EEL5764: Computer Architecture
Fall 2001
Project Report
SIMULATION AND ANALYSIS OF THE
JAVA PLATFORM
Suman Srinivasan
K.S.Ranganath
Simulation and Analysis of the Java platform
Suman Srinivasan, K.S.Ranganath
Abstract
In our paper, we simulate the Java instruction set architecture in order to learn more about the Java platform at its most basic level. We also implement an improvement to the platform at the instruction level, called instruction folding. We simulate and quantitatively analyze three folding strategies – 2-folding, 3-folding and 4-folding. Our simulations show that in the best case, 71% of the stack operations can be eliminated, and the speedup in this case was 93%.
1. Introduction
The Java platform has attained prominence over the recent years. It has claimed a foothold in devices ranging from the smallest mobile phone to the largest mainframes. The Java Consumer and Embedded technologies and products let you write code for small devices that are big on functionality but short on resources. A highly optimized Java runtime environment targets a wide range of consumer products, including pagers, cellular phones, screen phones, digital set-top boxes and car navigation systems. Hence a study of its instruction set and improvements made to it will be very useful at this point of time.
A Java stack machine has the advantage of small code size - 1.8 bytes per instruction on an average, as compared to the other RISC or CISC machines. However, due to the limitation of accessing a unique operand stack, all the succeeding ALU or other stack-related operation must wait and depend on the previous load or written back data o be stored onto the stack. This severely limits the instruction level parallelism. A way of omitting the unnecessary loads or write back was proposed by the Sun Microelectronics Inc. in their Pico Java architecture[i] – the folding technique. We study, simulate and analyze the use of this technique.
2. Introduction to the Java Architecture and Instruction Folding
Our study of the Java architecture was based on the open “Java Virtual Machine Specification”[ii] maintained by Sun Microsystems.
Instruction
Set
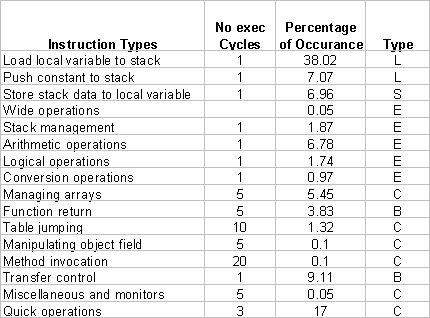
Sun Microelectronics’ Java Platform contains about 230 bytecode instructions that are classified into 17 types. These instruction types, estimated execution cycle counts (corresponding to typical microprocessors) and their dynamic distribution are listed here[S1].
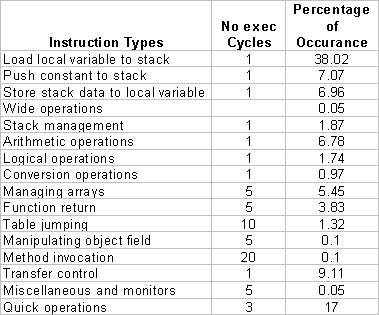
From the table, one can see that load local variable and push constant into stack accounts for up to 45% of all instructions. Most of these data are consumed by ALU operations (6.78%) written back into local variable (6.96%) or consumed by complex instructions like method invocation and quick operations. If we can fold these instructions together such that the stack push and pop operation can be omitted, the performance can be improved dramatically.
Instruction Folding
Instruction folding allows many instructions to be combined for execution in a single clock cycle, improving the performance of all types of code. This is very similar to multi-issue, except that the instructions are not actually issued. What actually occurs is that redundant operations are eliminated. This is particularly useful in a stack-based architecture like Java, where there are bound to be a lot of redundant data operations.
For example, suppose a program has the code shown in the table:

With stack operations folding, the source address of I1 and I2 are assigned to the source address of I3 and the destination address of I4 is assigned to the destination address of I3. The four stack operations are then folded with I3 being the primary instruction and the others the auxiliary instructions of the folding group respectively. The three auxiliary instructions I1, I2 and I4 disappear after D2 stage, but the primary instruction I3 is expanded to have direct operand sources and destination address, instead of having to fetch from and write back to operand stack.
3. Simulation – Our Objects
Our simulation is written in C. It simulates both the code, and also the execution arithmetic, logical, branch and jump instructions. The load variable and operand stacks are simulated using arrays of appropriate data type. The number of clock cycles of execution for all the bytecode instructions is calculated based on the table shown and the assumption provided here under. The simulator uses this raw data for calculating various performance parameters and gives these results directly.
The bytecodes are read from the corresponding file that is produced when the original Java code is compiled. The execution of the code is done based upon the action that is to be taken for the respective bytecode.
Java Machine Model
In our simulation, we have designed a Java processor with the following features:
- In order to enhance its performance, a hardware stack cache is commonly provided to store the data of each execution method.
- Method codes are executed in the execution unit, or emulated with the micro-ROM.
- Out-of-bound local variables are accessed through the load/store unit.
- We assume that all memory accesses are hits.
Description of Execution Stages
We designed the execution stages of the Java processor with the following stages:
- Instruction Fetch:
- Fetch instructions from the instruction cache and then store them into instruction fetch buffer.
- Instruction Decode1:
- Identify instruction boundaries and decode instructions.
- Check types of instructions and store instructions into Fold Buffer.
- Instruction Decode2:
- Folding rules check and memory access check.
- Assign source address and destination address of the auxiliary instructions to the primary instruction to yield a single folded instruction if possible, and store resulted instruction in the Folded instruction Buffer.
- Operand Fetch:
- Fetch on chip operands from Constant Register (CR), Operand Stack (OS), and Local Variable (LV).
- Execution, Address Generation & Memory Access:
- Execute ALU related bytecode instructions or calculate effective address or access memory access.
- Write result into execution result buffer.
- Write Back:
- Write the data in the execution result buffer back to Operand Stack or Local Variable.
- Exception check.
In this subsection we assume that there are enough READ and WRITE ports of Stack Cache and Local Variable in this machine model, so that there is no resource contention upon concurrent read or write.
Folding Strategies
A folding strategy is developed by analyzing the program trace files to find out all possible folding combinations. Among these combinations, we can find that instructions play three kinds of roles in instruction folding: Producer, Consumer and Operator. The producer instructions push data from on-chip local variable memory or constant registers onto operand stack in a single cycle. The consumer instructions pop data from operand stack and store the data onto on-chip local variable memory. The operator instructions pop data from operand stack, execute some kind of operation and push the result back to operand stack.
After analyzing all possible combinations, we find that the folding occurs when some producer instructions produce the data and one or more consumer instructions consume it, or some producer instructions produce the data and the data is processed by one operator instruction, then the result is written back to stack or consumed by one or more consumer instructions.
As shown in table we classify the bytecode instructions into five types according to the role of each instruction in the folding group. In this table we find that the operator consists of E, B and C type instructions. The reason is that consumer instructions can be folded with E and C type instruction but not with B type instructions. The role played by each instruction in the folding strategy is listed in Appendix C.
|
Roles in Folding |
Types |
Description |
Percentages |
|
Producer |
L |
Load from L.V/Push Constant |
45.09 |
|
Consumer |
S |
Store to L.V |
6.96 |
|
Operator |
E |
Execution Unit Instruction |
11.41 |
|
|
B |
Branch/Control Transfer |
12.94 |
|
|
C |
Complex/Micro-ROM |
24.02 |
After analyzing all of the foldable patterns, we choose some foldable patterns with higher occurrence frequency. With these foldable patterns, we find that these patterns consist of 2 to 4 bytecode instructions. Hence to gain better performance, the folding logic in decoder design may support up to 4 instructions decoding simultaneously in a cycle. On the other hand, if the cost is the primary consideration, the 2 folding technique may be more suitable. So we propose three folding strategies with the folding instructions from 2 to 4 bytecode instructions respectively.
2-foldable: folds 2 bytecode instructions. The most frequent foldable patterns are shown below:
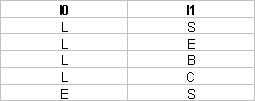
These foldable patterns are of three combinations: Producer and Consumer; Producer and Operator; and Operator and Consumer. The following procedure describes the decision flow of determining whether any two instructions match 2-foldable or not.
- If I0 and I1 match one of the foldable patterns shown above, then both of them are combined and issued as a single instruction.
- If I0 and I1 cannot match one of the foldable patterns as shown, then I0 is issued and executed as a standard Java machine instruction without folding. I1 then becomes the new I0 in the next clock cycle and its checked again with the succeeding instructions.
3-foldable: folds up to 3 bytecode instructions. The most frequent foldable patterns are shown below:
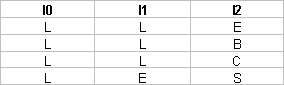
These foldable patterns are of two combinations: Producers and Operator; and Producer, Operator and Consumer. The following procedure describes the decision flow of determining whether any three instructions match 3-foldable or not.
1. If I0, I1 and I2 match one of the foldable patterns shown above, then both of them are combined and issued as a single instruction.
2. If I0, I1 and I2 cannot match one of the foldable patterns as shown, then I0 is issued and executed as a standard Java machine instruction without folding. I0 and I1 are checked using 2-foldable strategy.
4-foldable: folds up to 4 bytecode instructions. The most frequent foldable pattern is shown below:
![]()
This foldable pattern is of the combination: Producers, Operator and Consumer. The following procedure describes the decision flow of determining whether any three instructions match 4-foldable or not.
1. If I0, I1, I2 and I3 match the foldable patterns shown above, then both of them are combined and issued as a single instruction.
2. If I0, I1, I2 and I3 cannot match one of the foldable patterns as shown, then I0 is issued and executed as a standard Java machine instruction without folding. I0, I1 and I2 are checked using 3-foldable strategy.
We can see that the 4-foldable strategy can combine up to four instructions into one instruction if these instructions match one of the foldable patterns. Of course, to decode up to four bytecode instructions at the same time is more complex than decoding two instructions.
4. Performance Analysis
Performance of Folding
We have compared the performance as obtained by the authors of the original paper against the performance we have obtained with our simulation. The performance obtained from our simulation comes close in character to the performance obtained by the authors in their paper.
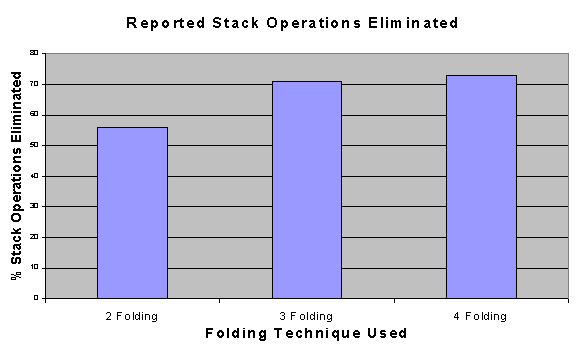
Eliminated Stack Operations Eliminated
The following figure shows the percentage of stack operations eliminated with respect to total stack operations, as obtained by the authors of the instruction folding technique in their paper.
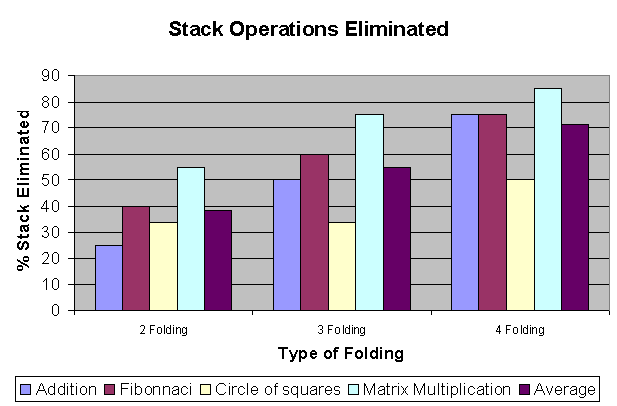
The following chart shows the performance for stack operations elimination we
obtained from our simulation.
As can be seen, the average percentage of stack elimination is 36% for 2-folding, 55% for the 3-folding, 71% for 4-folding.
As the size of the program increases the number of stack operations eliminated increases because the possibility of finding a matching pattern increases. But the interesting data here corresponds to the data collected by running the program for simple addition of two numbers and the program to find consecutive series of perfect squares. The addition program though small fits perfectly to the 4-folding pattern and hence the number of stack operations eliminated is comparable to large programs like matrix multiplication. At the same time, the program size of “circle of squares” is comparable to the program for generating fibonnaci series but its performance is not as good. In fact there are not many real-world code sequences that fit into the 3-folding pattern.
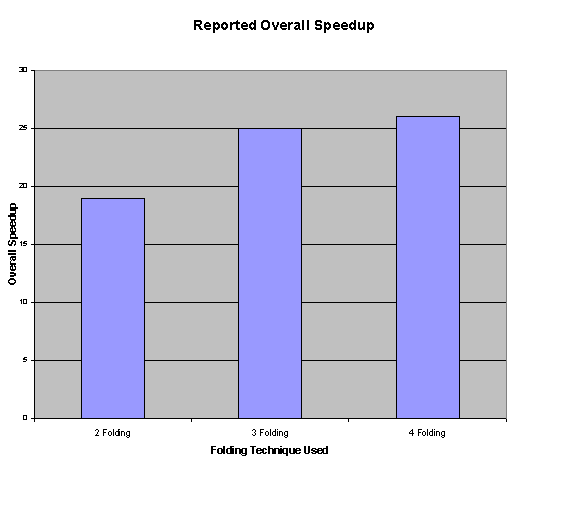
Speedup
The diagram on the side shows the total speedup performance as obtained by the authors of the instruction folding technique in their paper.
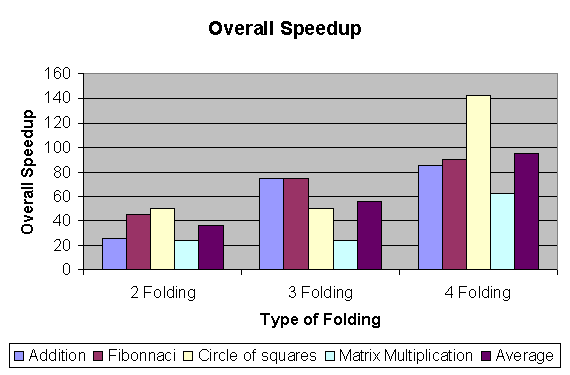
The following chart shows the speedup we obtained from our simulation:
We notice that the percentage of stack operations eliminated does not truly reflect the performance gain. This is because the stack operations are actually the main overhead to a program and decreasing the number of stack accesses improves performance of the system. This is the reason for the large jump in speedup for the “circle of squares” despite the fact that the percentage of stack operations eliminated is very less. The speedups with respect to stack operations maybe a valuable performance parameter in such situation for more accurate prediction.
5. Conclusion
In this project, we studied, analyzed and improved the performance of the Java architecture by implementing instruction folding. In doing so, we have obtained substantial benefits in eliminating stack operations and thus speeding up the program execution. As we observed from our simulation, the stack operations eliminated in 2, 3 and 4 folding translate to execution speedup. By introducing pipelining between folding groups the performance can be made better. This can form the future line of study for Java enthusiasts.
Our study assumed a 100% hit rate and a fast L1 cache access. There is scope for more accurate study by taking into account miss rates and miss penalties during memory accesses and by including pipeline stalls (if pipelining is used).
Thus, in our study, we presented the architecture of the Java platform, and a theoretical study of instruction folding. We also simulated the Java architecture, and studied its performance without instruction folding, with 2 folding, 3 folding, and 4 folding. As a consequence of this, we have expanded our understanding of the Java platform and instruction folding.
Our humble opinion is that the instruction folding technique can be effectively used in Java processors at small extra cost by taking advantage of the limitation that has plagued stack architectures since their very beginning: high frequency of instruction level dependencies. Instruction folding is surely to stay and will form the basis of further developments in stack architecture.
5. Appendix A - Hardware and Specifications of the Java platform
The hardware of the Java Platform can
be divided into four basic parts: the registers, the stack, the
garbage-collected heap, and the method area. The size of an address in the JVM
is 32 bits. The JVM can, therefore, address up to 4 gigabytes (2 to the power
of 32) of memory. The stack, the garbage-collected heap, and the method area
reside somewhere within the 4 gigabytes of addressable memory.
A word in the Java Virtual Machine is
32 bits. The JVM has a small number of primitive data types: byte (8 bits),
short (16 bits), int (32 bits), long (64 bits), float (32 bits), double (64
bits), and char (16 bits). One other primitive type is the object handle, which
is a 32-bit address that refers to an object on the heap.
The JVM has a program counter and
three registers that manage the stack. It has few registers because the
bytecode instructions of the JVM operate primarily on the stack. This
stack-oriented design helps keep the JVM's instruction set and implementation
small.
The JVM uses the program counter,
or pc register, to keep track of where in memory it should be executing
instructions. The other three registers -- optop register, frame register, and
vars register -- point to various parts of the stack frame of the currently
executing method. The stack frame of an executing method holds the state (local
variables, intermediate results of calculations, etc.) for a particular
invocation of the method.
The method area is where the bytecodes
reside. The program counter is used to keep track of the thread of execution.
After a bytecode instruction has been executed, the program counter will
contain the address of the next instruction to execute.
The method area, because it contains
bytecodes, is aligned on byte boundaries. The stack and garbage-collected heap
are aligned on word (32-bit) boundaries.
The Java stack is used to store
parameters for and results of bytecode instructions, to pass parameters to and
return values from methods, and to keep the state of each method invocation.
The state of a method invocation is called its stack frame.
There are three sections in a Java
stack frame: the local variables, the execution environment, and the operand
stack. The local variable section contains all the local variables being used
by the current method invocation. The execution environment section is used to
maintain the operations of the stack itself. The operand stack is used as a
workspace by bytecode instructions. It is here that the parameters for bytecode
instructions are placed, and results of bytecode instructions are found.
The execution environment is usually
sandwiched between the local variables and the operand stack. The operand stack
of the currently executing method is always the topmost stack section and the
optop register therefore always points to the top of the entire Java stack.
The heap is where the objects of a
Java program live. Any time you allocate memory with the new
operator, that memory comes from the heap. The Java language doesn't allow you
to free allocated memory directly. Instead, the runtime environment keeps track
of the references to each object on the heap, and automatically frees the
memory occupied by objects that are no longer referenced -- a process called
garbage collection.
Appendix B - Glossary
Here we give definitions of Stack Operations Folding, Stack Operation Folding Group, Primary Instruction and Auxiliary Instruction as follows.
Stack Operation Folding – The ability to detect some related contiguous instructions in the instruction flow of a stack machine, and execute them collectively in some way like a single compound instruction.
Stack Operation Folding Group – A collection of instructions that can be folded together.
Primary Instruction – The instruction in a folding group that consumes or produces data, that transfers control, that invokes micro program, or if none of the above, any load or store instruction.
Auxiliary Instruction – An instruction that is not a primary instruction in the folding group.
Appendix C
List of instructions and it’s role-played in the instruction folding