INTRODUCTION:
The
main purpose of XSEC project is to develop a user authentication and
identification system that works upon biological features of the user and
delivers high precision to be used for different security purposes. User
authentication is a binary decision system that decides whether a supplied
feature belongs to the claimed person or an impostor tries to log in.
Obviously, acceptance of an impostor to the system is completely intolerable as
a security system is the case. On the other hand frequent rejection of genuine
users may be disturbing. So the system should be able to clearly differentiate
biological characteristics among different people while compensating in-person
differences. System is aimed to have complete robustness against channel
transformations and acceptable noise levels so to be able to work in practical
applications with an error rate close to zero.Ā
Biometric methods
of identification are currently being used to replace the less secure
ID/Password method of user authentication, that is, verifying that people are
who they say they are. Using biometric identifiers for personal authentication
reduces or eliminates reliance on tokens we must carry with us, or the arcane
strings of letters and numbers we are forced to memorize. Tokens, such as smart
cards, magnetic stripe cards, and physical keys can be lost, stolen, or
duplicated. Human memory is notoriously unreliable; according to recent
estimates, at least 40% of all help desk calls are password or PIN-related.
Losses attributed to fraud, identity theft, and cyber vandalism due to password
reliance run well into the billions. Although passwords have traditionally been
used for personal authentication, they have nothing to do with a person's
actual identity!
The best method for
a particular solution depends on the type of users, desired accuracy, desired
transaction speed, cost parameters and any cultural issues or sensitivities.
Technology today provides us tools like
Fingerprint
characterization, Hand geometry (palm print) characterization, Voice pattern
characterization, Iris pattern characterization, Retinal patterns
characterization, Facial feature characterization etc.
XSEC has chosen facial feature characterization and voice feature
characterization to identify people.
XSEC
ARCHITECTURE:
XSEC authenticates persons based upon there voice and
face characteristics. Whole architecture is divided into two different modules
that work independently upon speech and face characterization respectively.
Block diagram shown below gives a rough idea about the functionality of the
System.
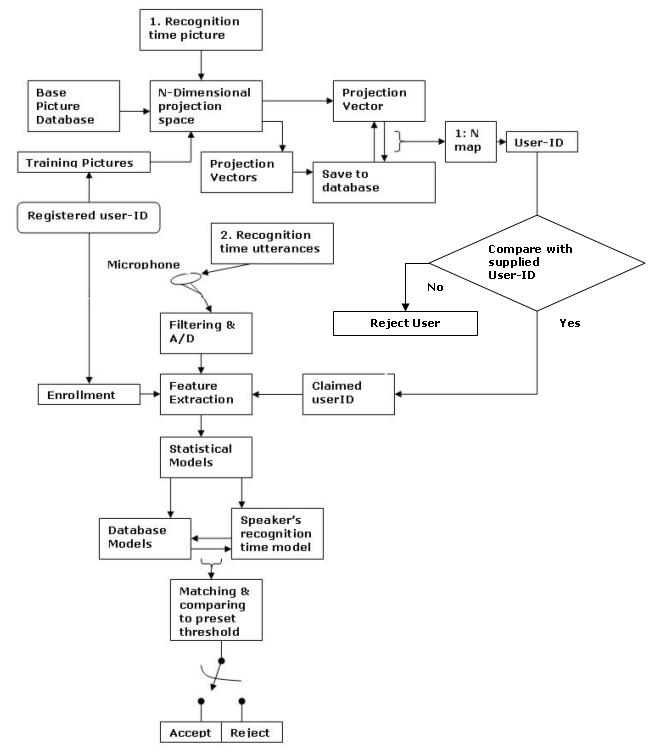
Face characterization module takes input from a digital camera at
Point-1, while voice characterization module takes input speech sample from a
microphone at point-2.
SYSTEMS
OVERVIEW:
Voice Characterization module
Speaker recognition systems are
grouped into two categories that are generally called speaker verification and
identification respectively. Speaker verification is the determination from a
voice sample if a person is who he or she claims to be. On the other hand
speaker identification determines which one of a group of known voices best
matches the input voice sample.
Another classification for voice
recognition systems takes the text dependence properties of the system into
account. Text dependent systems are those for which the speech used to train
and test the system is constrained to the same word or phrase. On the other
hand for text independent systems training and testing speech are completely
unconstrained.
Roughly speaking, a factor that
constitutes the information content of spoken utterances is speaker
characteristics + spoken phrase + emotions and additional noise, channel
transformations etc. For speaker recognition case, our concern is how to
distill speaker dependent characteristics from all others. So we may refer to
speaker verification as a three-state problem.
1. First step is to extract speaker dependent features
from spoken utterances. For this purpose different feature sets have been
proposed to reflect speakerÆs identity best most famous of which are listed
below...
ĘMel-frequency
Cepstrum coefficients
ĘLiner
prediction Cepstrum coefficients
ĘLog-Cepstrum
coefficients
2. Second stage is to build a statistical model that will
successfully reflect the characterization of the chosen feature set. Below is
the list of popular statistical models that are widely used and proved to be
successful.
ĘVector
Quantization
ĘGaussian
Mixture Models
ĘHidden
Markov Models
ĘNeural
Network Architectures
3. The third step which is the decision making step is
where we compare he input voice to the claimed speaker model and make a
decision about the identity of the speaker.
XSEC uses Mel-frequency
Cepstrum coefficients method to extract peoplesÆ voice characteristics with
techniques like RASTA filtering and cepstral mean normalization to compensate
the performance degradation due to handset mismatches.
XSEC implements a unique technique for handset
identification and normalization for the handset differences. For statistical
modeling XSEC uses hybrid architecture consists of HMM and ANN. Hence, it gives
higher accuracy than its other competitors in the market.
Face Characterization module
Along with voice identification XSEC realizes a face authentication system.
Face recognition functionality can be divided into two sub-parts, modeling of
personÆs image followed by the recognition phase. Broadly speaking, face recognition
problem can be solved by using HMM (Hidden Markov Modeling) or with Eigen
Faces. XPEG uses its own technique that makes several compromises between two
methods stated above and delivers higher recognition efficiency.
BACKBONE OF XSEC ENGINE:
Faceprint & Voiceprint database:
User is required to give his voice sample and
few training face samples when he accesses the system for the first time, i.e.
Training session. Supplied faces are in a prescribed face orientation and spoken
utterance is a predefined text of acceptable length that successfully reflects
the vocal properties of the language and the user. Once the speech samples are
taken from the user, it is processed and a property matrix that reflects the
userÆs voice is saved in the database. This property matrix is technically
called the voiceprint. Similarly, system computes to get a property matrix
corresponding to the personsÆ face and is stored in the database, which is
technically called faceprint. So the data kept in the database is not
the speech sample or picture but the voiceprint and faceprint of the user.
Login phrase:
It is vital to practicality of
the system that required login phrase duration should be as short as possible.
XSEC works with login phrases of 1 picture and 3-4 words randomly generated and
flashed to the user.
Decision-making:
XSEC tries to determine userÆs identity by face
recognition methods. Once user identity is determined XSEC
uses voice authentication methods to verify this identity. User needs to supply
his spoken utterance that will be used for authentication and the claimed
speaker information is available to the system, the feature matrix is extracted
from the speech data and compared to the voiceprint of the claimed speaker. If
the similarity score exceeds a predefined threshold value, the user is
accepted.
BIOMETRIC FEATURE SECURITY:
If a criminal steals or
guesses the password, it is very easy to have it changed. There is a fear,
however, that if a criminal gets hold of a biometric template, the damage is
irreparable - there is no way to change that part of your body. XSEC-2.1 works
in a network environment and keeps all the user specific data on a secured
server computer. Only way to introduce a new user template is through XSEC-2.1
client, hence template manipulation chances are well taken care of.
DRIVERS FOR XSEC PROJECT
There
are four main benefits to use biological verification:
1.Improve Security:
This is the key objective of using voice and face
biometrics to improve the security of sensitive information and reducing fraud.
A password is what people know. But the voiceprint and face-print is what they
have.
2.Reduce Costs:
Using an automated authentication process reduces salary expenses,
toll-costs and call hold times and allows live agents to focus on
revenue-generating calls.
3.Improve Service:
Speaker verification combined with speech recognition
(rather than touchtone) allows callers to interact naturally with the
application, so callers can actually enjoy the automated experience. The
combination of speech recognition and speaker verification makes it possible to
simultaneously identify AND authenticate callers in one step, allowing them to
simply speak an Account ID or their name to access the account and be authenticated.
4.Save Time: Whereas standard authentication questions and associated hold
times may take an average of 80 seconds, speaker verification happens
instantaneously, especially when the voiceprint and faceprint is associated
with the Account ID, removing the time needed for a separate password.
MARKET
OPPORTUNITY
As enterprises and
organizations increasingly turn to biometrics to ensure their customersÆ
safety, the market opportunities for voice/face authentication are infinite.
|
Market
|
Application
|
Drivers
|
|
Financial Services
|
Access to Banking, Brokerage,
|
Reduce Financial Risk
|
|
Telecom
|
Call Center Applications
Unified Messaging
Auto Attendant
|
Reduce Fraud
Protect Personal Information
Competitive Advantage
|
|
Retail
|
Order Entry
Personalized Service
|
Reduce Fraud
Increase Revenue
|
|
Enterprise and IT
|
Access to Intranet, Extranet
and Corporate Applications
|
Increase Security
Reduce Cost
|
|
Travel
|
Frequent Customer Services
|
Convenience
Personalization
|
|
Internet
|
Authenticate Users for
Internet Banking and e-Commerce
|
Reduce Financial Risk
|
|
Hospitals,Insurance
|
Access to Patient Information
Authorize Drug Prescription
Authorize Insurance Payment
|
Protect Personal
Privacy Reduce Fraud
|
|
Government/Military
|
Access to Sensitive Information
Parolee Tracking
|
Increase Security
Reduce Cost
|