El sistema de archivos es un elemento esencial de un sistema distribuido
Su tarea fundamental es almacenar los programas y datos y tenerlos disponibles
cuando sean necesarios. Nos centraremos en analizar los aspectos que los
diferencían de los sistemas de archivos centralizados.
Es importante distinguir entre los conceptos de servicio de archivos y servidor de archivos.
El servicio de archivos especifica la interfaz del sistema de archivos con los clientes. Describe las primitivas disponibles, los parámetros que utilizan y las acciones que llevan a cabo.
Un servidor de archivos es un proceso que se ejecuta en alguna máquina
y ayuda a implantar el servicio de archivos. Un sistema puede tener uno
o varios servidores de archivos, pero los clientes no deben conocer el
número de servidores de archivos, su posición o función.
Todo lo que saben es que, al solicitar un servicio, éste se lleva
a cabo de alguna manera.
Generalmente un sistema de archivos distribuidos (DFS) tiene dos
componentes: el servicio de archivos y el servicio de directorios.
Un archivo es una secuencia de bytes con
algún significado especial para el usuario.
Un archivo puede tener atributos, que son partes de información relativas a él, pero que no son parte del archivo propiamente dicho (propietario, tamaño, fecha de creación, permisos de acceso, etc.). Generalmente el servicio de archivos proporciona primitivas para leer y escribir alguno de los atributos.
En algunos sistemas de archivos se maneja el concepto de inmutabilidad, que consiste en que un archivo sólo puede ser creado y leído, pero no modificado. Esto facilita el soporte del ocultamiento y la replicación de archivos, puesto que se eliminan los problemas de actualización de copias remotas.
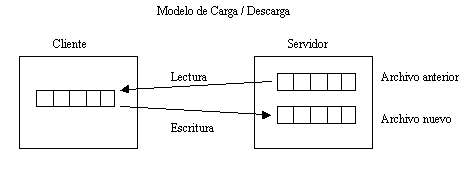
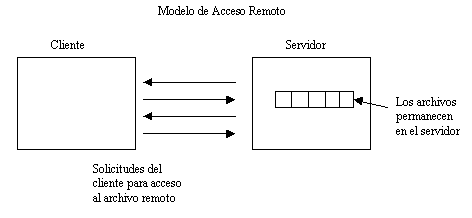
Los servicios de archivos se pueden dividir en dos tipos, según
si soportan un modelo de carga/descarga o un modelo de acceso remoto.
En el modelo de carga/descarga, el servicio de archivos proporciona dos operaciones principales: lectura de archivo y escritura del mismo. La lectura transfiere todo el archivo de los servidores de archivos al cliente solicitante. La escritura transfiere todo el archivo del cliente de regreso al servidor. El modelo conceptual es el traslado de archivos completos en alguna de las direcciones. La interfaz es sencilla, y la transferencia completa de archivos es muy eficiente.
El modelo de acceso remoto se proporciona un gran número de operaciones para abrir y cerrar archivos, leer y escribir partes de archivos, moverse a través de un archivo (lseek), etc. Aquí el sistema de archivos se ejecuta en los servidores y nunca se trasladan los archivos a los clientes. Su ventaja es que no necesita mucho espacio en los clientes y la cantidad de información transferida es mínima.
El servicio de directorios proporciona las operaciones para crear,
eliminar directorios, nombrar o cambiar archivos dentro de directorios,
y mover archivos de un directorio a otro. Los directorios pueden contener
subdirectorios y éstos también pueden contener subdirectorios,
lo que se conoce como sistema jerárquico de archivos o árbol
de directorios.
En ciertos sistemas es posible crear enlaces o apuntadores a un directorio
arbitrario desde cualquier directorio, con lo que se pueden crear grafos
arbitrarios, que son más poderosos que los árboles. La distinción
entre árboles y grafos es de particular importancia en sistemas
distribuidos.
Ejemplo de árbol de directorios y grafo de directorios
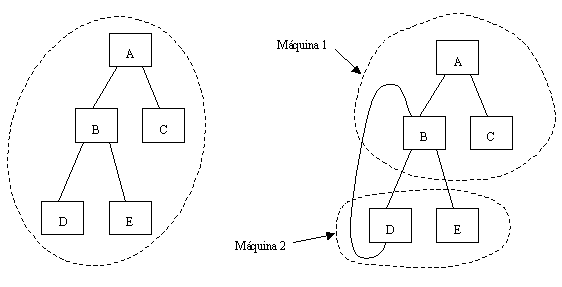
En la gráfica anterior se muestra en ejemplo de cómo se pueden tener directorios que abarquen más de un servidor de archivos.
Cada servidor tiene una estructura de directorios local que se enlaza con la estructura de otro servidor. Es posible que cada servidor vea globalmente una estructura distinta y este es un problema si se desea que los clientes vean una referencia a los archivos del tipo //servidor/ruta, ya que debe reconocerse que el directorio raíz está en alguno de los servidores en particular, y la estructura de directorios que éste ve es la que verán todos los clientes.
Uno de los principales problemas de este tipo de estructura es que no se tiene una transparencia referencial o de nombres, ya que es necesario conocer el nombre del servidor para poder alcanzar un archivo, lo que impide que el servidor pueda migrarse dinámicamente.
Generalmente se puede atacar este problema con tres formas diferentes
de nombrar los archivos y directorios:
Los dos primeros son fáciles de implantar en sistemas centralizados
que se convierten en distribuidos. El tercero es la manera ideal en que
se comporta un sistema distribuido
Uno de los principales problemas al manejar archivos en forma distribuida
se refiere a cómo se reflejan los eventos de lectura y escritura
en un archivo a todos los clientes (semántica de la lectura y escritura).
Podemos considerar cuatro formas básicas de compartir archivos en
un sistema distribuido:
| Semántica de UNIX | Cada operación en un archivo es visible a todos los procesos de manera instantánea |
| Semántica de sesión | Ningún cambio es visible a otros procesos hasta que el archivo se cierra |
| Archivos inmutables | No existen actualizaciones; es más fácil compartir y replicar |
| Transacciones atómicas | Todos los cambios tienen la propiedad de todo o nada |
Para facilitar el desempeño en el acceso a los archivos distribuidos
pueden utilizarse técnicas que permitan ocultar los retrasos normales
en la transferencia de archivos entre las diferentes máquinas. Este
ocultamiento se logra con el uso de cachés en sus diferentes formas.
Existen cuatro lugares donde se pueden almacenar archivos o partes de
archivos: El disco del servidor, la memoria principal del servidor, el
disco del cliente o la memoria principal del cliente:

Características de cada opción:
| Disco del servidor | No hace falta mover los archivos. Pobre desempeño |
| Memoria del servidor | Mejor desempeño. Poco espacio. Lentitud en transferencia |
| Disco del cliente | Mejor desempeño que los anteriores. Requiere algoritmos de control
de versiones. Malo si hay muchas actualizaciones remotas.
|
| Memoria del cliente | El mejor desempeño. Poca memoria. Requiere algoritmos de control de cache. |