
semantics.
The brokers and hubs that were discussed earlier simplified integration
because they were tasked with transforming data to make two systems communicate.
Likewise, in order for EII to create new information structures, it must also
provide some data-transformation capabilities. EII's transformation requirements
are different because it prioritizes the value of the data instead of its
structure; EII provides greater access options.
Moreover, EAI tools require aggregation support to account for gaps between
systems' data structures. For example, to satisfy the input requirements for the
"remove item from inventory" business event, we may need data from both the
sales system and the customer-resource system. Therefore, we will aggregate data
from these systems to create a complete data structure to pass to the inventory
system. With EII, aggregation is about the creation of new information
structures.
As outlined above, it's reasonable to assume that when presented with an
information-integration problem, an inexperienced integrator might use an
existing EAI toolset to try and solve an EII problem. But CIOs should be asking
themselves, "Do I need to invest in multiple integration toolsets in order to
solve all of my integration needs?" The answer isn't always straightforward.
The Rise of the SOA
Some believe that integration will one day become a nonissue as intelligent
systems identify and translate data dynamically without additional
configuration. In my opinion, this may be possible, but it's very far off in the
future.
One of the first technologies to limit integration complexity is
service-oriented architecture. SOA is based on open standards that allow
applications to dynamically locate and communicate with a software service. SOA
simplifies integration by creating a homogeneous view of existing systems and
data, but it doesn't eliminate the need to aggregate and transform across
applications and data sets.
SOA has additional obstacles. It moves the processing closer to the data and
application endpoints, but it doesn't eliminate the core functionality of the
broker/hubs or the information-integration engines. Still, SOA does distribute
these functions across a wider array of tools, such as process, service, and
semantic integration.

It's important to note that as CIOs grapple with the cost to support EAI and
EII simultaneously, they also need to consider that the cost of integration
initiatives will likely double when implementing an SOA strategy. IT
organizations will be asked to rethink how to build, deploy, and manage
software. Additionally, SOA will require IT shops to respond more like utilities
than systems integrators, and demand a more resilient and secure network and
software infrastructure.
Systems integration is a challenging but necessary part of business. And
while an SOA represents a significant step forward in managing a flexible
enterprise architecture, EAI and EII remain critical tools for enterprises to
better serve operational applications.
Sidebar: Choosing The Right Set Of Tools
Below is a list of questions designed to help companies decide between
enterprise application integration and enterprise information integration when
constructing a comprehensive systems-integration strategy.
- Do you plan to integrate existing software assets into new business
processes? If the answer is yes, then you're most likely dealing with a
process integration, and therefore should be looking at EAI tools.
- What are the motives for integration? In many cases, EII helps to
increase front- and midoffice worker productivity, which leads to increased
operational efficiencies and customer satisfaction. EAI tools, on the other
hand, provide support for implementing new business initiatives, which often
lead to increased profitability.
- Is time-to-completion more important than cost? If the answer is yes,
then correct tool-selection is critical. Using an EAI tool to solve an EII
problem, or vice versa, will increase project time and the risk of failure.
If time-to-completion isn't an issue, then use what you have and save the
money that would be spent on buying and supporting another tool.
- Is your company planning a merger and acquisition in the next six
months? M&As usually result in systems consolidation, but in the interim
transition period, systems consolidation may be necessary to satisfy
customer needs. If one company's systems will dominate the transition
strategy, EII may be satisfactory until all the data can be migrated over.
Sidebar: Integration At Work
EAI and enterprise information integration (EII) technologies can best be
described as complementary. The first is best used for connecting existing
applications, while the latter is focused on the creation of new information
aggregated from the existing system. For the sake of comparison, it's possible
to think of EII as connecting information, while EAI connects applications. The
following implementation summaries illustrate practical applications of each.
EAI: Connect the Apps
A major global automaker wanted to improve supply-chain operations.
Specifically, the company needed to provide dealers with online vehicle ordering
and available inventory information that would be routed directly to its
existing mainframe systems, managing processing and delivery.
An application-information exchange solution was created internally using an
enterprise services bus (ESB) that connected an existing dealer order/inventory
Web-based system with the mainframe applications. The ESB's data translation
helped manage communications between previously unconnected systems and format
information in several languages used by global dealers. In addition, the ESB's
legacy gateway allowed access to the mainframe applications without migrating or
rewriting them.
Ultimately, the integration effort reduced lead times from customer order to
delivery, eliminated inaccurate inventory and order information, and cut
required stock by an estimated 50%. Savings were nearly $620 million.
EII: Connect the Info
A large European bank regularly developed and sold to its clients financial
derivatives—a class of financial instruments akin to stocks and bonds. But the
bank's ability to bring new products to market was hampered by the constant
programming required for the exchange and processing of transactions generated
from 18 distinct trading systems. The point-to-point programmatic approach
proved to be prohibitively time consuming and expensive.
As a solution, the bank's IT department, working with the vendor's
professional-services group, created uniform XML-based interfaces for all
trading systems as well as risk-management, data-analysis, and reporting
systems. Also, the team created a graphical application that allowed business
users to model the data structures of new derivative products and map existing
systems to these models. As a benefit, the new application has reusable
components and a product catalog, allowing derivatives to be reassembled with
the necessary process flows for the financial product being modeled. Users can
link the defined data structures to rules, functions, and formulas, as well as
classify incoming XML documents. Ultimately, business users can generate new
financial products without IT programming support.
The new EII solution let the bank shorten the time required to integrate new
products from an average of six months to two weeks. Cost savings were estimated
to be $8.6 million. Since all inbound transactions are stored in XML format and
dedicated for audit purposes, other benefits include improved risk analysis and
better compliance controls. Plus, the IT staff expects the open, standards-based
architecture to benefit future projects.
Additional Information:
JP Morgenthal is managing partner for Avorcor, an IT consultancy, and is also
author of Enterprise Information Integration: A Pragmatic Approach (LuLu Press,
2005).
Related Articles:
Building an SOA Pipeline, Optimize, August 2005
Putting Application Integration to Work, Optimize, November 2004
Sidebar author Michael Kuhbock is co-chairman and founder of the Integration
Consortium, a nonprofit organization helping to establish integration-industry
standards, guidelines, and best practices.

The
Challenges of Data Management
By Robert Lerner
Current Analysis
Poor data quality costs U.S. companies billions of dollars each
year. In a frequently-quoted study published by The Data Warehousing
Institute in 2002, the total value of this cost is over $600 billion.
This is a staggering amount of money, and it is likely greater today
because of the increasing amount of business transacted in the U.S.
since 2002 and because of the exponential growth in the amount of data
produced every year (computers are running non-stop every day churning
out terabytes of new data).
However, if taken at face value, the dollar value doesn't convey the
sorts of data problems that companies face each day, and it doesn't
provide a real sense of how such data problems can impair a company's
ability to function at peak levels. To change this situation and limit
the loss due to poor data quality, companies need to be cognizant of the
importance of their data and of the problems that can impact the quality
of their data. They should also be aware that there are tools and
strategies available that can clean up their data and help them
keep
their data clean and accurate in perpetuity.
In its most basic sense, high-quality data is essential to a
company's ability to understand its customers. Customer data that is
riddled with errors (e.g., incorrect addresses or other personal
information, misspelled customer names, etc.) or is inconsistent (data
lacking a single, standardized format), redundant (multiple records for
the same customer), or outdated will undermine a company's ability to
understand its customers. After all, how can a company understand a
customer if it doesn't know where the customer lives or how to spell the
customer's name? If a company cannot understand its customers, then it
will have problems serving its customers according to the customer's
needs, preferences, goals, and the like.
Equally important, companies will have limited success up-selling and
cross-selling to customers without having accurate and up-to-date
customer information at their fingertips. They will have difficulties
distinguishing high-value customers and segmenting customers for
promotions and campaigns. Moreover, the absence of good quality data
will increase the costs of obtaining and retaining customers. If a
company has two records for a single customer, the costs of sending a
promotion to that customer will double, while the duplicated mailing
itself could irritate the customer and cost the company customer loyalty
and goodwill.
However, customer data is only one part of this overall problem.
Business data, sometimes called non-name-and-address data, is just as
crucial to a company's health and success. Business data can
be anything from an email address to a part number to a genome sequence.
If a company doesn't have a correct email address for a customer, it may
have trouble contacting the customer or directing a promotion to the
customer if email is the customer's preferred method of contact.
Or consider the case in which a part number has two digits that were
accidentally transposed. In a manufacturing setting, the
transposition could delay the arrival of the correct part to the
assembly line, which in turn could delay the assembly process. The
transposition could also impact the actual value of the company's
inventories and, depending on the cost of the correct and incorrect
parts, create variances in the company's books. And an incorrect
genome sequence could negatively impact scientific research, drug
discovery, or patient trials.
But these are only the most obvious problems that poor quality data can
cause. Poor quality data can also impact industry applications (CRM, ERP,
SCM, etc.) and data warehouses. And it can complicate a company's ability
to comply with government regulations.
The efficacy of any industry application is dependent on good quality
data. If a CRM application is fed incorrect customer data, its ability to
manage customer interactions could be limited, while the costs of retaining
the customer and maintaining the application could be increased. Inaccurate
data (e.g., an incorrect or missing credit limit, erroneous contact
information, incorrect household information, missing information in
general, etc.) may lead the application to present a false picture of the
customer and consequently impact the company's ability to interact with the
customer. CRM applications, like almost any other application, have
difficulty distinguishing between good quality and poor quality data, and
hence they treat all data more or less the same, regardless of quality. In
fact, more than a few industry applications have failed outright because
they were populated with poor quality data.
The same holds true with data warehouses, data marts, data repositories,
and so forth. Each is dependent on the quality of the data that populates
it. If poor or inaccurate data populates a data warehouse, then poor or
inaccurate information is given back. There is an acronym that has been in
circulation for decades that sums up this very state of affairs - GIGO, as
in "Garbage In, Garbage Out."
Interestingly, many companies have failed to understand one of the
central problems of data: Data decays. Data can change without even
touching it. Even, if a company populates a data warehouse containing
consistent, accurate, and reliable data, this data will begin to change, or
decay, almost immediately. The reason? Customers change: They change
their addresses, phone numbers, and other personal information. They also
marry, have children, divorce, and die. Companies change, too. On any given
day, companies start up, shut down, change names or addresses, and buy other
companies. Data is also frequently re-purposed, which can turn good quality
data into questionable data at reuse. All of these changes can negatively
impact data warehouses, industry applications, and so forth.
Finally, the ability to comply with any number of state, federal, and
international government regulations is closely linked to the quality of a
company's data. In recent years, and especially since 9/11, governments
have enacted regulations that essentially require a company to know who its
customers are. Regulations such as OFAC, the USA Patriot Act, HIPAA,
Graham-Leach-Bliley, state and federal Do Not Call legislation, and so forth
require accurate information on customers and transactions, which in turn
requires a company to have good quality customer data.
HIPAA (Healthcare Insurance Portability Accountability Act), for example,
requires hospitals, physicians, and managed care companies to enact patient
information, privacy, and security standards. It also allows patients to
access their medical records, to make corrections to the information
contained within them, and to monitor how this information is used or
disseminated. Unless hospitals and other healthcare companies have accurate
or good quality patient data, they cannot protect the privacy of a patient's
medical information or provide the patient complete access to his or her
records. As a result they open themselves up to a variety of liabilities.
The list doesn't end here. There are also data problems that arise
because of mergers and acquisitions, IT upgrades, international growth and
expansion, etc. So what can companies do to prevent problems in their data
from impacting their overall efficiency and competitiveness?
- The first step
is to realize that data is their most important strategic asset.
- The second
step is to consider strategies that will protect and maintain this valuable
asset.
One such strategy that companies can adopt is to implement a data
management framework. Data management is a combination of
technology and
processes that work together to ensure that a company's data is accurate,
consistent, and timely. But data management is also about keeping data
accurate, consistent, and timely in perpetuity. The following articles in
this series will detail an effective data management strategy, one which
combines a number of data management technologies (data profiling,
data
quality, data integration, data enrichment, and data monitoring) with
an
effective methodology (Analyze, Improve, and Control) to build and retain
useful data sources. With this combination of technologies and process
methodologies, companies can ensure that data quality is an ongoing
corporate priority - and an important competitive advantage - throughout a
company.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at Current
Analysis. Robert is responsible for covering the competitive landscape
for the Data Quality, Enterprise Portals, and Content Management markets,
where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He
can be reached at
rlerner@currentanalysis.com.
Data Profiling: The Blueprint for
Effective Data Management
By Robert Lerner
Let’s suppose that we
want to travel from Washington, DC, to La Jolla,
California to meet an old acquaintance. We
decide to save some money and, instead of
flying, we rent a car and begin driving. Of
course, there are some time and costs involved
in this venture, so we stuff our pockets with
$20 (for tolls and miscellaneous expenses that
might crop up) and take off.
Although we know our destination—and the
approximate time our friend will be waiting for
us—we don’t bother consulting a map. Why should
we? Everyone knows that La Jolla is in
California, and all we need to do is point the
car in the appropriate direction and everything
will come out right. We will meet our friend and
save money at the same time.
Certainly, this is a ludicrous situation, and
it is bound to fail or at least exceed our
budget, especially if we turn down one dead end
after another trying to wend our way to La
Jolla. This is not to say that we won’t make it
to La Jolla, only that there are quicker,
cheaper, and more effective ways of traveling
there.
Indeed, no sane traveler would embark on such
a trip without a map, and yet data-driven
projects of all kinds begin this very way.
Organizations will decide on, say, a CRM
application, and they will then go about
implementing it without first consulting a
roadmap of their data.
It is therefore not surprising that over half
of all CRM implementations either fail or fail
to live up to expectations, because many
organizations attempt to implement applications
without such a roadmap. To put it another way:
Too many companies lack a complete and necessary
understanding of their data. Without such an
understanding, or data roadmap, organizations
will spend more time, energy, and money than
they should simply to achieve limited results
from the application. As any IT manager knows,
no enterprise application will ever deliver on
its promises if the data populating it is of
questionable quality.
To ensure the best results from any
data-driven project, an organization should
begin by making a thorough inspection of its
data, noting all the problems or potential
problems and assessing the time and effort
needed to rectify these problems. While this can
be done manually, a manual review process tends
to be long, intensive, and costly. Furthermore,
manual review is not only susceptible to human
error, but it is also completely impractical for
large organizations that have thousands, if not
millions, of customer and product records. It is
unnecessary as well, because of the data
profiling technology that is now available.
A data profiling tool is designed to provide
an organization with a thorough understanding
(or roadmap) of its data. It can inspect the
content and structure of the data and provide
detailed information on its accuracy and
completeness. It can also uncover areas in the
data that are ambiguous and redundant.
Ultimately, a data profiling tool provides
information on whether the data is fit for the
purpose for which it was—and is—intended.
However, all data profiling tools aren’t equal. There are a number of
other features that a data profiling tool should have in order to increase
an organization’s understanding of its data and to enhance its ability to
correct and protect the data.
For instance, a data profiling tool should be able to provide detailed
information about an organization’s metadata. Metadata offers
critical information about the data it describes, including data type,
length of field, and uniqueness of field. It also describes
the data that can be present in a field and informs the organization
as to whether or not a field can be null (or empty). Ultimately,
metadata analysis will either validate or invalidate assumptions
about the data, thus helping the organization to understand whether its
data is fit for the intended purpose.
But a data profiling tool should also be able to perform
pattern analysis, statistical analysis, and frequency counts,
in addition to providing a variety of information about the relationships
between data.
Pattern analysis helps to determine whether the values in a
particular field are in the proper format. For example, using pattern
analysis, an organization can determine if a particular field is supposed to
be strictly numeric or if it can also contain letters. It reveals the length
of the field and provides other pertinent information regarding the field.
If, say, a telephone number field is supposed to formatted 000 000-999,
pattern analysis will uncover fields that don’t conform to this rule, fields
that may have numbers such as 9999 999-9999, 999-9999, 99999999999, or AAA
9999 (each A representing some letter).
Statistical analysis provides some valuable insights on a
data field. Statistics such as minimum and maximum values, as well as mean,
median, mode, standard deviation, etc., can provide useful information about
the essential characteristics and validity of the data—both in-house data
and data arriving from external sources. For example, a data source with
information outside of an expected range could indicate a problem or a
contamination. In a broader sense, statistical analysis might tell an
organization that, say, 80% of its total customer records have account
numbers or that 15% of its total customer records are missing social
security numbers (perhaps 5% have invalid social security numbers).
Frequency counts, which center on recurring data, provide
information on data values and help locate the sources of errors or
inconsistencies. For instance, a bedding manufacturing company can check on
the frequency of mattresses to box springs produced, using the counts to
determine whether there are problems in accounting for certain finished
products or whether part numbers are being entered correctly. Frequency
counts might also be used to check the validity of employee salary ranges or
the validity of the business rules that govern those ranges. Such counts
could determine the range of salaries, highlighting the salaries (called
outliers) that fall outside of those ranges (e.g., annual salaries that are
less than $1.00 and more than $100,000,000.00).
Finally, a data profiling tool should help uncover relationships
between data. Organizations typically have vast amounts of data,
everything from customer data to product data and financial
and compliance data. They also have third-party data, and
therefore they need to understand the relationships or connections
between data across applications and systems. A data
profiling tool can find such connections, such as primary or
foreign key relationships, inferred relationships, orphaned
data, and duplicate records. Locating duplicated records, for
example, can be crucial, since duplicated records can increase the costs
of customer acquisition and retention while obscuring the total value of a
particular customer.
Undertaking any data-driven project without a thorough
understanding of the data used to populate the project can lead to a
wide array of problems (project delays, cost overruns,
limited returns from the project, etc.). It can even lead to the
failure of the project. However, using the results from a data
profiling tool, an organization can clean up its data and
populate the project with high-quality data, giving the project its
best chance to fulfill its promise.
In fact, the results from a solid data profiling tool will guide and
speed the processes of data repair, which can save significant costs
in terms of time and effort compared to a comprehensive but less focused
approach. Such a data profiling tool can also help an organization
determine the difficulty of integrating disparate data sets from
different systems, a problem compounded by the need to preserve the
integrity of all the data. And it can even be used to develop
solutions to the problems that created the questionable data (e.g., new
procedures, new data sources, etc.).
However, a data profiling tool is not a one-off piece of technology
that should be discarded after the initial use. While it is the crucial
first step in any data-driven project, it can also be used—and should be
used—throughout the project. A data profiling tool can help test the
results at various intervals, locating any data problems that may have
occurred as a result of the integration efforts. And the tool can be used as
part of an ongoing process to manage the organization’s data. Because data
is not static (data can become stale, new data can be added, etc.), a
data profiling tool offers a way of understanding data on a continual basis,
which is crucial to maintaining accurate data throughout the organization.
As noted in the introductory article, improving data quality is a
process of analyzing, improving, and controlling an
organization’s data. While a data profiling tool encompasses the first
step, it also encompasses the processes of improving and controlling the
quality of data. To improve data, a data profiling tool directs data
repair efforts; and, by rerunning the data profiling process again,
it enables the organization to improve its data, even after any initial
efforts have been made to cleanse it. Ultimately, a data profiling tool
allows an organization to control the quality of its data, and using the
tool on a continual basis will enable an organization to take proactive
steps to correct any data issues and ensure that its data is perpetually of
the highest quality.
The next article details the data repair efforts that can be made after
the data profiling tool has uncovered data problems.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He
can be reached at
rlerner@currentanalysis.com.
Enhancing the Value of Data Through
Integration and Enrichment
By Robert Lerner
To be successful,
businesses require accurate, consistent, and
timely information to make sound,
productive
decisions. Regardless of whether the data
concerns customers, products, suppliers,
employees, or whatever, information must be
readily available to every person in the
organization who needs it, even if they are
located in different departments, divisions,
subsidiaries, or even geographical regions.
Unfortunately, not every organization has
easy access to information. In fact, even
organizations with relatively accurate data can
have data silos – data (in applications,
departments, etc.) that is not shared with the
rest of the organization.
Consider the case in which an organization’s
call center application does not share data
with
its CRM application, perhaps because the
technologies are from different vendors (and the
data has different formats) or because the
applications reside in different business units.
Since the applications don’t share data, any new
data (about customer interactions, updated
customer information, new customers, etc.)
arriving through the call center is unlikely to
be available to the CRM application, and vice
versa. Thus the overall value of the
applications to the organization is diminished,
since each application needs to have complete,
accurate, and timely information about the
customer – not bits and pieces – to fulfill its
promise. As a result, the organization’s ability
to understand and support its customers will
suffer, while meaningful reporting and analysis
across the applications will be difficult at
best.
Multiply this situation across the
organization and it is easy to see how silos of
information can hurt an organization’s ability
not only to know its customers but also to have
real insight into its business.
However, there is a solution to this problem
-- data integration. In order to get the most
from its data – and ensure that an organization
has the best foundation on which to make
business decisions – an organization must
integrate its data. In fact, data integration
is
the critical next-step in the data management
process, following the process of data cleansing
and standardization (if poor quality data is
integrated into any application, database, or
whatever, the value and effectiveness of that
application will be undermined).
Of course, linking, matching, and
standardization can be part of the data
integration process, but they are not the entire
process. In most instances, an organization will
require a data integration tool to integrate
data throughout the organization or into a data
warehouse, application, or a repository such as
a customer data master file.
Essentially, the data integration process of
data management entails
- pulling data from its
sources,
- integrating it (consolidating records,
eliminating duplicates, etc.),
- and then either
pushing it back to the source systems or
delivering it to some other target system.
Once
completed, the entire organization can then
operate on essentially the same data.
This is not a new concept, however, and there
a number of commercial tools currently available
that can support the needs of data integration
to some degree. Unfortunately, none of these
tools, by themselves, supports all of the data
integration needs for a data management
solution. Among the best-known of these tools
are ETL (extract, transform, load), EAI
(enterprise application integration), and EII
(enterprise information integration).
ETL tools are designed to extract data from a
specified source, transform the data, and then load it into a
specified target, usually an application or data warehouse. ETL tools
are perhaps the most effective of these particular tools for data
integration, but they usually have limited data quality capabilities
and they generally work in only batch mode.
EAI tools, on the other hand, are designed to bring data
or business processes from a particular application to another particular
application. Like ETL tools, they rarely (if ever) offer data quality
capabilities and, moreover, they tend to be most effective for
application linking.
Finally, EII systems are designed to integrate small
amounts of data, usually in real time, on a limited basis for query
and analysis. Not surprisingly, EII tools lack data quality
capabilities and, because they lack a database, they can
integrate data only on a temporary basis.
Of course, these are not the only tools or solutions for data
integration. CDI (customer data integration) and PDM (product data
management) technologies are also gaining currency as data-integration
solutions. These solutions combine data integration tools with a
central
repository into which the organization’s clean data is loaded (including
cleansed third-party data). For CDI and PDM, this repository functions as
the so-called “single source of truth” for the organization, sharing correct
and up-to-date views of the data to all the appropriate applications,
databases and business units. While these tend to be immature solutions –
and few of them currently offer strong data quality capabilities – they
nevertheless hold real promise.
Indeed, most of the tools outlined above offer some value for data
integration (and to some extent they are complementary). But for most data
integration requirements, an organization should consider a solution or tool
that comes integrated with a strong set of data quality capabilities. The
solution should also be able to access all of the organization’s data,
regardless of source through connectors to popular enterprise applications
(the connectors will also help populate the applications with high quality
data). The solution should also provide direct connectivity with mainframes
and major relational databases. (One possibility is a technology that
provides data transformation and data aggregation libraries that allow the
organization to create complex data-cleansing workflows within the data
movement process.)
And because data integration is not a one-time event but a continuous
process (organizations are constantly collecting/creating new data), the
solution should provide change-management capabilities. Change management
reduces overhead and processing time by limiting the integration process to
changes in the data; and because of this, it shortens the time in which all
parts of the organization can gain access to any changed or new data. In
fact, the ability to integrate data not only in batch but also real-time can
be critical, since correct, complete data needs to be available throughout
the organization when the organization needs it. The value of high quality
data is greatest when it supports the specific needs of the organization,
and if those needs are now and not tomorrow (in case of a batch run), then
good data should be available at that moment.
Finally, two additional points about data integration are important to
build consistent, accurate and reliable data sets. First, the organization’s
legacy data should not be neglected during the integration process; contrary
to popular belief, legacy data is not data without value. Second,
integrating metadata is critical. The organization’s metadata, or data about
data, should be consistent throughout the organization. Metadata provides a
variety of important information, such as where the data came from, the
ownership of the data, when and if the data has been updated, etc. It also
provides a common understanding of the data’s format and meaning. If the
metadata is not consistent, or if it’s simply wrong, the organization will
have trouble accessing and understanding all of its data.
With the data quality process implemented, and all of its data
integrated, the organization is now in a position to understand itself, its
customers, its products, and its supplier network. At this point, companies
are also in a position to make informed decisions based on the quality and
value of its data. Nevertheless, there is an additional step in the data
management process that is designed to enhance the overall value of the
organization’s data – enrichment.
In a sense, data enrichment is the “icing on the cake” for providing a
complete view of the customer (or product). In short, data enrichment is a
process of adding additional information to the data records to potentially
fill in any missing gaps in the records, such as providing missing
addresses, social security numbers, email addresses, etc. This information
can be obtained from the organization’s own data, or, more likely, from
third-party sources. For example, the USPS can provide zip code and related
information to fill in those blanks.
But the enrichment process can also supply a wide range of information
that can expand a customer’s profile or provide a better identification of
the customer. Information such as geocodes, tax assessment information,
demographic information, watch list compliance, and other data is usually
available from third-party suppliers. Geocodes, for example, are valuable
because they pinpoint the customer’s physical location, which can help an
organization develop demographic information and logistics planning.
Third-party suppliers can also provide a wide variety of lifestyle
information, credit information, etc., allowing organizations to segment
customers for targeted marketing campaigns. Product data can be enriched
with industry-standard product information, data from suppliers, and other
details, all of which make the process of buying and selling easier and more
effective.
Having integrated and enriched its data, the organization has a complete
view of itself, its customers, its products, and other business-critical
functions. And every business unit, application or data warehouse has
access
to the same accurate, consistent, and timely data that every other part of
the organization does. The addition of new data should not be a problem for
the organization (or create new silos of data), because the data integration
capabilities ensure that any changes are integrated throughout the
organization in a timely fashion.
The benefit of data integration is obvious; companies have a reliable set
of information as the foundation for timely, accurate business decisions.
However, in order to ensure that the organization’s data remains in this
state, the data must be monitored, which is the subject of the next article
in this series.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He
can be reached at
rlerner@currentanalysis.com.
Keeping on Top of Data
By Robert Lerner
Suppose that we have
finally eliminated most, if not all, of our
organization’s data problems. We began the
process of eliminating our data problems by
profiling our data, after which we cleansed it,
integrated it, and finally enriched it. Now,
imagine we completed this task at 5:00 on Friday
afternoon. With nothing else to do, we turn out
the lights, lock the doors, and prepare to enjoy
our weekend, confident that no one will touch
the data until Monday morning.
On Monday morning, we are the first ones in
the office. Rested, we go about our work as we
normally do, but we quickly discover that some
of our applications are not delivering the
results that we had anticipated. This is
surprising, since there is no particular reason
why the data – and by extension, the
organization – shouldn’t be operating optimally.
Soon, we discover the cause of our problems –
our once pristine data now has errors in it.
Without even touching it, the data has declined
in both quality and usefulness, and it is now
negatively impacting our organization.
Of course, this is an absurd tale, but it
does highlight one of the central truths about
data – data, even if it's left by itself,
changes. The validity of data is always
temporary, and changing data is as inevitable as
the sun rising on Monday morning. Data changes,
or decays, because people and things change.
Over the course of this hypothetical weekend,
any number of customers have changed some aspect
of their personal information (e.g., addresses,
phone numbers, etc.); some have changed some
aspect of their household (married, divorced,
added children), and others may have died or
simply severed their relationship with the
organization. Left unchecked, the data quality
reaches levels similar to the one that led to
its implementation of a data management solution
in the first place.
Consider the following statistics compiled by
Dun & Bradstreet:
On a typical morning between 9:00 and 11:00:
- 706 businesses will move
- 578 businesses will change their phone
numbers
- 60 businesses will change their names
- 40 businesses will shut down
- 10 businesses will file bankruptcy
- 1 business will change ownership
Without any intervention, and without the
fault of any individual, the quality of an
organization's data will decline almost the
instant that it has been cleansed, integrated
and enriched. But the problems impacting the
quality of an organization's data are not just
problems that originate outside of the
organization. Consider the host of data problems
that could crop up throughout the rest of the
week, such as input errors, the integration of
incompatible third-party data, and a repurposing
of some existing data. By Friday, our data is
rife with problems, and its usefulness is now
being questioned.
Certainly, there is some exaggeration here, but not much. An
organization can take all the actions necessary to rectify its data
problems, but sooner or later (generally sooner) the data will change or
decay, leaving the organization where it started in terms of data quality.
Among the causes of this situation is not the volatility of data but a
fundamental lack of understanding about the nature of data – and what it
takes to achieve and keep the highest quality data possible.
Indeed, organizations often assume that once their data quality problems
are resolved, the data will remain clean in perpetuity. On the contrary,
because of the volatility of data, the data management process outlined in
the previous articles is really only the first step in ensuring that the
organization’s data is continually of the highest quality.
Data management is not a one-time process. An effective data management
strategy should go beyond analyzing and improving the data to a phase of
controlling the process. Without this final step, much of the efforts that
have gone before could eventually prove pointless. This step, however, can
be complicated, if one considers the internal process that may need to be
changed in order to create an environment conducive to protecting the
quality of the organization's data. Nevertheless, no data management
solution is complete unless it helps the organization control its data on an
ongoing basis. One method of providing such a control is to implement a data
monitoring solution.
As the term suggests, data monitoring is designed to watch over the
organization’s data. At its highest level, a data monitoring tool should
monitor the organization’s data on a periodic basis to determine whether the
quality of the data falls within acceptable limits. If the quality data
falls below these limits, the tool should alert responsible parties in the
organization of this situation. The tool should also determine whether data
conforms to predefined business rules the organization has established.
For example, the organization may have a rule that part numbers can
contain both letters and numbers, but only in a predefined order and case
(e.g., the first three and the seventh and eight digits are letters). If
part numbers that don't conform to this rule enter a data source, then the
data monitoring tool should alert the organization – frequently a data
steward or business analyst – that something is wrong with new part-number
data.
Furthermore, a data monitoring tool should be able to support both batch
loads and transactional data. This is critical, since organizations must
control all data no matter how or when the data enters the organization. For
batch loads, such a tool should be able to provide trending information.
Essentially, trending is a process that compares the characteristics of a
data load with prior data loads. For example, if the organization is loading
a batch of data into a data warehouse, the tool should compare the
characteristics of this load with prior loads. The differences, if any,
could point out problems in the data feed. Suppose prior batch loads showed
a roughly 50/50 split between the number of, say, mattresses produced to box
springs, but the current load shows a 30/70 split. The data monitoring tool
can flag this as a possible problem, enabling the organization to reject the
load if this proportion is found to be incorrect.
Finally, on a transactional level, the data monitoring tool should enable
the organization to establish a range of parameters that it can monitor and
then alert the appropriate individual or individuals if these parameters are
violated. Suppose the organization decides that for customer records, a ZIP
code must be a ZIP+4 number. When customer record is entered with only a
five-digit ZIP code, the data monitoring tool should flag that record, send
out an alert, and remove the record to an outlier file – or abort the
transaction altogether. The difference here, compared to the previous
example, is that the tool is looking at the individual record, as opposed to
multiple records in a batch run.
Ultimately, a data monitoring tool provides another way for an
organization to take control of its data – and to ensure that it is always
of the highest quality. In essence, data monitoring enables an organization
to take proactive measures to protect its data before data problems become
serious problems and threaten the overall quality of its data. To reap the
rewards of high quality data, organizations must take steps to protect data
both now and in the future.
However, data monitoring goes beyond merely protecting data. With the
information provided by a strong data monitoring tool, an organization can
also glean some information about its business processes that can be
leveraged to improve these processes. Finding and rectifying a source of
data errors is one more step in the process of taking control of data.
Data monitoring is to some extent the culmination – and also the
beginning – of the data management process, at least as far as technology is
concerned. The following article will provide a data-management scorecard
that may be useful when an organization is looking to purchase a data
management solution.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He
can be reached at
rlerner@currentanalysis.com.
How to Choose a Data Management
Solution
By Robert Lerner
Current Analysis
In the previous articles of this series, we discussed
data management technology. With these articles in mind, we can now consider how
to buy a data management solution, or what to look for when considering a data
management solution.
The following is a discussion about some of the features and functions that an
organization should consider when making a buying decision. However, we are
assuming that the organization has already come to some understanding regarding
the depth of its data problems and ultimately its goal in implementing a data
management solution. We’re also assuming that medium- to large-sized
organizations would most likely undertake this strategy, since small
organizations may lack the resources to accomplish these goals effectively.
Ultimately, when choosing a data management solution, an organization should
consider a range of issues that can lead to more useful, actionable data. These
issues include data support, technology, international capabilities,
methodology, architecture, platform, implementation, usability, delivery, vendor
selection, and finally cost.
Data Support
Traditionally, data quality and data integration strategies have focused on
customer data. As a result, many solutions often provide only cursory data
quality abilities outside of the realm of customer contact information.
Organizations should consider a data management solution that can address all
data, not just names and addresses. Most organizations have a range of data
besides names and addresses (products, inventory, suppliers, finance, etc.), and
this data needs the same support that name-and-address data does. Organizations
should therefore consider a solution that can handle any data, whether this data
is product codes or statistical data, commodity codes (e.g., UNSPSC and eCl@ss)
or gene sequences, or even proprietary data.
Technology
There are two essential aspects of technology that organizations should consider
in a data management solution: tools and the integration of these tools. The
solution should provide a range of tools not only to discover and rectify data
problems, but to protect the data on an ongoing basis.
- Data Profiling: Data profiling is designed to provide an
organization with a thorough understanding of the state or quality of its
data. Among other things, the tool should be able to perform pattern
analysis, statistical analysis, and frequency counts, as well as provide a
variety of information regarding relationships between data. It should also
be able to provide a broad range of information about an organization’s
metadata.
- Data Quality: Data quality tools are designed to automate the
process of correcting data errors and creating meaningful data from
disconnected information. These tools or capabilities should be tightly
integrated and offer such capabilities as parsing (including the parsing of
free-form text), cleansing, standardization, matching and linking,
consolidation, and householding.
- Data Integration: Data integration entails pulling data from its
sources, integrating it (consolidating records, eliminating duplicates, and
so forth), and then either pushing it back to the source systems or
delivering it to some other target system. The ultimate goal is to enable
the entire organization to operate on the same high-quality data. There are
a number of effective methods of providing integration (e.g., ETL), but it
is important that the solution should be able to handle legacy data and
metadata (metadata should be consistent throughout the organization).
- Data Enrichment: Data enrichment is a process of adding
additional information to the data records in order to fill in any missing
gaps in the records, such as missing addresses, social security numbers,
email addresses, and so forth. This information can be obtained from the
organization’s own data or from third-party sources (e.g., the USPS).
Indeed, the solution should support a variety of data sources or
information, such as geocodes, tax assessment information, demographic
information, and a range of other information.
- Data Monitoring: Data monitoring is designed to watch over, or
monitor, the organization’s data. A data monitoring tool should be able to
monitor an organization’s data on a predetermined timeframe to determine if
the data falls within acceptable limits, or to determine if the data
conforms to the organization’s business rules. The tools should also be able
to alert the appropriate individuals or individuals whenever any of these
parameters have been violated. Finally, a solution should be able to monitor
both batch loads and transactional data to help eliminate data problems
before they escalate.
A tightly integrated suite of tools will decrease the amount of time that the
user spends during the data management processes (the user won’t have to exit
one tool and enter another during the process). At the same time, a single
solution approach will enhance the overall effectiveness of the entire process.
For example, business rules discovered by the data profiling tool will
automatically be accessible by all of the other tools of the suite.
However, a single solution approach implies that the solution should be from
a single vendor. Indeed, while tools from different vendors can be effective for
limited data management needs (e.g., matching suspect lists), they could
ultimately become problematic when the user tries to get them to work together –
especially if the tools are proprietary in nature or support disparate standards
(e.g., .NET as opposed to J2EE).
International Capabilities
Organizations should choose a solution that offers strong international data
management capabilities. Strong capabilities should not be tied directly to the
number of countries that a solution or vendor can “support.” In fact, this
support amounts to little more than some high-level postal coding in many
developing countries.
Instead, organizations should look at the depth of international capabilities
that the vendor supports. For example, does the vendor really understand the
culture of the foreign country? Is there an understanding of names, name order,
name and address format (in both postal and cultural terms), gender and modes of
salutation? Does the solution understand regional dialects or geocoding (can it
pinpoint a particular house in a particular in a particular area)? Foreign
character sets are also a plus, if the organization needs these character sets
to do business. At best, most vendors support a handful of countries extremely
well, and another handful reasonably well; for the rest of the world, they
provide only limited support.
Methodology
When evaluating data management solutions, pay close attention to the
methodology that the vendor uses to guide the analysis, correction and
monitoring of data. An effective methodology is critical, since it will help
make sense of the data management process (what to do… when… and why do it at
all?). An effective methodology can also enhance the process of discovering data
quality issues, correcting these issues, and keeping the data at the highest
quality possible.
The articles in this series have suggested one particular methodology:
- Analyze the data creation process and the current state of the data
- Improve the process and the underlying data
- Control the process and the resulting improvements in data quality
There are some other methodologies that could have been used to achieve
similar results, if only because they have the same goal. However, not to all
methodologies are equal or equally effective, but an effective data management
methodology should be part and parcel of any data management solution.
Architecture and Platform Support
There are number of ways of architecting a data management solution, but one of
the most effective is to leverage an SOA, or service-oriented architecture. An
SOA will provide the greatest amount of flexibility in implementing a data
management solution and in leveraging the solution for virtually any data
management requirement. Indeed, an SOA enables a data management suite to be
used in its entirety or as a set of reusable services that can be leveraged for
ad hoc purposes or integrated into other applications. These services can
include everything from a parsing routine, to a complex workflow, to data
integration logic can be a service.
An SOA also enhances the ability to integrate the data management solution
into the rest of the organization’s architecture, if it is also based on an SOA.
Moreover, for the maximum flexibility and to “future proof” the solution, the
SOA should be standards-based (supporting such standards as SOAP, XML, WSDL, and
the UDDI Web services registry) and support standards-based Web services. These
standards-based Web services are generally either Java or .NET, although some
vendors can support both (which is ideal for heterogeneous environments).
The solution should support a variety of platforms, both Windows and UNIX, as
well as Linux and mainframes. When examining solutions, look for a technology
strategy that supports all of the platforms used by the organization.
Implementation
The solution should provide a range of implementation capabilities, given the
range of potential needs that an organization may have. The solution should be
capable of being implemented as a standalone solution, as part of a broader
integrated solution, or in specific applications (i.e., it includes connectors
to enterprise applications such as CRM, ERP, etc.). Web services integration, as
noted above, should also be a consideration. For some organizations or
departments, an in-house implementation may not be desired. In this case, the
organization should consider a hosted solution, with the vendor or third-party
hosting the solution.
Delivery
An organization should consider a solution that supports batch updates of its
data as well as on demand and real-time data quality. The ability to support all
of these will provide an organization with high quality data whenever it
requires it -- tomorrow, in an hour, or right now. If an organization needs to
respond to any data-driven needs immediately and effectively, real-time data
quality, at the point of entry, adds another check of the organization’s data
quality, ensuring that only high quality data enters the organization.
Usability
To increase the usefulness of data quality rules and processes across the
enterprise, a solution should accommodate both the developer and the business
user. Supporting business users is significant, because the business user has a
more intimate knowledge of the organization’s data and its requirements than
most developers and IT personnel. After all, business users work with the data
on a day-in/day-out basis, and therefore they have a unique understanding of the
impact of high quality data to the organization -- an understanding that also
helps them gauge the impact of data problems on both their jobs and the
organization as a whole.
Moreover, because business users are in “closer” contact with the data than
IT personnel, they are also in a position to take any appropriate steps to
ensure the accuracy of the data and prevent its decay. For the business user,
look for icons and pull-down menus. For example, the business user should be
able to create multi-step workflows simply using a drag-and-drop interface.
Vendor Selection
Obviously, vendor selection should be a consideration. While there may be a
satisfactory solution available from a particular vendor, this solution can be a
financial and tactical nightmare if the vendor can’t support it effectively or
if goes out of business. Organizations should only consider vendors with a solid
history of success in the market. Vendors also must be financially stable and
have a high renewal rate or record of customer satisfaction.
Cost
Cost is always a consideration. Yet a decision based on the lowest cost could
end up being a costly decision itself. Organizations should first consider how
the solution will support its needs, both now and potentially in the future (for
example, does the solution support industry standards?).
Next, organizations should consider how well the solution supports its
culture. This is an interesting proposition, because implementing a data
management solution is essentially implementing a new mindset in the
organization with respect to data. While this article only considers technical
matters, effective data management requires different methods of handling data
and even thinking about data. Therefore, don’t judge on the initial price alone.
Take a “test drive” with a solution, run it through its paces with a segment of
your data, and see how it performs. Try before you buy, and compare the results
to other solutions that you have tested.
There will likely be other issues that arise during a buying decision, but it
is hoped that this scorecard will serve as a general outline to aid the
organization in the choice of both a solution and a provider.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He can
be reached at
rlerner@currentanalysis.com.
Emerging Issues: Master Data
Management and Data Quality
By Robert Lerner
Current Analysis
Master data management (MDM) is getting a lot of attention these days as
people begin to understand just how fragmented and dispersed their data
sources are. Essentially, MDM combines technology and services to manage
master data, to build accurate, consistent, and timely information from
across the organization. The idea of managing master data isn’t new;
organizations have been struggling with master data management issues for
years. In fact, it was once thought that ERP and similar solutions would
offer the ability to provide such a view of an organization’s master data,
but of course this hasn’t happened.
Master data is best defined as mission-critical data, such as customer data,
product data, bill of materials and so forth. It is not metadata or
transactional data. Unlike transactional data, for instance, master data
helps to classify transactional data and it is controlled by changes to the
organization (e.g., the introduction of a new supplier or product line),
while transactional data is generated by such events as a sale.
Many organizations continue to have trouble leveraging their master data to
the fullest, because it is not consistent across the organization or because
it exists in data silos. In large organizations, it is not uncommon to find
multiple instances of ERP systems, and when the product data in one ERP
system is not shared with other ERP systems (or any system that should have
access to this data), it becomes difficult for the organization to
understand and track the value of this data. Individual business units also
have trouble accessing such data (if indeed they can), which could be
crucial to their success, while the organization itself doesn’t really know
what product data is correct—chances are that all of the same product data
in the various systems is not correct, since it probably lacks information
buried in one or many of the other systems.
But while these sorts of problems are not uncommon, the need to manage
master data effectively is gaining a sense of urgency for a number of other
reasons. The size and complexity of organizations are increasing, for
example, while at the same time large organizations are becoming more
global. All of this puts pressure on organizations to increase the number of
systems or applications needed to run both the organization and its
individual business units. Furthermore, mergers and acquisitions add to the
problems (how do you integrate master data from disparate organizations?),
as does regulatory compliance, which is forcing organizations to control
their master data more effectively for reporting. As a result, organizations
are experiencing difficulties understanding and properly valuing their
customers, suppliers, and even partners; and they are facing problems
controlling costs, executing effectively on business strategies, and
complying effectively and cost-efficiently with Sarbanes-Oxley, Basel II,
and other regulations.
MDM solutions, however, offer some real promise to these and other master
data problems. In a sense, an MDM solution is not unlike a CDI (Customer
Data Integration) solution, in that a CDI solution is designed to provide an
accurate, timely, consistent enterprise-wide view of customer data. Indeed,
CDI is a subset of MDM. Like a CDI solution, an MDM solution can leverage a
central master data hub that serves as the “single version of the truth” for
all of an organization’s master data. The hub manages the master data,
integrating new data or updates, while synchronizing all new and updated
data to an organization’s appropriate applications, systems, etc.
Actually, there are a number of methodologies and technologies (and services)
that can be used to provide an effective MDM solution. Without enumerating these
technologies and/or approaches, it is safe to say that every successful MDM
solution or effort is founded on high-quality data. Indeed, one of the central
purposes of MDM is to deliver a complete, accurate, consistent, and timely
picture of an organization’s master data, but this is impossible if the solution
delivers master data that is of a questionable quality. For example, delivering
duplicate or incomplete product data to every appropriate system in an
organization not only defeats the purpose of MDM, but it also opens up any
number of problems associated with integrating and relying on poor quality data
(inconsistent and incorrect part information, for instance, can negatively
impact an organization’s ability to find the right supplier for the right part).
Therefore, before beginning any MDM initiative, it is important to implement a
data quality initiative. However, it should be noted that MDM is not a
substitute for data quality. By itself, MDM is not designed to, and cannot,
improve the quality of an organization’s data. That is, MDM is not designed to
profile, cleanse, standardize, and enrich the organization’s master data. It can
do this, but only if one of the components of the solution is a data quality
solution. Regardless, beginning with data quality offers benefits to both the
MDM initiative and the organization itself, apart from MDM.
The data quality initiative should begin with profiling the underlying master
data. It is critical that, before attempting an MDM implementation,
organizations understand the quality of their master data—because without
understanding the quality, it will be impossible to gauge the effort, the costs,
and the time needed to make the data suitable for MDM. This information is
essential in order to avoid any number of problems, such as cost and time
overruns, rework and repair efforts, additional costs, and so forth.
Interestingly, one of the benefits of profiling the data at this juncture is
that the organization can leverage the information to make improvements in its
overall handling of data (e.g., locating the sources of poor quality data
entering the organization and correcting these sources).
Data profiling is also needed to direct the data quality cleanup effort. The
results from the data profiling effort will guide the cleanup effort, shortening
the time to clean, accurate, and timely data. One of the ancillary benefits of
leveraging a data quality initiative at this juncture is that the organization
can use profiling results (if all the organization’s data was profiled) to
correct all of its data, not just its master data. This is significant, because
all of its data is critical, master data as well as legacy data, and correcting
the data will enhance not only the MDM project but also all of the
organization’s other applications, systems, and so forth depend on high quality
data to deliver on their promises.
One of the keys to ensure the success of an MDM initiative is to address the
quality of the master data first. Indeed, an MDM initiative is not likely to
deliver on its promises if the data itself doesn’t deliver on expectations.
However, the benefits of data quality transcend MDM and extend to every other
part of the organization, from top to bottom, from application to business
units, and to customers and partners. By leveraging data quality to control all
of the its data, an organization will be in a better position to solve many of
the issues that MDM was designed for, including mergers and acquisitions,
regulatory compliance, and other issues that can hinder the internal processes
of an otherwise efficient, effective enterprise.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He can
be reached at
rlerner@currentanalysis.com.
Rare Business Assets: Tables and
Graphs that Communicate
By Stephen Few
Perceptual Edge
Faced with the perennial challenge to compete and succeed, who has time to
worry about the small things? Some things that seem small, perhaps even
microscopic, however, are actually much bigger than they seem. Now is in fact
the right time to “sweat the small stuff,” especially when it contributes to the
difference between success and failure.
Numbers in the Mist
As a 20-year veteran of business and technology consulting, I am often dismayed
by examples of wasted time and money that manage to remain just under the radar.
These days I’m fixated on one that is especially insidious (and costly) because
it is rarely recognized, even though it erodes the usefulness of the information
that is most critical to business success: the numbers that measure
performance. Business metrics lie at the heart of every important decision
you make. Your decisions are only as good as the numbers that inform them and
the communication that presents those numbers to you.
Quantitative information is almost always communicated in the form of
tables or graphs. Think about it. You depend on tables and graphs
every day but what you might not realize is that they’re almost always poorly
designed. Why? Probably less than 1% of those who prepare tables and graphs
have been trained to design them for effective and efficient communication. And
why is that? In part, because we see so few examples of well-designed tables and
graphs and therefore have no useful benchmarks to reveal, through contrast, the
deficiency of those we use every day. Most tables and graphs are difficult and
time-consuming to read, filled with unnecessary information and visual fluff,
and are far too often downright misleading. In 1997 Edward R. Tufte, the world’s
leading expert in the visual presentation of information, convincingly
demonstrated that the explosion of the space shuttle Challenger in 1986, which
resulted in the deaths of seven astronauts, was in part the result of
poorly-designed presentations to NASA officials about the potential risk of
O-ring failure (Edward R. Tufte, 1997, Visual Explanations: Images and
Quantities, Evidence and Narrative, Cheshire, Connecticut: Graphics Press).
If the risk of Oring failure in cold temperatures had been presented properly,
decision makers would have understood the extreme risks involved and postponed
the launch. An avoidable tragedy occurred because of an information display that
was misleading. Every day, just like the officials at NASA, you rely on good
data to inform your decisions. Lives may not be at stake, but livelihoods
certainly are.
The following example is typical of the graphs that I encounter in my work as
an information design consultant. Imagine that you need an overview of
sales performance at the start of each day, and this is what you’re given:
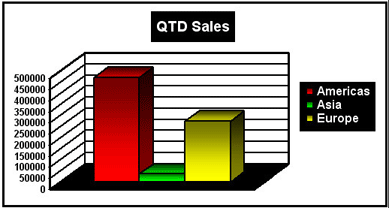
It’s colorful, it’s bold, it jumps off the page, but to what end? What is the
message? Take a minute to look at this graph carefully to determine what it’s
telling you.
. . . . . . . . . . . . . . .
What did you get? Probably something like the following:
- Sales for the Americas are better than sales for Europe,
which in turn are better than sales for Asia. This much is clear.
- Sales for Asia don’t amount to very much compared to the other
regions.
- Sales for the Americas are over 400,000 or thereabouts. Sales for
Europe are somewhere around 200,000. Sales for Asia appear to
be about 50,000 – perhaps a little less.
That’s not much information, and you certainly had to work for it, didn’t
you? Here are the actual values that were used to create this graph:
| Americas |
$469,384 |
| Asia |
$34,847 |
| Europe |
$273,854 |
You might not need to know the precise sales amounts, but I suspect you would
want better accuracy than you were able to discern from this graph, and you
would certainly want to get it faster and with much less effort. Also, several
pieces of critical information aren’t supplied by this graph, including:
- Given the fact that these sales are international, what is the unit of
measure? Is it U.S. dollars, Euros, etc.?
- Quarter-to-date sales as of what date? If you filed this report away for
future reference and pulled it out again a year from now, you wouldn’t know
what day, what quarter, or even what year it represents.
- How do these sales figures compare to your plan for the quarter?
- How do these sales figures compare to how you did at this time last
quarter or in this same quarter last year?
This graph lacks important contextual information and critical points of
comparison. As a report of quarter-to-date sales across your major geographical
regions, it doesn’t communicate very much. It uses a great deal of ink to say
very little, and the little it says it says poorly. The person who created this
graph failed to discern the information that you needed and to design its
presentation in a way that communicated clearly.
Given the intended message and the information that you would find useful as
an executive, the following display tells the story much better:
2003 Q1-to-Date Regional Sales
March 15, 2003 |
| |
Sales
(US $) |
Percent of
Total Sales |
Current
Percent of
Qtr Plan |
Qtr End
Projected
Sales
(US $) |
Qtr End
Projected
Percent of
Qtr Plan |
| |
|
| Americas |
469, 384 |
60% |
85% |
586,730 |
107% |
| Europe |
273,854 |
35% |
91% |
353,272 |
118% |
| Asia |
34,847 |
5% |
50% |
43,210 |
62% |
| |
|
| |
$778,085 |
100% |
85% |
$983,212 |
107% |
| Note: To date 83% of the quarter has elapsed. |
This is a simple table but it is easy to read and it contains a great deal
more information. No ink is wasted. There is no fluff. You could use this report
to make important decisions. It communicates the information that you need
clearly and efficiently.
Take a look at another example, this time of the increasingly common pie
chart. This graph’s purpose is to show how your company – Company G – is doing
compared to the competition:
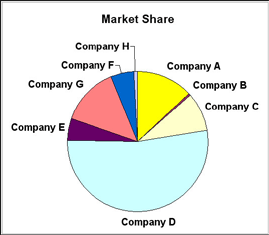
Here it is again, this time dressed up a little with the addition of a 3-D
effect:
Does the use of 3-D enhance the graph in a way that is useful? Does either of
these pie charts enable you to determine Company G’s market share compared to
the competition? Can you determine Company G’s rank compared to its competitors?
Which has the greater share: Company A or Company G? Because of fundamental
limitations in visual perception, you really can’t answer any of these questions
accurately.
Now look at the exact same market share data displayed differently:

Did you have any trouble interpreting this information? I doubt it. Did you
struggle to locate the most important information? Not this time. It’s obvious
that Our Company ranks second, slightly better than Company A, and that its
market share is precisely 13.46%. This display contains no distractions. It
gives the important numbers clear voices to tell their story. The creator of
this graph did a good job.
The Root of the Problem
How did we slip into such a sad state of quantitative miscommunication? The
answer is tied to that little machine that has reshaped the face of business:
the personal computer. Prior to the advent of the PC, tables and graphs of
quantitative information were generally produced through the use of a pencil,
straightedge, graph paper, calculator, and hours of tedious labor. Then, when
chart-producing software hit the scene, especially electronic spreadsheets, many
of us would have never before attempted to draw a graph suddenly became
Rembrandts of the X and Y axes, or so we thought. Like kids in a toy store, we
went wild over the available colors and cool effects, thrilled with the new
means for techno-artistic expression. Through the magic of computers, the
creation of tables and graphs became easy – perhaps too easy.
Today, everyone can produce reports of quantitative information in the form
of tables and graphs. Children are now taught the mechanics of doing so in
elementary school. To produce something with a computer, however, lends it an
air of authenticity and quality that it doesn’t necessarily deserve. In our
excitement, many of us have forgotten the real purpose of quantitative displays:
to provide our readers with important, meaningful, and actionable insight – in
other words, to communicate the data simply and clearly. Don’t misunderstand me,
I’m not a Luddite, I don’t advocate a return to pencils and graph paper. Rather,
I propose that it’s time to learn and apply knowledge of effective design to the
tools at hand.
Let’s take a look at one final example of the labyrinth that we navigate
daily in our needlessly laborious quest for the numbers:

Without this graph’s title, would you have any idea that its purpose is to
compare the sales performance of the product named SlicersDicers to the
performance of each of the other products? In the general field of design, we
speak of things having affordances – characteristics that reveal how they should
be used. A teapot has a handle. A door that you need to push has a push-plate.
The design of something should suggest – in and of itself – how it should be
used. This graph relies entirely on its title to declare its purpose. Not only
does its design fail to suggest its use, it actually undermines its use.
Now take a look at a solution that was clearly designed to support the
message directly and effectively:
The creator of this display understands visual perception – what works, what
doesn’t, and why – and has applied this knowledge to the visual presentation of
the numbers.
The Remedy
Does this level of expertise require years of training and experience? If it
did, you might be justified in settling for the murky waters of poorly designed
tables and graphs that you wade through today; but it doesn’t. The practices
that produce consistently effective quantitative communication are not intuitive
but they are easy to learn. A few hours of study, reinforced by a few days of
consciously applying the practices to real work, can produce this level of
expertise and much, much more.
Given the right resources, the solution is quick, easy, and inexpensive. It
is up to you to recognize the existence of this problem that currently
undermines your efforts. It is up to you to demand the excellence in
communication that is achievable. Any numbers that are worth presenting are
worth presenting well.
Additional Information:
Stephen Few is the principal of Perceptual Edge, a consultancy that
specializes in information design for analysis and communication. His new book,
Show Me the Numbers: Designing Tables and Graphs to Enlighten is available
from the BetterManagement online bookstore. Stephen can be reached at
sfew@perceptualedge.com. More
information can be found at
www.perceptualedge.com.
The Data Quality Process
By Robert Lerner
Current Analysis
Organizations today have an ever-increasing amount of data and
data
sources at their fingertips. A large organization, for instance, will
typically have numerous databases, data warehouses and data marts, as
well as a variety of enterprise applications such as CRM, ERP, SCM, etc.
It will also have a massive amount of unstructured data and a range of
third-party data sources. A small organization may have less data and
fewer data sources, but this is only a matter of degree, for it will
also have a smaller staff to manage the data and its sources.
Organizations depend on information to be competitive in the market
and to function smoothly and effectively. The real concern is that much
of the information has errors of some sort in it (incorrect values,
missing values, inconsistent values, etc.), and all too frequently
the
data sources—the applications, databases, etc.—are incompatible because
each has its own data format and business rules. Such problems inhibit
an organization’s ability to leverage its data to its fullest, which
ultimately impacts the quality of decisions based on the data.
Now, it is certainly possible for an organization to assess its data
and to address manually whatever problems it discovers. For most
organizations, this is not an efficient and cost-effective method for
handling data quality issues. It is also unlikely that any manual
effort, even if it can be accomplished in one’s lifetime, will achieve
the same level of results as a solid set of data quality tools.
The only practical, effective method of rectifying data problems is
through the use of next-generation data quality tools and processes,
which can do more than correct data errors and render disconnected
information meaningful. Such data quality tools can also keep
information clean and consistent on an ongoing basis. For this, an
organization should consider a data management solution that includes a
tightly integrated data quality tool set and processes that provide
- cleansing,
- parsing,
- standardization,
- matching and linking,
- and householding.
The data quality process begins by using
- a data profiling tool to
analyze and assess the quality of the organization’s data.
- The results
from the data profiling tool locate the precise areas and problems that
need to be corrected.
- Ideally, the data profiling tool should be tightly
integrated with the data quality tool set, as this makes the process of
discovering errors and business rules—along with sharing rules with the
data quality tools—seamless and efficient.
- After the data profiling
process, the data quality process can proceed, beginning with parsing.
Parsing is a process of breaking up the data into its discrete elements
(e.g., first name, last name, street address, city, state, ZIP code, etc.) to
simplify and enhance the data correction process, and all the subsequent data
quality processes. With parsed data, it is easier for the tools to compare and
correct individual data elements than long strings of text. Indeed, once the
data has been parsed, users can zero in on errors such as fields that are
missing data or fields in which the data is misplaced (e.g., a city name in a
street field). It is also easier to locate fields that contain extraneous
information (i.e., information inappropriate to a field such as supplier
information in a part description field). Parsed data can also help spot
inconsistent data structures that may have been the result of incorporating
third-party data.
After parsing the data into its discrete elements, the process of cleansing,
or correcting, data begins. Incorrect addresses, zip codes, account codes, and
so forth are rectified, as are spelling errors and various problems in other
fields. The data quality process also operates on business data (data other than
names and addresses). For example, data correction can address transpositions in
part numbers, as well as problems with commodity codes, gene codes, and whatever
data quality issues impact each particular data type. Finally, when the data is
free of errors, it is standardized, matched, and householded, all of which bring
out some of the real value inherent in the data.
Standardization is a process in which the clean data is put into a standard
or consistent format. Suppose, for example, that the data quality tools
uncovered a number of records on a single customer, Robert Smith. For some
reason his name had been variously entered into the organization’s data sources
as Robert Smith, Rob Smith, R. Smith, Bob Smith, RG Smith, Rober Smith, and
Orbert Smith. As a result, the organization created new customer records each
time a variant in the name was entered. While the cleansing process corrected
the obvious misspellings such as Rober Smith and Orbert Smith, it didn’t
distinguish between the other variants, since they are all superficially
correct.
In the standardization process, the data quality tools determine the correct
variant for this particular person and standardize all the records to a single
standard representation, in this case Robert Smith. This same process works for
company names (e.g., perhaps making IBM the standard for such variants as I.B.M,
International Business Machines, ibm, etc.), as well as disparate data such as
telephone numbers, social security numbers, abbreviations (e.g., Ms., Mr., Mrs.,
St., Street, PO Box, Post Office Box, etc.), titles (e.g., Doctor, Dr., etc.),
and even business data.
After standardization, the organization’s data can then be validated and
verified. Data validation and verification are processes of confirming the
accuracy of certain types of data by comparing them to recognized data sources
as postal databases or other reference sources. For example, this process
confirms the accuracy of a ZIP code (Is it actually a ZIP code? Is it the right
ZIP code for the particular area in which the customer lives?) and whether or
not the customer’s city and state are tied to the appropriate ZIP code.
The next steps in the data quality process are matching and linking, which
are crucial because they help an organization identify hidden relationships in
its data across all of its data sources. For instance, matching will disclose
that, say, Mark Twain and Samuel Clemens are the same person and not two
different people. Linking these records and other records gives an organization
a fuller and more accurate view of its customers, which is critical for customer
service, marketing, tracking customer activities, and the success of enterprise
applications such as CRM. Matching is also crucial in uncovering fraudulent
activities, because it can show, in a hypothetical example, that Saddam Husayn,
Saddam Hussein, and Al-Tikriti are the same person (the variations come from the
Office of Foreign Asset Control or OFAC list of suspect individuals).
Finally, at this stage an organization can household its data.
Essentially, householding is a method to link customers into household groups (the name comes
from the ability to link customers of a particular household). Householding
offers unique insights into customers, and it allows the organization to
track
customer purchases at both the individual and household levels. It also helps
eliminate duplicate mailings, saving both the cost of the duplication and
potentially the customer itself, which often bristles at unwanted and duplicated
mailings.
In the end, cleansed data provides value to organizations in terms of
understanding their business, understanding the customer base, becoming more
competitive, and being able to adequately comply with any number of regulatory
requirements. However, data quality isn’t a one-off process in which data once
cleansed remains clean. Data is always subject to change, because new data is
being introduced into the organization all the time, and because customer data
changes all the time. Customers frequently change some aspect of their personal
information (names, addresses, etc.), households change (marriage, death,
children, etc.), and businesses change (businesses change addresses, go
bankrupt, and so forth). The data itself may even be repurposed.
Because data never remains stable, data quality must be an ongoing process,
one that requires analyzing, improving and controlling an organization’s data on
a continual basis. Data quality is also a process that must be reinforced from
within the organization, with procedures that control the quality from the point
of entry in real time (to eliminate errors before they enter the system) to the
continual monitoring of the quality of the data. It also requires a different
mindset within the organization, one that values the data as a critical,
strategic asset of the organization.
The next article details the third step in the data management process, data
integration.
Additional Information:
Robert is a Senior Analyst for Data Warehousing and Application
Infrastructure at
Current Analysis. Robert is responsible for covering the competitive
landscape for the Data Quality, Enterprise Portals, and Content Management
markets, where he focuses on significant technology, product, and service
developments impacting the evolution and emergence of these technologies. He can
be reached at
rlerner@currentanalysis.com.
Which Way Should Data Flow?
By Rob Spiegel
Automation World
The technology exists to integrate plant floor data into ERP systems to
improve business decisions. But so far, this approach has been less than
effective. Some say the answer is to take business intelligence down to the
plant floor.
You’ve heard it all before. The promises associated with the idea of using
plant floor data to improve business operations are widespread. The data can
help measure—and improve—key performance indicators (KPIs). Plant information
will bring new efficiencies to asset management. The supply chain can be better
optimized.
It’s a rosy scenario. And given recent advances in software that can move
plant floor data to the enterprise level more quickly than ever before, one
might think that the manufacturing industries are on the cusp of a new era of
greatly improved business decision making—all made possible by the broader and
more effective use of factory data.
But there is a major disconnect between the plant manager’s plans for
integrating the data and senior management’s ideas for how the data can best be
used. And the data itself can be a problem. This data was once trapped in
control systems. Now that it can be shared throughout the enterprise, managers
and executives find the data is often misleading, and they can’t seem to figure
out how it can be used to improve the enterprise.
Part of the problem is that plant managers and executives don’t measure the
same business metrics and don’t talk the same language. The plant manager tells
the chief financial officer, “Our new automation system saved us $2 million this
quarter.” The CFO turns back to the plant manager and says, “Where’s the $2
million? I don’t see the savings on the books.”
The Right Data
The most difficult hurdle facing the integration of plant floor information is
no longer technical. The biggest barrier is conceptual. Who needs the data? What
data is needed? And will the needed data really help. Sometimes, control system
data is more than useless—it can be misleading. “Alarm systems can tell you if
you had a motor overload, but they don’t tell you it was because the conveyor
jammed,” says John Cavalenes, account manager at Citect Ltd., a Sidney,
Australia-based supplier of software for managing industrial information. “The
plant system doesn’t give management the information to know they have to change
the conveyor.”
Business executives have become frustrated by the overload of engineering
data that doesn’t help in making business decisions. “More than one CFO has said
to me, ‘If one more engineer tells me how to help the business, I’ll fire him,’
” says Peter Martin, vice president of performance measurement and management,
Invensys Foxboro, of Foxboro, Mass. “We have to push the accounting measurements
down to the plant floor, not take the plant floor data up to accounting.”
Now that the enterprise resource planning (ERP) system can integrate with the
plant automation system, the flow of information between the plant and the
business level tends to go in one direction, up from the plant floor to the
business suite. But as frustration builds over how to use the data, some
industry experts are reevaluating the direction of the information flow. “In the
tobacco industry, they measure everything by equivalent units,” says Marty
Osborn, vice president of product strategy, for Datastream Systems Inc., in
Greenville, S.C. “Let’s take maintenance and measure it from an equivalent units
point of view. Let’s find out if preventive maintenance produces more units.”
What KPIs?
The plant automation systems carry a flood of data, and it’s been a struggle for
plant managers and business executives to agree on what data should be measured.
“As far as KPIs go, there is certainly the capability to get a lot of data,”
says Invensys Foxboro’s Martin. “But the automation domain has been isolated
from the business domain.” Martin notes that engineers and plant managers don’t
measure the same data as business executives. The engineers and plant people use
KPIs to make their plant run more efficiently, and that’s their perspective of
what the business people want to do. The business people don’t know what they
want from KPIs. “In accounting, it’s called performance measures, not KPI,” says
Martin. “The concept of building new KPIs is great, but it has to be resolved to
match the way the business people want to run the business.”
Martin uses the example of a power company that was trying to manage its
power generation from a business point of view. The plant manager’s idea was to
generate power as efficiently as possible. From the business and economic point
of view, sometimes the power generation had to speed up and sometimes it had to
slow down. “The real issue is managing the economic value of the plant according
to the market at this minute,” says Martin. To run truly efficiently from a
business point of view, the power plants needed to change their production
quickly. “The energy company had to manage the way 63 generation plants put
power into the grid. The business people learned that if they send an
instruction to go to three-fourths production for the next two hours, the plants
couldn’t respond. It was optimal, but the plants couldn’t do it,” says Martin.
In this case, the business level didn’t need the KPIs of the plant, the plant
needed to respond to the company’s business measurements. “We’re finding that
the real-time measures and directives need to come down from the business level
to the operators,” says Martin. “We need to be able to take strategy down to the
operator’s dashboard.”
Another area of focus on plant floor data is the ability to improve asset
management. Better plant operations data—if used correctly—can potentially
increase plant system availability and decrease down time. But as with Invensys
Foxboro’s example of the overloaded motor, the data is not always useful. Too
often, asset management is viewed from a maintenance budget or operations point
of view rather than a truly economic view. “Asset management is not maintenance.
Asset management is operating the plant to economic performance,” says Invensys’
Martin. “The objective of asset management is equipment availability and
usability. But the real issue is managing the economic value of the plant
according to the market this minute.”
As with the example of creating KPIs, the greatest need may be to push the
business concepts of asset management down to the plant floor rather than
streaming plant floor data up to those who are balancing the company’s assets.
Send Data Down
As for supply chain optimization, it can be improved when plant floor data is
integrated into ERP systems, but as with the KPIs, the best improvements often
come when the ERP is sending down information to the plant floor. Certainly it
helps the business executives to know production data so inventory levels can be
monitored in real time. But it also helps plant-level managers to know the
real-time value of materials, which lives in the enterprise system. “There is a
need for real-time metrics, but it isn’t just a matter of feeding all the data
up to the ERP system,” says Chris Boothroyd, product manager for BusinessFlex
applications at Honeywell Inc., in Morris Township, N.J. Production information
alone isn’t sufficient to manage inventory. It also has to be managed based on
its changing value. “The value of the materials is known to the ERP, so
sometimes you have to feed data down to the plant floor rather than feeding data
up to the ERP system.”
While technology has provided numerous avenues to take plant floor data up to
the enterprise system, that doesn’t mean organizations will be able to make
business decisions based on the data. The business use of plant floor data will
not become a revolution. The ability to figure out what data is useful, and the
further ability to use the data to improve business decisions will progress
slowly.
In the meantime, there’s a growing chorus that says business information
needs to flow down to the plant floor. “Plant floor data will remain the domain
of the people on the floor,” says Doug Lawson, president and chief executive
officer of DataWorks Systems Inc., a software and engineering services company
based in Mission Viejo, Calif. For the best use of plant floor data integrating
with business intelligence, Lawson believes that manufacturers must take
business intelligence down to plant operators rather than sending plant floor
data up to the business level. “For the plant managers to be effective, you need
to bring decision-making closer to them. You have to bring the business data
tools down to them.”
Blending the Enterprise System With the Warehouse System
The real success stories that come from integrating enterprise systems with
plant software tend to be very specific in nature. The simple act of integrating
or sharing plant data with the enterprise does not produce more efficient
operations. Nor does it automatically improve business decisions. But, the
integration between an enterprise system and a plant system can sometimes solve
a specific problem.
At ARUP Laboratories Inc., in Salt Lake City, warehouse employees had
difficulty locating and retrieving specimen samples. The lab receives 25,000
specimens per day from hospitals. The lab performs 2,500 tests that hospitals
can’t perform. ARUP stores the specimens for a minimum of two weeks—some much
longer—because further tests are often required. This means ARUP keeps up to
500,000 specimens in frost-free deep freeze.
In past years, ARUP sent bundled-up employees into the two-story freezer
1,000 times per day to find specimens. The process was both expensive and
inefficient. In 2002, ARUP moved to an automated system that sends a custom-made
robot into the freezer after the specimens. The specimen tubes are bar-coded so
the robot can read them. The company’s custom-programmed enterprise resource
management system keeps track of all the specimens received from hospitals –
this is tied into the company financials for billing purposes.
The warehouse is run on Warehouse Rx WCS (WRx), a warehouse management system
built by the Columbus, Ohio-based Daifuku America Corp. The system was built to
run the Motoman robot that retrieves the specimen tubes. But the trick to make
the system work was the ability to get the enterprise system to talk to the
warehouse system. “The information about the specimen is in our enterprise
software system,” explains Charles Hawker, director of automation at ARUP. “The
WRx knows the position of the tray that holds the specimen, but it doesn’t know
the identity of the tray.”
When the specimen is taken to the warehouse, the enterprise system knows what
tray the test tube is on and it knows the position on the 30-test-tube tray
where the specimen sits. But the enterprise system doesn’t know where the tray
is. So in order for the automated process to work, the warehouse system and the
enterprise system have to accurately exchange data about 1,000 times each day.
“Both systems are keeping track of the sample,” says Hawker. The
communication among the three software systems produces a very efficient
retrieval process. “We can get one tube out of 500,000 in two or three minutes,”
says Hawker. “That beats the old system where an employee had to put on a parka
and hunt for the right sample.”
Additional Information:
Reprinted with permission from Automation World, copyright 2005 by Summit
Media, LLC. For subscription information, visit
www.automationworld.com.
Statistical Analysis in Business
Intelligence and Data Warehousing
By John Myers
B-EYE Network
Organizations can provide and get value from statistical analysis without
an in-house consultant with a PhD in statistics.
I recently came across an ESPN.com article by Greg Garber, who challenged
whether certain “self-evident” concepts in the National Football League (and
football in general) were really “true.” Some of these “truths” are concepts
taught by football coaches across the country and touted by sports announcers
every weekend from August until February. However, when Garber looked closer at
statistical analysis of the data behind these “truths”; he found that they were
usually not the “truths” that many coaches and broadcasters would have us
believe.
Many readers of this article will probably think this is another of my “lies,
damn lies, and statistics” rants. Instead, this will be a “truth, hard truth and
statistical analysis” rant...
Is The Glass Half Full or Half Empty?
I believe you can make anything look good or bad with a set of associated
statistics or numbers. For example, did you know that Peyton Manning of the
Indianapolis Colts is on a pace to throw 30% less touchdowns this year than
last? Should Manning be faced with a 30% pay cut to match his falling
production? Of course not! The Colts have already won 13 games this season and
are considered one of the favourites to win the Super Bowl.
I also believe that you can gain insight with solid statistical analysis on
those same statistics or numbers, particularly when you start including larger
data sets. This is similar to the datasets available in your well established
business intelligence and data warehousing organizations. These insights can
help confirm assumptions used in business decisions or prevent false assumptions
from being applied.
Don’t Let The Truth Interfere With A Good Story…
In the spring of 1993, an NFL team’s marketing vice president proudly told me
that he did not need a marketing research firm to tell him what or how to sell
to his fans. Those fans would simply tell him by coming to the games or not.
Today, I believe that he knew what he was talking about. This man had over 10
years of experience, with his job, his product and his city. However; he was
only dealing with a maximum of 700,000 sales events (game tickets) a year. This
was also done on 10 individual Sundays over a five month period, in a limited
geographic area. Cingular, for example, has more than 50 million nationwide
subscribers across two separate product catalogs of Cingular and the old AT&T
Wireless. Using the same “statistical” analysis as that of the NFL team's
marketing vice president, would not be advisable for today’s average telecom
service provider. While that does not mean that today’s telecom marketing vice
president does not have a really good feel for marketing, it might be good to
also refine/reinforce those decisions with valid statistical analysis.
Now, I am not advising that every marketing decision or business rule be
vetted through statistical analysis using every bit of knowledge in the
enterprise data warehouse. That is the very definition of “analysis paralysis.”
However, I recommend using the field of statistical analysis to:
- Confirm and/or validate the “gut” feelings of many marketing vice
presidents.
- Provide the basis for rules engines that are becoming more popular in
credit analysis applications for new customers or fraud analysis of existing
customers.
This is where business intelligence and data warehousing organizations can
provide value for various business areas. And this can all be done without a PhD
in statistics.
The 80/20 Rule
As many of you know, the Pareto Rule is often called the “80/20 rule.” The
Pareto Rule stresses that approximately 80% of something can be caused, affected
or influenced by 20% of the effort exerted on that something. For example,
approximately 80% of all network events (i.e. call detail records, IP detail
records) come from a relatively small set of 20% of possible network event
types—the most common types of events. The other 20% of traffic comes from the
other 80% of possible events—the outliers.
Everything is 42
From the classic Douglas Adams’ books, the answer to question of life, the
universe and everything is “42.” Essentially, this means that you must know what
you are asking before you ask it. This is the key with statistical analysis
tools. If you do not know what question you are asking, you probably will not
understand the answers to the questions or you might use the answers
incorrectly. When you are talking about millions of customers and their billions
of interactions with your company, this can be an expensive proposition if you
do not understand the data.
This is where those pesky consultants come in…once more. Again, I suggest you
only “invite” them in with VERY specific objectives. These objectives should be
to:
- Answer specific questions.
- Accomplish this in a specific timeframe.
- Document the entire process before you write them a check/issue a
purchase order.
If the consultants have done their job correctly and you have worked to learn
from them, a business intelligence or data warehousing organization is now armed
with the appropriate knowledge. This knowledge should continue to provide
roughly 80% of the consultants’ value for about 20% of their cost.
New and Improved
With the current generation of database management systems and business
intelligence toolsets, business intelligence and data warehousing organizations
are now provided with statistical analysis tools. In the past, these tools were
reserved for consultants with PhDs in statistics. But as I noted above, you
might not get the answers you want if you do not understand the tools or what
they are trying to accomplish. If your consultants have properly documented
their processes, a statistics text book or online training should be enough.
Final Thoughts
Many data mining and statistics professionals will justifiably be offended by
the nature of this article. I am not trying to dislodge the data mining and
statistics professionals from the telecom enterprise... Companies like Oracle,
Microsoft and Business Objects are already trying to do that by including
“canned” statistical analysis packages with their software.
Instead, I want to show that organizations without an in-house PhD in
statistics can provide value to the organization. These organizations can also
emphasize the importance of the data in their data warehouses, rather than
having to pay consultants.
Additional Information:
John Myers has more than 10 years of information technology and consulting
experience in positions ranging from business intelligence subject matter
expert, technical architect and systems integrator. Over the past eight years,
he has a wealth of business and IT consulting experience in the
telecommunications industry with American Management Systems and CGI. John
specializes in business intelligence/data warehousing and systems integration
solutions. He can be reached at
JohnLMyers@msn.com
Business Performance Intelligence: A
New Dimension in Corporate Profitability and Accountability
SAS
It's a tough time to be a chief executive.
Top corporate officers have always been under intense pressure to meet
earnings projections and improve profit margins in a turbulent economy...
continually find and enact cost-reduction opportunities... maximize shareholder
value without compromising market responsiveness... deliver immediate ROI
without undermining long-term returns... grapple with unpredictable fluctuations
in stock prices and analyst goodwill... and proactively manage erratic
performance indicators and market trends.
Now, by mandate of the U.S. Securities and Exchange Commission under the
Sarbanes-Oxley Act, CEOs and CFOs also have to attest personally to the veracity
of their financial statements. Executives who certify statements they know to be
false can now face criminal charges, fines up to $5 million and jail terms of up
to 20 years. Furthermore, they’re being held to broader disclosure requirements
and shorter reporting deadlines than ever.
What's the answer for financial executives who need to expand their focus
beyond cost control and into value creation and strategic directives? What's the
answer for business strategists trying to navigate a profitable course in
turbulent seas? Or for executives who are now personally accountable for what
happens on their watch?
More than ever, companies need to align customers, suppliers and their own
organizations in one strategic direction. That direction must be based on a
holistic view of interdependent variables and tradeoffs across functions and
organizational boundaries. Decision makers at all levels of the organization
must be empowered to make effective decisions in rapidly reduced timeframes.
The answer is business performance intelligence, a new business model that is
more efficient and dynamic than traditional business practices. It combines
integrated business strategies from three key areas into a unified,
enterprisewide vision — one that is measurable, sustainable, actionable and
continuously fine-tuned to reflect market dynamics and performance results. This
business performance intelligence approach combines:
- Financial management solutions that streamline and automate the
planning process, foster enterprisewide consistency and cooperation and
produce more sophisticated and meaningful analysis than transaction-based
systems and spreadsheets ever could.
- Activity-based management that mirrors the real, day-to-day
activities of people and equipment, rather than traditional
slicing-and-dicing of costs by direct labor, direct materials and best-guess
allocations of overhead.
- Strategic performance management that reflects the interdependent
nature of business variables to create an alignment and focus on strategy
that transcends functional and organizational boundaries.
The point where these three solutions intersect is business performance
intelligence. It represents a new approach that redefines how business is
managed, how customer and shareholder value are generated and what levels of
accountability and integrity are possible.
The Reality of Recent Innovation
You've seen the headlines in the business press heralding an economic shakeup
that goes far beyond the collapse of the dot-com deck of cards. High-flying
corporations with decades of market dominance are losing ground. Powerhouse
companies with market-leading products are posting staggering losses and laying
off tens of thousands of workers. Companies that hold the top market positions
in their industries are watching their stock values plummet to a fraction of
their former worth.
What gives? If success breeds success, why are some of the world's most
"successful" companies struggling with slimmer margins and more unpredictable
performance results than ever before?
The reality is that the technology innovations — particularly communications
advances — that spawned dramatic economic gains in the last decade also spawned
an entirely new economic model, for better and for worse. For example, the
Internet brought a wealth of sales and communication opportunity; at the same
time it compressed business planning and decisionmaking cycles, introduced new
competitive pressures and ratcheted up baseline expectations for performance and
turnaround.
Trends that were once tracked by quarters now fluctuate from day to day.
Yesterday is history, and it's not a very good predictor of tomorrow. This
business climate swiftly punishes companies that continue to believe in
traditional timelines, conventional cost/revenue targets and established ways of
doing business.
In the '90s, we were riding the crest of a five-year wave of growth and
prosperity — a boom cycle in which companies could prosper even if they didn’t
have deep visibility and control over business operations. They thrived on the
same business management philosophy that had fueled their success for the
previous 25 years, that is: optimize business processes in each unit, and these
unit successes will trickle up and create success for the company as a whole.
Business cycles change. The tight market that has evolved within the last 24
months revealed companies in all industries that lacked operational maturity,
strategy and methodologies required to profit and prosper in leaner times.
Familiar Challenges Gain New Urgency
In an unforgiving economy, chief executive officers are asking, "How can we
position the company for profitable growth and integrate strategy with daily
business operations? How can we foster adaptability and innovation without
abdicating control? How can I be sure of the integrity of our financial
statements?"
Chief financial officers are asking, "How can we move beyond the role of
cost-cutting police to be seen as a strategic partner? How can we accurately
assess profitability by product, service and customer? Manage capital
effectively without compromising service and value?"
Top executives in HR and IT are asking, "How can we manage costs without
compromising service levels... attract and retain qualified people... show the
organization our value?"
Sales and marketing executives are asking, "How can we identify and keep the
most profitable customers, find and act on the most promising market
opportunities and manage trade-offs between the costs and rewards of serving our
customers?"
These questions aren't new. What's new is the pressure to deliver the right
answers in an increasingly complex business environment — one in which
interdependent factors are tracked in incompatible systems and controlled by
groups that don't speak to each other. What's new are the harsh penalties for
delivering the right answers too slowly, or not at all — or for signing your
name to wrong answers delivered to the Securities and Exchange Commission.
A Convergence of Strategic Management Approaches
The answer to all these questions is business performance intelligence,
a new business model that combines integrated business strategies from three key
areas into a unified operational and strategic framework with enterprisewide
vision. The business performance intelligence approach combines:
- Financial management solutions that streamline and automate the
planning and forecasting process; foster enterprisewide consistency,
transparency and cooperation; and produce more sophisticated and meaningful
analysis and reporting. Financial management helps eliminate manual
financial processes that put the integrity of your financial information at
risk.
- Activity-based management that mirrors the real, day-to-day
activities of people and equipment, rather than myopic views of direct
labor, direct materials and overhead. Activity-based management uses
sophisticated modeling to help enterprises understand the true profitability
of products, services and customers.
- Strategic performance management that reflects the interdependent
nature of business variables to create alignment and focus on strategy,
transcending functional and organizational boundaries. Strategic performance
management automates and manages the process of developing, disseminating
and carrying out strategies, incorporating proven methods such as Balanced
Scorecard.
The point where these three solutions intersect is business performance
intelligence. It represents a new approach that redefines how business is
managed, how customer and shareholder value is generated and what levels of
accountability and integrity can be achieved.
Why Combine Solutions that Already Represent Integrated Viewpoints?
This unified approach reflects the complex reality that business
variables are all interdependent.
The flow of these variables does not follow organizational boundaries.
Adjustments or fluctuations in any one measure, line item or performance
indicator inevitably affect something else, and vice versa. Real costs and value
are embodied in both tangible and intangible assets. Departmental success might
cannibalize success in other groups or undermine enterprise goals. This
quarter's bottom-line gains might sacrifice some long-term profitability. Cost
cuts might have shaved dollars in one area while costing many times more in lost
sales and reputation.
Business performance intelligence reflects this interdependence by creating
new possibilities at the intersections of existing, integrated solutions.
Where financial management and activity-based costing converge:
- Organizations can distill a true understanding of the costs and profit
associated with a product, customer, service or business process — and
formally incorporate that intelligence to plan and manage profitability.
Where activity-based costing and strategic performance management
converge:
- Organizations create an insight into how activities support strategic
goals. In turn, this helps management ensure that resources are deployed in
the most effective way possible — matching skill sets and competencies to
the task at hand. With an insight to cost, it further ensures that the right
people do the right things at the best price. All of which leads to
efficiency, effectiveness and alignment across the entire organization.
Where strategic performance management and financial management converge:
- Organizations can tightly integrate planning processes with
target-setting and performance management and ensure that new strategic
actions are reflected in planning in a closed-loop, continuously improving
cycle.
The intersection point of all three solutions is the point where
organizations are truly integrating finance and operations, strategy and
tactics. According to a recent FEI Research Foundation report, business
performance intelligence enables even large, intricate organizations to: "(A)
plan and manage around organization processes, activities and outputs, in order
to (B) integrate financial and operational planning and performance management,
so that (C) organizations can more effectively deploy strategy and allocate
resources horizontally across functional and organizational boundaries."
Furthermore, a convergence of integrated solutions provides some tangible
process advantages:
- Single version of the truth. In the SAS implementation of
business performance intelligence, the financial, costing and performance
management components all draw their data from a central data warehouse. The
system can read data from virtually any source in virtually any form,
consolidating operational data from disparate systems into a powerful,
consistent information resource.
- Data integrity. The data warehouse does more than collect data;
it helps users make sense of it by transforming it into useful information,
storing it and then delivering it in a consumable format where quality is
never in question. Best-practice data management cleanses data of such
problems as ambiguous representations, duplicate data, illogic revealed
through crosschecking, data structural incompatibilities, missing values and
other issues hazardous to the health of a business intelligence system.
- Information sharing. By integrating financial, costing and
performance management solutions around a shared data warehouse, disparate
functions and groups can now automatically share information in ways that
previously were cumbersome or even manual processes. Analysts can now spend
their time distilling knowledge from data, rather than extracting and
reformatting it to prepare for analysis.
- Knowledge sharing. Business performance intelligence tools encode
any number of business rules, assumptions, evaluation criteria and key
performance indicators in models — which are then applied against data from
the data warehouse. Users can analyze and drill into the data to reveal
understandings that could have been overlooked with access to business
knowledge from only one solution set.
Real-world Implications
What happens when you can provide a seamless flow of business intelligence
across the entire organization, based on a single version of the truth? With a
business performance intelligence approach, enterprises can:
- Optimize shareholder value by more effectively managing the trade-offs
between customer value and shareholder value, taking tangible and intangible
factors into consideration.
- Enable natural adjustments of strategic directions and cost structures
to reflect changing market conditions, thereby aligning overall profit
objectives with what the market will bear.
- Evolve from an output-focused organization to a customer-centric
organization, one that expresses strategic objectives in terms of processes
and activities.
- Define and execute strategies that transcend organizational and
functional boundaries and are continuously updated through feedback from
performance results.
- Produce more accurate plans and forecasts in less time by automating the
submission process, promoting collaboration across functional boundaries,
making planning assumptions more explicit and aligning financial objectives
with performance management objectives.
- Present meaningful information in a form that is relevant to users,
offers an enterprisewide perspective across solution areas and is easily
accessible over the Web.
With a business performance intelligence approach, executives and other
decision makers can react to changing market, customer, supplier and revenue
conditions as they happen — not just after they become historical information.
This 'self-tuning' capability supports the enterprise's ability to be proactive
rather than reactive in its daily operations.
Additional Information:
For additional information on Business Performance Intelligence, visit
www.sas.com
Unlocking the Value
of Your CRM Initiative. The Strategy plus Technology Dynamic
ABSTRACT
Implementing a CRM strategy is much more than a technology
initiative. Companies that view buying CRM Technology as "Implementing
CRM" will fail to realize the significant ROI to be gained from
effective CRM. Their efforts will under-perform or fail- not because the
technology didn't work, but because they did not establish any or all of
the following: (1) a well-planned CRM vision and strategy supported by
executive leadership; (2) actionable customer insight based on customer
needs and value; (3) customer-focused
processes; (4) measures to ensure adoption, such as training,
incentives, and metrics.
Executive Summary
CRM Strategy and Technology
For an organization to declare victory with their CRM initiative. It is
important to focus on the two key components of strategy and technology. CRM
strategy is the sum-total of all planning, development and adoption activities
needed to achieve a company's customer-related goals. CRM technology is the
systems based application(s) and integration that facilitates and supports the
customer interaction. In order to ensure the highest likelihood for CRM success,
critical up-front investment is required to gain deep insight into what is
aspirational and what is realistic. Companies that fail at CRM do so because
they believe technology alone is the "silver bullet." Companies that don't
manage the customer base as a dynamic asset cultivated over time will not
capture short and long-term wins with ROI from the overall CRM initiatives.
A proper strategy must be put in place in order to correctly implement and
deploy technology, utilize that technology to enable customer-focused processes
and generate meaningful returns for both the company and the customer. This
white paper will outline the critical steps that must be taken to establish a
CRM strategy, manage the customer base as an asset, utilize technology and
unlock the maximum value of a CRM plan.
Gartner asserts that through 2005, CRM initiatives focused only on technology
are three times more likely to fail than those that focus first on process, then
design and deploy technology to automate the process (CRM Business
Transformation: More than Just Technology, Gartner Group, June 2003). On the
other side of the coin, Meta Group's research found that companies are three
times more likely to be successful if they have a consulting partner to help
them devise a strategy, assess business process needs and leverage technology
based on that plan. (Mid-Market Comes of Age, 1to1 Magazine, April 2003). To
increase likelihood of success, again it is evident that companies must
establish the crm strategy and processes first, before implementing the
supporting technology.
Viewing the customer Base as an Asset
The customer base is not traditionally listed as an asset on balance sheets
and financial reports. CRM requires a change in mindset, in that the customer
base is in fact the most important asset of the company. As an asset, the
customer base and a company's established customer relationships cannot be taken
lightly. Customers recognize when an enterprise does not value their business or
care about their needs. An example is a sale of customer data which destroys
existing trust or loyalty.
Gartner's strategic assumption is through 2004 up to 80 percent of companies
will not have a CRM strategy that details how to turn customers into a "company
asset." By omitting this concept from their strategy, these companies
will allocate time and resources to implementing customer strategies, without a
clear view of which customers to focus on and how to build the greatest value
from this asset (The Importance of Developing a CRM Strategy, Gartner
Group, October 2003).
There are several key factors necessary for a successful CRM implementation
that go well beyond technology. Implementing CRM technology is often incorrectly
equated to "implementing CRM." In actuality, CRM is a business strategy that is
enabled by technology. At Peppers & Rogers Group, we refer to CRM simply as the
ability to "treat different customers differently." CRM can be defined using
Peppers & Rogers Group "IDIC" methodology, which serves to:
- Identify customers individually and addressably
- Differentiate customers or customer groups based on their needs
and value
- Interact with customers in a way that benefits them and the
company
- Customize the relationship over time based on the company's
understanding of the customer's needs and value.
Companies with a winning CRM strategy examine customer interactions through
the "eyes of the customer." and build customer-focused strategies and processes
to establish and maintain long-term profitable customer relationships.
Effectively leveraging technology to enable the CRM strategy and processes is
important, but one must keep in mind that the technology is a tool to support
the strategy, and is not CRM itself.
Research studies cite high CRM failure rates, such as a Gartner Group
statistic stating that 55 percent of all CRM projects do not produce results.
All companies, and particularly small and mid-market companies that may not have
been involved in the first wave of CRM implementations, can learn from and avoid
past CRM mistakes. Typically, many of these corporations spent significant
amounts on technology without first developing the necessary CRM vision,
strategy, and process.
In understanding why certain CRM initiatives fail to achieve their
objectives, it is evident that the reasons lie not in the technology but rather
in a lack of focus on the key CRM foundational elements required for success.
These elements are centered on four areas:
CRM vision and strategy - A clearly defined CRM vision and
strategy with executive and cross-functional leadership and support is
imperative for success.
Customer information - Companies must analyze the customer base to
differentiate customers by their needs and value, in order to turn the data into
action and "treat different customers differently."
Customer-focused process design - Designing processes from the
customer point of view is critical in order to enhance the customer experience.
Adoption - Key aspects of change management must be addressed to
ensure adoption, including a customer-focused organizational design, training,
incentives and metrics.
When these elements are addressed and supported by technology, CRM is a
strategy that will produce significant ROI and competitive advantage. As shown
in the following chart, synchronized deployment is the key to effective
implementation. According to a january 2003 PricewaterhouseCoopers "Trendsetter
Barometer" survey, 81 percent of the fastest growing U.S. companies have
initiated CRM programs over the past three years, and the majority are
significantly expanding their customer-focused efforts this year. These firms
have achieved 46 percent faster revenue growth than their competitors over the
past five years (fueled by an expected 60 percent faster revenue growth rate for
2003).
Please see figure Synchronized Deployment
of a CRM Initiative
1- CRM Vision and Strategy
Executive Vision and Support
A carefully constructed vision and strategy, supported by the executive team
is the most important foundational element for a CRM initiative. According to
Garner, 75 percent of initiatives that do not deliver measurable ROI fail due to
lack of executive involvement. In a May 2002 study of 197 U.S. marketers'
opinions on the "single biggest" reason for a firm's CRM success, the responses
"marketing strategy" and "executive commitment" garnered the highest percentages
with 32 percent and 26 percent of the responses respectively (Reveries.com, May
2002, www.eMarketer.com). As with any cross functional initiative, a critical
foundational element is that vision and strategy are understood and clearly
communicated to the entire organization by the executive team. Strategy and
executive commitment are cited as "make or break" areas, much more so than
technology. This may seem obvious: however many companies that believed that CRM
was a technology initiative or that thought CRM only affected a certain function
like sales or marketing leaned the hard lesson by leaving the CRM strategy up to
one function, such as IT or marketing.
|
1 |
|
|
|
|
| |
Blueprinting |
|
|
|
|
|
|
|
|
|
|
Developing process flows to |
|
|
|
achieve selected strategies |
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
| |
Process Engineering |
|
|
|
|
|
|
|
|
|
Conditioning organization |
|
|
|
to adopt new processes |
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
| |
Digitization |
|
|
|
|
|
|
|
|
|
|
Developing technology that |
|
|
|
supports required process flows |
|
|
|
|
|
|
|
|
4 |
|
|
|
|
| |
User Engagement |
|
|
|
|
|
|
|
|
|
|
Getting target users to |
|
|
|
|
successfully utilize applications |
|
|
|
|
|
|
|
|
|
The effective implementation of a CRM initiative requires a synchronized
deployment of customer |
|
strategy, process design, technology implementation and change
management. |
|
|
Executives must uphold and communicate the vision that CRM is a critical
initiative that will build a competitive advantage and generate significant ROI
for the company. They need to understand and convey that CRM is not only about
technology, but instead about exceeding customer expectations to develop
long-term, profitable relationships. Executives must be "customer champions" who
help the organization maintain a customer focus, reinforce CRM goals and
objectives and emphasize the benefits to the customer, the company and the
employees.
Given that many past CRM initiatives have under performed or failed,
executive leaders must be willing to take risks and face tough opposition, try
out new concepts and learn in order to make improvements. Executive leadership
must believe in CRM, provide support and funding, communicate successes and be
persistent in overcoming obstacles.
It is important for the organization to understand that CRM is a journey and
not a destination. In other words, companies will never be able to declare that
they have perfected their customer relationships, and that it is time to stop
focusing on CRM. Instead, executives must portray a customer focus / CRM as a
fundamental ongoing aspect of the overall company vision. As well, the CRM
vision and strategy must be kept current, ensuring that it is aligned with
overall corporate objectives and that it evolves, as customers change, in order
to produce the greatest value for the customers and the company.
Cross-Functional Strategy With Measurable Objectives and Roadmap
CRM does not pertain to only one function or only one customer-facing
employees; it is an enterprise-wide strategy that involves any group that
interacts with the customer either directly or indirectly. CRM involves creating
a seamless experience between the customers and all ares of the organization.
Therefore, a cross-functional team must be created and empowered to develop and
implement a cross functional CRM strategy. Establishing a cross-functional team
with a cohesive mission that encompasses all the customer touchpoints will also
assuage some of the internal politics and siloed objectives that can derail a
CRM initiative. In addition to internal team members, ideally the team should
include customers and channel partners.
Please see figure The CRM Business
Transformation.
The cross-functional team must take the high level vision and strategy to a
more detailed level, developing the comprehensive strategy and specific ROI
objectives. The objectives must be clearly defined and measurable, tying into
the CRM vision. The team should develop short- and long-term CRM objectives
along with the implications and benefits for each stakeholder. The will also
need to develop a clear project plan and roadmap depicting the tactics,
responsibilities and timeline that each team member is expected to adhere to
throughout the CRM implementation. With a cross-functional team, each group will
play a role in developing the CRM strategy engendering greater understanding and
acceptance when the time comes for functional areas to implement and adopt the
new customer-focused strategies, tactics and processes.
|
|
Customer-facing strategies |
|
|
|
|
|
|
|
|
|
|
|
|
Customer selection |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Customer acquisition |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Customer retention |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Customer growth |
|
|
|
|
|
|
|
|
|
|
|
Viewing the Customer Base as an Asset
The customer base is not traditionally as an asset on balance sheets
and financial reports. CRM requires a change in mindset, in that the customer
base is in fact the most important asset of the company. As an asset, the
customer base and a company's established customer relationships cannot be taken
lightly. Customers recognize when a company does not value their business or
care about their needs, such as when companies sell lists of their information,
destroying any existing trust and loyalty.
Gartner's strategic assumption is that through 2004 up to 80 percent of
companies will not have a CRM strategy that details how to turn customers into a
"company asset." By omitting this concept from their strategy, these companies
will allocate time and resources to implementing customer strategies, without a
clear view of which customers to focus on and how to build the greatest value
from this asset (The importance of Developing a CRM Strategy." Gartner Group
October 2003).
CRM requires that a company develop strategic initiatives to grow the value
of the asset. In other words, companies must customize or improve some aspect of
their products or services to create value for their customers, in turn,
building customer satisfaction and loyalty. To do this, the company must
understand how customers differ from each other in terms of their value to the
company and their needs from the company. Customers that have similar value and
needs should be grouped into "Customer Portfolios." Like financial asset
management, " Managing by Customer Equity" (MCE) involves focusing resources and
creating accountability for growing and retaining the value of the portfolio.
The diagram below depicts the objective of MCE to grow and maintain the lifetime
Value (LTV) of customers.
|
Goals |
|
|
|
|
|
Revenue |
|
(i.e., growth) |
|
|
|
|
|
|
|
Profit |
|
|
(i.e., margin) |
|
|
|
|
|
|
|
Market share |
|
(i.e., volume) |
|
|
|
|
|
|
|
|
|
|
Cash flow |
|
(i.e., liquidity) |
|
|
|
2- Customer Information
Who to Build Relationship With?
As previously stated, considering the customer base as an asset should be a
fundamental aspect of any CRM strategy. To understand that asset and identify
customers that the company wants to build relationships with, the company must
identify, capture, retain, analyze and best utilize customer information. In
doing so, companies are focusing on the "I" and "D" of Peppers & Rogers
Group's IDIC methodology:
- Identify customers individually and addressably, and
- Differentiate customers or customer groups based on their needs
and value.
Before implementing any CRM initiative or enabling technology, a company must
first have a clear understanding of how its customers differ in value to the
company and in their needs from the company. To implement CRM technology without
first analyzing and segmenting the customer base would equate to building a
system or buying tools without knowing how you were planning to use them.
Knowing customers' value assists a company in its resource allocation
decisions, whereas knowing customers individual needs facilitates customization
of its interactions, products or services to build one-to-one relationships with
customers. The intersection of customer value tiers and needs clusters creates
the customer portfolios to be managed by the company. Managing by Customer
Equity (MCE) involves recognizing which customers are the most valuable or have
the most potential, understanding their needs to provide value to them and
develop mutually beneficial relationships.
Customer Value Differentiation
Companies should begin by segmenting the customer base by value, both Actual
Value- the customer's current value to the company, as well as by Potential
Value - the unrealized potential of a customer. This approach enables a company
to then focus its relationship-building efforts on its Most Valuable Customers (MVCs)
- customers with high Actual Value, and its Most Growable Customers (MGCs) -
customers with high Potential Value, while divesting resources from customers
with limited or negative Actual or Potential Value.
Companies often do not realize that many of their large customers who they
consider to be their best customers, since they provide a significant amount of
revenue, are actually unprofitable because the costs associated with serving
them are greater than the value they provide.
Customer value differentiation enables a company to deliver targeted
programs, services and relevant messages to customers that provide the greatest
growth and value, instead of scattering its marketing and sales efforts.
Companies that proceed down the "technology-first" path typically end up with a
scattering effect, serving unprofitable customers, neglecting the profitable
ones and losing money in the process. By concentrating on customers with the
greatest value and growth potential, finite resources can be allocated and
aligned accordingly to generate the highest return on investment (ROI). Customer
value differentiation provides unique insight by identifying:
- Most Valuable Customers to retain
- Growth opportunities
- Opportunities for cost reduction
As mentioned, the two primary components of customer value are Actual Value
and Potential Value:
Actual Value is defined as the customer's expected Lifetime Value
(LTV), calculated as the net present value of a customer's expected stream of
future contribution. Actual Value is the Lifetime Value of the customer if there
is no change in the way the company treats the customer and the way the customer
responds. Understanding Actual Value enables companies to align resources with
their Most Valuable Customers (MVCs) and identify customers that have low or
negative contribution (barely cover their attributable costs).
Potential Value is defined as a customer's potential growth based on
share of customer analysis. Unrealized growth potential is defined as the
percent of dollars not spent with the company, but rather with the competition.
Understanding Potential Value helps a company identify which customers have the
greatest potential to be Most Valuable Customers in the future.
Considering both a customer's Actual and Potential Value assists in
determining whether the focus should be on growing share of customer (customers
with relatively high Potential Value) or on retaining existing business
(customers with relatively high Actual Value). However, looking at only Actual
or Potential Value provides only part of the picture. The diagram below
illustrates how customers differ in opportunities for growth and retention.
Customer Needs Differentiation
In addition to understanding customer value, companies must also understand
how the needs of their customers vary. They can then utilize this information to
deepen their knowledge of customers and customize solutions to meet their needs.
Companies should view customer needs and value information together to form
customer portfolios. This helps the enterprise allocate more time and resources
customizing solutions to meet the needs of customers with the highest Actual and
Potential Value.
The goal of customer needs differentiation is to identify clusters of
customers with similar needs around which companies can build customized
strategies and relevant treatments. The ultimate objective is one-to-one
customer relationships with these customers. "Customer Needs" refer to why the
customer buys.
Customer needs are the internal conditions or motivating desires behind a
customer's purchase or usage of a product or service. Customer needs are complex
and involve many dimensions and nuances including beliefs, motivations,
preferences, life stages, decision-making styles and more.
|
The Benefits of Customer Needs Differentiation include:
- Increasing the company's credibility with customers and
customer loyalty by improving the customer experience, understanding
customers needs and providing relevant offerings that exceed
customer expectations
- Increasing efficiency and maximizing the effectiveness of
customer-focused efforts by allocating time and efforts in areas
that are most relevant to the customer
- Realizing positive financial impact by maximizing short- and
long- term customer value and improving cost-efficiency through
improved customer targeting
|
Analytics Enables CRM
Of course, the analysis of the customer database and the creation of customer
portfolios around customers with similar value and needs is useless unless the
information is acted upon. The ability to turn customer information into insight
and then turn insight into action is essential to implementing CRM.
|
1 |
Gather Customer Data |
|
|
|
(both internal and external) |
|
|
|
|
|
|
|
|
|
* Contact information |
|
|
|
* Preferences |
|
|
|
|
* Purchasing behavior |
|
|
|
* Customer interaction history |
|
| |
|
|
|
|
|
|
2 |
Derive Customer Insight |
|
|
|
|
|
|
|
|
|
|
|
* Customer needs |
|
|
|
|
|
* Customer value |
|
|
|
|
|
* Customer defection |
|
|
|
|
* What products customer will need next |
|
|
|
|
|
|
|
|
|
4 |
Evaluate Response |
|
|
|
|
|
|
|
|
|
*Increase in customer satisfaction |
|
|
*Incremental customer contribution |
|
|
*Decrease in defection rate |
|
|
|
*Increase in customer share |
|
|
|
*Increase in customer loyalty |
|
|
|
|
|
|
|
|
|
3 |
Suggest Proactive Action |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
* Align Marketing & Sales resources to customers based on
opportunity |
|
|
* Develop customized marketing collateral based on customer
needs |
|
|
|
* Feed customer insights to product development |
|
|
|
|
|
* Train marketing and sales staff on applying customer insight |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Customer analytics is a specialized capability or function necessary for a
company to conduct the data analysis and customer-modeling activities required
to develop the customer needs and value differentiation described previously.
Customer analytics is a complex function that requires mining all available
customer data from multiple sources, and running statistical and financial
algorithms and models to understand customers' value, behavior, profiles,
preferences and characteristics. The goal is to predict future customer
behavior.
The output from customer analytics is customer portfolios that can then be
used to define specific treatment strategies, or to customize products, services
or interactions for customers in each portfolio. The information is converted
into a greater understanding of which customers are the most valuable to the
business, and what those customers need, prefer and want from the company. It is
at this point that it becomes actionable customer insight. This insight enables
the organization to "Treat Different Customers Differently."
The diagram below outlines the process, data elements and resulting benefits
of using customer insight and analytics to drive competitive advantage.
A management plan should be developed for each customer portfolio that
utilizes customer analytics to define goals, objectives, expectations and
treatment strategies for customers in each portfolio. This plan should be
developed with the appropriate channels or functions to define the customized
treatments for different types of customers, applying the customer value and
needs information. As shown in the diagram, it is important to leverage customer
insight to implement specific customer-focused actions, and learn from the
response to improve future customer treatments. Companies that leverage customer
insight to improve the customer experience will better compete and win in
today's customer focused marketplace.
Please see figure Manage analytics overview
3- Customer-Focused Process Design
Processes that Facilitate Relationship-Building
Clear customer-focused processes and business rules must be established in
order to implement the strategies and tactics customized to meet different
customer needs. Customer-focused process design addresses the second "I" and "C"
of the Peppers & Rogers Group's IDIC methodology, establishing the ability to:
- Interact with customers in a way that benefits them and the
company
- Customize the relationship over time based on the company's
understanding of the customer's needs and value.
A key aspect of CRM is developing or revamping key business processes using a
holistic customer-centric approach. In taking a customer perspective, processes
will be built to improve the customer experience and support relationship
building. Internally driven initiatives that, for example, aim to increase
efficiency can actually worsen customer relationships, such as a orocess to
increase efficiency by reducing customer talk time. Gartner's strategic
assumption is that "companies that give the highest priority to business
processes that deliver the greatest customer-defined value and measurable
business outcomes, will gain greater customer loyalty" (CRM Business
Transformation: More than Just Technology, Gartner Research, June 2003). For
companies that have based their current and future business growth strategies on
customer-centricity, the need to effectively balance internally and externally
focused activities is paramount. While the investment to implement may be deemed
costly, so long as there is offsetting measurable value creation that delivers
against the CRM objectives, the company should proceed.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Processes |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Market segmentation |
- Lead management |
- Order management |
- Customer business analysis |
|
|
|
- Campaign planning |
- Needs assessment |
- Installation |
|
- Needs reassessment |
|
|
|
- Brand and account |
- Proposal generation |
- Inquiry handling |
|
- Up-sell/cross-sell |
|
|
|
|
planning |
|
- Closing the deal |
|
- Problem resolution |
- Campaign management |
|
|
|
- New product launch |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Functional Owner |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sales |
|
x |
|
x |
|
|
x |
|
|
x |
|
|
|
|
Marketing |
x |
|
|
|
|
|
|
|
x |
|
|
|
|
Customer Service |
|
|
|
|
|
x |
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Companies must take the time to identify and design customer-focused
processes in alignment with CRM strategy in order to achieve their CRM
objectives.
Designing new approaches or revamping existing ones involves establishing
specific steps and business rules, links to other processes and touchpoints,
responsibilities and and associated metrics for each process, before
implementing technology. In this way, the company can ensure systems are built
according to the requirements of the new customer-centric focus, saving systems
development time and expense by avoiding rework.
Connectivity
In addition to approaching process design from a customer point of view, the
processes required to implement a CRM strategy must be developed in a way that
provides connectivity between touchpoints. Internally, front- and back-end
processes must be integrated so that customer information can be shared across
channels. Successful CRM initiatives permeate virtually all areas of the
organization, utilizing customer insight to drive action in areas such as the
supply chain, product development cycle, financial systems and service delivery.
All aspects of the business and associated processes should be centered on the
customer, thus connectivity and coordination between all touchpoints,
departments and business units are essential.
Additionally, the creation of a comprehensive CRM information strategy is
necessary to ensure that appropriate customer information is captured, shared
and managed across touchpoints to enable the appropriate execution of the
customer-focused processes. Customer insight must be available quickly and at
the right time to support a smooth execution of the processes.
To illustrate, when a customer interacts with a company, whether it be with
billing, customer service, the retail associate, their account manager or the
CEO, he should feel like he is having a continuous conversation with the company
and that each person at the company understands his individual needs and
situation. Customer expectations are continually increasing while their
tolerance for fragmented experiences is decreasing. For example, customers
expect:
- Companies to value them and know who they are, their needs and
preferences, regardless of contact channel
- High-quality, speedy interactions regardless of the channel
- Companies to respond via the customer's preferred contact channel
- Real-time access to their own and company data
- Self-service and 24/7 service
- Immediate and useful responses to inquiries
Customers should not be aware of or negatively affected by a company's
integration or CRM implementation efforts that are designed to meet these
expectations. All interactions should be seamless to the customer.
To take connectivity a step further, processes not only need to be
customer-focused and internally connected, they also need to be coordinated with
external stakeholders such as third-party vendors that interact with customers
and handle customer information. This added dimension of connectivity assists
all of the touchpoints, internal and external, in being more responsive to
customer needs.
Integrated Communications With Customers
The connectivity described above establishes the foundation for integrated
communications with customers. Companies should demonstrate to customers that
they understand their needs and preferences by providing them with customized
solutions. A firm should not send information to customers about every product
in its product line using uncoordinated messaging that confuses the customer as
to the value that it provides.
Communications, campaigns and loyalty programs should be:
- Integrated and coordinated across all applicable channels, such as
catalog, retail, web, sales and customer service
- Executed using the customer's preferred channel
- Clear and consistent showing the benefits to the customer, meeting
individual needs
Communications should also enable the company to learn more about the
customer over time so that it acts upon that information to better meet customer
needs in the future. This is what is known as building "learning relationships"
with customers, a fundamental CRM concept. A feedback loop must be built into
the process so that the company can continually learn more about customers and
their needs in order to improve the relevancy of its communications and offering
in the future.
Eliminate Work, Don't Create It
Processes should be designed so that they eliminate work for the customer and
for the company, rather than create it. Ideally internal and external
stakeholder, including customers, should be involved in process design so that
the new processes and tools make their jobs and lives easier.
In many cases, both in B2C and B2B, there are customers who prefer
"Do-It-Yourself" or self-service options. In these cases, processes can be
designed so that they are convenient for the customer, while also
eliminating employee tasks that may in fact be the most repetitive or least
rewarding aspects of a position. For example, it may be more convenient for a
customer to find out a store's hours via its Web site rather than talking to a
representative. In developing these types of processes, with an understanding of
customer needs and preferences, the company provides value to the customer,
while deploying a cost effective solution.
When reviewing potential solutions that could increase efficiencies for the
company, it is important to continually refer to the customer needs and value
information to ensure that the processes being developed are, above all, the
solutions for the customer.
4- Adoption
This section discusses the appropriate steps to ensure adoption of the CRM
vision, strategy, customer insight and processes. According to a survey
conducted by CRM Forum, when asked what went wrong with their CRM projects, 4
percent of the managers surveyed cited technology problems, 1 percent cited bad
advice, but 87 percent said the failure was due to a lack of adequate change
management. Change management involves a comprehensive approach to foster
adoption including organizational design, training, incentives and measurement.
A change management plan to align behavior with the CRM strategy must be
designed with the same degree of precision and importance as a technical project
management plan.
Please see The Change Management Approach
Customer-focused organizational design
A key step to adoption is to implement organizational changes required to
align roles and responsibilities with the CRM strategy. The necessary
organizational adjustments will differ according to a company's current
structure; however the following points illustrate adjustments that may need to
be made.
Essentially there are three main organizational areas that may need
realignment to focus on the customer: Managing by Customer Equity, Channel
Management and Product Management. As depicted in the diagram, (Please see Customer/Channel/Product
Management Integration) , these three areas hold distinct and integrated
roles in the execution of a CRM initiative.
Managing by Customer Equity - Our prior discussion of customer
information underscored the importance of MCE. In some companies, this function
may be known as customer segment management. For CRM to take hold in an
organization, clear responsibilities and resources must be established for
Customer Equity Managers who understand the needs and value of customers in
their portfolios. Then, they must develop customized treatments to meet customer
needs. This may require creating a new department or revising the roles of an
existing department to ensure that this function is well positioned in the
organization.
Gartner's strategic planning assumption is that through 2006, 75 percent of
companies will still be organized primarily around product lines vs. customer
segments, causing customer satisfaction to remain less than optimal.
Additionally through 2006, 75 percent of organizations will describe themselves
as in the middle of a CRM transformation, although only 25 percent will have
organized around customers and customer segments (CRM Business Transformation:
More than Just Technology, Gartner Research, June 2003). A lack of organization
around customers or customer segments, but only by product or function, impedes
a company's ability to maintain a customer-centric view.
Channel Management - The channels, such as Web, retail, catalog and
customer service are the frontline to the customers, and therefore must be
organized to deliver customer-focused solutions utilizing the most effective and
efficient processes. The channels must be aligned with the product and customer
equity managers, particularly so that customer needs information is conveyed and
updated, which in turn should drive product development and messaging.
Product Management - In some cases, product management is the area
requiring the biggest shift, not necessarily in organization, but in mindset.
Depending on the company culture, criteria other than customer needs may be
driving product design. For example, idea from the CEO or simply the desire to
be cutting-edge may be the greatest influence on product development as opposed
to customer needs and preferences.
Where organizational changes are required, a company should not change the
structure too quickly but try out the customer-focused adjustments in one
department or function first, then expand to other business units. Additionally,
the three areas described: MCE, channel and product management, must all focus
on the customer and realize that one group or touchpoint does not "own" the the
customer. Instead, the company must work as one entity to understand customer
needs and value, develop customized solutions and deliver positive seamless
customer experiences to build profitable customer relationships.
Change Management Requirements Defined by Business Unit
There are many facets to change management, all of which must be addressed to
increase the adoption levels of the CRM strategy and processes. To ignore the
need to manage change and the need to establish the appropriate training and
incentives required to create acceptance is a recipe for failure.Employees will
not simply adopt whatever strategy or processes are presented if the benefits to
them and to customers are not clear. Employees in all companies have undergone
significant changes, reorganizations and "the next big thing" numerous times. In
general, they are "change weary" and "change wary." Companies are asking
employees to absorb change at an unprecedented pace. Therefore, it is even more
critical to teach employees to be change-adept and implement sound practices
In knowing their particular situation, function and past experiences, each
business unit within an enterprise should determine their specific change
management requirements and the appropriate approach to their business unit
(BU). The BU should evaluate current skills and capabilities and gaps between
those and the new skills and capabilities required to implement the new customer
strategies. This assessment will enable the business unit to define their
training needs, incentives and rewards that would encourage and reinforce
the new customer-focused behavior. Gartner asserts that through 2005, CRM
initiatives that aggressively leverage first-line managers for communication,
training, coaching and assessment will increase CRM adoption by 75 percent while
reducing transition time by 50 percent (CRM Business Transformation: More than
Just Technology, Gartner Research, June 2003).
A well-designed incentive program with a variety of rewards and recognition
is extremely important to motivate employees to implement the CRM strategy.
Incentive programs should include rewards that can be given by management, peers
and customers and include both team and individual rewards. Ideally, the
compensation program should also be revamped to encourage significant changes in
employee behavior in alignment with the new CRM strategy, objectives, processes
and metrics. Gartner's strategic planning assumption is that through 2005, CRM
initiatives that align compensation with individual, enterprise and customer
metrics will increase adoption rates by 50 percent. (CRM Business
Transformation: More than Just Technology, Gartner Research, June 2003).
Additionally, by establishing a cross-functional CRM team from the outset,
each business unit should have had opportunities to provide input throughout the
strategy and process development stages, which should also assist in creating a
greater understanding and acceptance of the change by the business unit.
Change must be incremental
In order for change to be embraced, it must be implemented in an incremental
fashion. The new strategy must first "prove itself," before it can be rolled
out. To create a movement for change, the company should also identify and
strengthen the roles of early adopters/ change agents who will be key players to
cascade a smooth rollout.
To foster change, the impact of CRM strategies and initiatives must first be
demonstrated through initial "Quick-Hits." Quick hits



