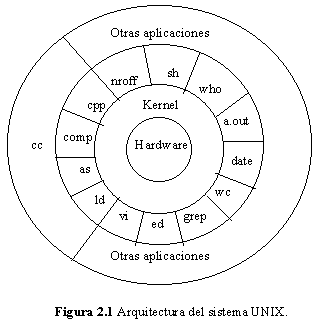
1. Estructura del sistema
Los programas como el shell y los editores (ed y vi) mostrados en la capa siguiente interactúa con el kernel invocando un conjunto bien definido de llamadas al sistema. Las llamadas al sistema ordenan al kernel realizar varias operaciones para el programa que llama e intercambiar datos entre el kernel y el programa. Varios programas mostrados en la figura 1 están en configuraciones del sistema estándares y son conocidos como comandos, pero los programas de usuario deben estar también en esta capa, indicándose con el nombre a.out, el nombre estándar para los archivos ejecutables producidos por el compilador de C. Otros programas de aplicaciones pueden construirse por encima del nivel bajo de programas, por eso la existencia de la capa más exterior en la figura 1. Por ejemplo, el compilador de C estándar, cc, está en el nivel más exterior de la figura: invoca al preprocesador de C, compilador, ensamblador y cargador, siendo todos ellos programas del nivel inferior. Aunque la figura muestra una jerarquía a dos niveles de programas de aplicación, los usuarios pueden extender la jerarquía a tantos niveles como sea apropiado. En realidad, el estilo de programación favorecida por UNIX estimula la combinación de programas existentes para realizar una tarea.
Muchos programas y subsistemas de aplicación que proporcionan una visión de alto nivel del sistema tales como el shell, editores, SCCS (Source Code Control System) y los paquetes de documentación, están convirtiéndose gradualmente en sinónimos con el nombre de "Sistema UNIX". Sin embargo, todos ellos usan servicios de menor nivel suministrados finalmente por el kernel, y se aprovechan de estos servicios a través del conjunto de llamadas al sistema. Hay alrededor de 64 llamadas al sistema en System V, de las cuales unas 32 son usadas frecuentemente. Tienen opciones simples que las hacen fáciles de usar pero proveen al usuario de gran poder. El conjunto de llamadas al sistema y los algoritmos internos en los que se implementan forman el cuerpo del kernel. En resumen, el kernel suministra y define los servicios con los que cuentan todas las aplicaciones del UNIX.
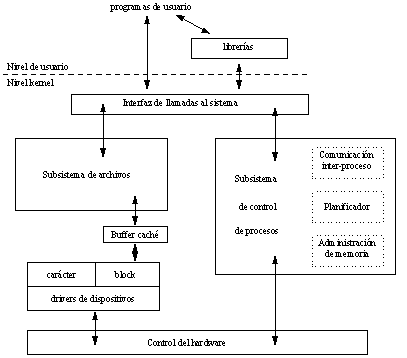
2.1 Organización de la información:
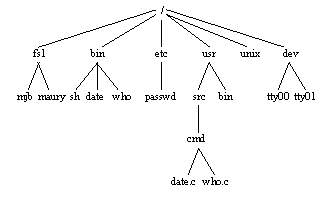
Sin embargo en UNIX no se utiliza un único directorio para apuntar a todos los archivos del sistema, sino que se crea una estructura jerárquica de directorios conocida como estructura en árbol. Se muestra un ejemplo de esta estructura jerárquica en la figura 3.
Todos los archivos UNIX son tratados como una simple secuencia de bytes (caracteres), comenzando en el primer byte del archivo y terminando con el último. Un byte en concreto dentro del archivo, es identificado por la posición relativa que ocupe en el archivo. La organización de los archivos en registros o bloques de una longitud fija, corresponde a la forma tradicional de organización de los datos en el disco. El UNIX protege específicamente al usuario del concepto de registros o bloques. En su lugar, el UNIX puede permitir que el usuario divida al archivo en registros, de acuerdo a un byte o conjunto de bytes especiales. Los programas son libres para organizar sus archivos, con independencia de la forma en que los datos estén almacenados en el disco.
Cada registro en el directorio tiene una longitud de 16 bytes de los que:
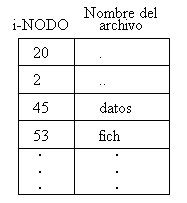
Es importante no perder la idea de que, aparte de otros componentes que se verán más adelante, cada sistema de archivos dispondrá de su propia tabla de i-nodos que apuntarán a los bloques de datos de los archivos y directorios contenidos en él.
El sistema de archivos que contiene el directorio raíz (normalmente el primer disco o la primera partición del primer disco en su caso) es el principal. En principio, cuando se carga el sistema operativo, la única parte accesible de la estructura es la contenida en el file system principal. Para poder acceder a la información contenida en los restantes sistemas de operación es necesario realizar una operación denominada "montaje". Esta operación consiste en enlazar cada sistema de archivos con directorios vacíos de la estructura principal. A partir de ese momento, los archivos y directorios de los sistemas de archivos secundarios figurarán dentro de la estructura, colgando del directorio de montaje.
Una vez montado todos los sistemas de archivos, la estructura es única, por lo que el disco o la partición en que esté físicamente un determinado archivo, es transparente para el usuario. La función de montaje y desmontaje de los sistemas de archivo es, normalmente, realizada por el administrador del sistema.
El sistema de archivos, o file system, de UNIX está caracterizado por:
Cada sistema de archivos consta fundamentalmente de las siguientes partes:
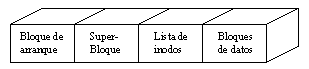
Los directorios y los archivos ordinarios han sido ya comentados. Los archivos especiales se verán más adelante.
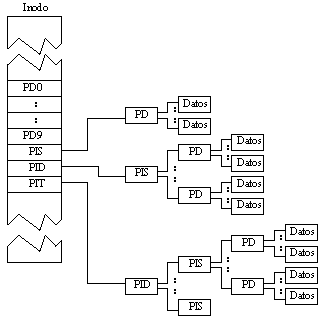
Esta forma de acceder físicamente a los bloques de datos puede parecer más compleja que la utilizada en otros sistemas operativos en los que se accede directamente con la información existente en el directorio, sin necesidad de tablas de i-nodos ni nada por el estilo, sin embargo presenta algunas ventajas. Por ejemplo, si en un directorio se ańade una entrada con un nombre de archivo cualquiera, pero con un i-number ya utilizado en otro directorio, se podrá acceder a los mismos bloques de datos desde los dos directorios e incluso con diferente nombres de archivos. En este caso se dice que existe un enlace entre ellos.
El UNIX mantiene la siguiente información para cada archivo; en la tabla de i-nodos:

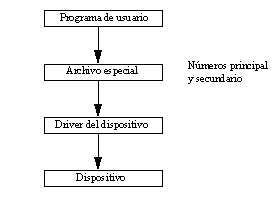
Cada tipo de dispositivo tiene un controlador responsable de comunicarse con este dispositivo. Dentro del sistema hay una tabla que apunta a los diferentes controladores de los dispositivos. Todos los dispositivos son tratados como archivos. Existen archivos especiales para cada línea de comunicaciones, disco, unidad de cinta magnética, memoria principal, etc. Estos archivos en realidad están vacíos. Tienen por misión asociar entre sí los dispositivos y sus respectivos drivers. El sistema emplea dos números enteros, denominados número principal (14 bits) y número secundario (18 bits) y almacenados en el i-nodo del archivo, para acceder al dispositivo asociado.
El número principal identifica una clase de dispositivo (en realidad identifica al driver de dicha clase como pueden ser terminales, impresoras, discos, etc.) y el número secundario identifica a un elemento de dicha clase (un terminal específico, un disco concreto, ...).
Las ventajas de tratar las unidades de entrada/salida de esta forma son:
| Contiene muchos de los archivos ejecutables correspondientes a los comandos. | |
| Contiene también ejecutables del mismo tipo. | |
| Contiene librerías de lenguaje C. Muy útil para los programadores. | |
| Contiene archivos especiales asociados con dispositivos de entrada/salida. | |
| Contiene entre otros, archivos ejecutables usados por el administrador. | |
| Utilizado para crear archivos temporales y de pruebas. Es borrado periódicamente por el sistema de forma automática. |
Cada archivo y directorio creado en UNIX tiene un propietario, normalmente la persona que lo ha creado. Ese propietario pertenece además a un grupo de usuarios. El propietario del archivo o directorio puede asignar varios tipos de permisos, para permitir o denegar el acceso al archivo o directorio. Los tipos de permisos de acceso son:
| Lectura (r) | Permitiría su acceso para lectura. |
| Escritura (w) | Permitiría su actualización. |
| Ejecución (x) | Permite que el archivo pueda ser usado como comando shell. |
Directorios:
| Lectura (r) | Permite ver su contenido. |
| Escritura (w) | Permite crear o borrar archivos bajo él. |
| Ejecución (x) | Permite accederse a él. |
Cada usuario puede especificar el permiso de acceso a sus
archivos, seleccionando la adecuada combinación de tipos de permisos, con el fin de permitir o
denegar el acceso a tres niveles de usuarios (propietario, usuarios de su grupo, y el resto de
usuarios).
3. Control de procesos
Generalmente, las llamadas al sistema permiten al usuario escribir programas que realicen sofisticadas operaciones, y como resultado, el kernel del sistema UNIX no contiene muchas funciones que son parte del "kernel" en otros sistemas. Estos programas, incluyendo compiladores y editores, son programas a nivel de usuario en el sistema UNIX. El principal ejemplo de estos programas es el shell, el intérprete de comandos que los usuarios ejecutan normalmente de entrar en el sistema.
El núcleo del sistema operativo UNIX conoce la existencia de un proceso a través de su bloque de control del proceso, donde se describe el proceso y su entorno, constituyendo un contexto consistente en:
Si congelamos el estado del procesador y del proceso que está en ejecución en un determinado momento, obtendríamos lo que se conoce como imagen estática del programa. En caso de producirse una interrupción o cambio de proceso, se almacena la imagen del que está en ejecución en ese mismo instante.
Cada proceso se reconoce dentro del sistema por un número que lo identifica unívocamente y que se conoce como Identificador del Proceso o PID.
Todos los procesos, excepto el proceso 0, son creados por otro proceso; es decir, el sistema de creación y gestión de procesos en UNIX es jerárquico.
El proceso que se genera con el PID 0 es un proceso especial creado en el momento de arrancar el sistema. A continuación se genera un proceso init que será el antecesor de todos los procesos que se generen en el sistema. A partir de aquí se generan tantos procesos como terminales existan (se dará una descripción más adelante).
Los procesos que atienden a los terminales crearan otros con el fin de identificar y controlar el acceso de los usuarios al sistema, los cuales, una vez que inicien la sesión, ejecutarán un proceso intérprete de comandos Shell que será el que genere el resto de programas solicitados por el usuario.
4. Servicios del sistema operativo
El kernel suministra estos servicios de una forma transparente al usuario. Por ejemplo, reconoce que un archivo dado es un archivo regular o un dispositivo, pero oculta la distinción a los procesos de usuario. De forma análoga, formatea los datos en un archivo para su almacenamiento interno, pero oculta el formato interno a los procesos de usuario, devolviendo un flujo de bytes.
5. Consideraciones sobre el hardware
Las diferencias entre los dos modos son:
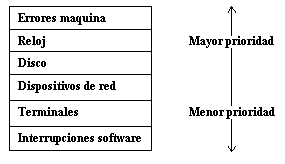
Una condición de excepción se refiere a eventos inesperados causados por un proceso, como un direccionamiento ilegal a memoria, ejecución de instrucciones privilegiadas, división por cero, etc. Son distintas de las interrupciones, las cuales están causadas por eventos externos al proceso. Las excepciones suceden en mitad de la ejecución de una instrucción y el sistema intenta restaurar la instrucción después de manejar la excepción; las interrupciones suceden entre la ejecución de dos instrucciones y el sistema continúa con la siguiente instrucción después de atender la interrupción. El sistema UNIX usa un mecanismo para manejar interrupciones y condiciones de excepción.
El kernel permanentemente reside en la memoria principal al igual que lo hace el proceso que se está ejecutando actualmente. Cuando se compila un programa, el compilador genera una serie de direcciones en el programa que representan direcciones de variables y estructuras de datos o las direcciones de instrucciones tales como las funciones. El compilador genera las direcciones para una máquina virtual como si no se ejecutara ningún otro programa simultáneamente en la máquina real.
Cuando el programa está ejecutándose en la máquina, el kernel asigna espacio en la memoria principal para él, pero las direcciones virtuales generadas por el compilador no necesitan coincidir con las direcciones físicas que ocupan en la máquina. El kernel coordina con el hardware la conversión de las direcciones virtuales generadas por el compilador a las direcciones físicas de la máquina.