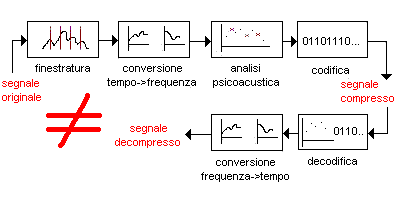
Gli algoritmi percettivi* sono molto più complessi e numerosi di quelli non percettivi,per cui in questo TC cercheremo di individuare le linee generali comuni. Le idee fondamentali che distinguono gli algoritmi percettivi da quelli non percettivi sono due: 1) siccome l'apparato uditivo umano sotto determinate condizioni non percepisce certe compo nenti di un segnale sonoro,è lecito pensare di eliminarle al fine di ridurre l'ingombro del segnale stesso,una volta digitalizzato 2) quando il segnale è stato privato di tutte le componenti superflue,si cerca di memorizzarlo usando la minor quantità possibile di informazione (bit) Per poter capire quali parti del segnale togliere,è conveniente "trasformare" il segnale digi talizzato,cioè portare la sequenza di campioni che descrive il segnale in una forma che metta in evidenza quali campioni possono essere cancellati senza che l'ascoltatore se ne accorga,e quali invece no. Nella prima parte del tutorial abbiamo visto che un segnale può essere rappresentato sia come variazione della sua intensità nel tempo,sia come somma di componenti sinusoidali,ciascuna con una propria ampiezza,frequenza e fase. La seconda rappresentazione prende il nome di SPETTRO,ed è molto più conveniente della prima proprio perchè permette di analizzare più facilmente il segnale al fine di "comprimerlo". Infatti l'analisi del segnale si basa sulla PSICOACUSTICA,scienza che studia le caratteristiche e i limiti del nostro apparato uditivo. Semplificando la questione al massimo**,la psicoacustica asserisce che una certa componente può essere percepita solo se il contributo dato dalla sua ampiezza e dalla sua frequenza è abbastan za "forte" da non essere "oscurato" dalle componenti vicine nel tempo e nello spazio. Possiamo rendere il concetto con un esempio banale. Pensiamo a quel che succede quando siamo alla stazione e parliamo ad un'altra persona nel mo mento in cui arriva un treno:improvvisamente l'altra persona non ci sente più,perchè le nostre parole vengono coperte dal fischio del treno,che è più acuto e intenso e si propaga nello stes so istante e luogo della nostra voce.In acustica,questo fenomeno prende il nome di mascheramen to. Allora,si capisce perchè la scomposizione di un segnale audio nelle sue componenti sia tanto utile;se si considera solo un piccolo intervallo temporale del segnale e se ne ricava lo spet tro,si potrà stabilire quali componenti possono essere eliminate per quel frammento di segnale perchè mascherate da componenti più acute e intense. In sostanza,questo è parte di quello che fa un encoder audio per comprimere un segnale digitale :lo suddivide in blocchi di campioni. Ciascun blocco di campioni nel tempo viene convertito in frequenza,dopodichè si applica l'anali si psicoacustica che consente di stabilire quali componenti possono essere eliminate senza per dere in qualità. Una volta che al blocco di campioni è stata applicata l'analisi psicoacustica,nel file prodotto dall'encoder verrà memorizzata la rappresentazione in frequenza del segnale***. La sequenza dei campioni audio visti in frequenza viene compressa usando l'algoritmo/i di ottimizzazione previsto/i dall'algoritmo di compressione****,e concatenata al flusso di bit che verrà memorizzato nel file. Pertanto,decomprimere il segnale significa decodificarne lo spettro e riconvertire i campioni nel dominio del tempo,come illustrato in questo specchietto riassuntivoAncora una volta è bene ribadire che,dato che gli algoritmi percettivi sono tutti lossy (mentre non è per forza vero il contrario) il segnale decompresso è DIVERSO dal segnale prima della compressione;gli algoritmi percettivi devono generare un segnale acusticamente indistinguibile dall'originale ma non garantiscono in alcun modo la ricostruzione del segnale di partenza. In appendice 1 indaghiamo sugli aspetti più importanti dell'algoritmo di compressione Vorbis I,mentre in appendice 2 vediamo un'applicazione. Note a margine -------------- * Esempi di algoritmi percettivi:MPEG Layer I/II/III (volgarmente conosciuti come MP1,MP2,MP3) dei laboratori Fraunhofer,WMA di Microsoft,AC3 di Dolby,Vorbis I di Xiphophorus,VQF di Yamaha. ** Per una trattazione approfondita di psicoacustica si vedano i testi specialistici dedicati all'argomento. *** Non dimentichiamo che la rappresentazione nel dominio della frequenza è perfettamente equi valente a quella nel dominio del tempo e ha il vantaggio di essere più sintetica,quindi rappre sentabile in meno spazio. *** Ad esempio l'algoritmo di Huffman,che ha il vantaggio di codificare con meno bit i valori più frequenti e con con più bit quelli meno frequenti. Va a cà