Balzac Text Data Mining:
How to pick apart Balzac's Comedie Humaine with a computer
Some techniques using Python (computer programming language)
that you can use to learn some higher-order facts about texts.
Extracting various useful types of meta-data from the
Project Gutenberg
collection of Balzac stories.
- Importance of a Character in a Story
-
Measures the importance of a character in a story from the number of
references to the character in the story.
The Balzac novels that Project Gutenberg provides
have nice lists of recurring characters and the other
works that they appear in at the end.
Unfortunately, this list gives the reader little idea of
how important a role a character plays in
those other works.
This reference or word counting measure of character importance has been
cooked up to overcome this limitation.
[countrefs1 (program), Input,
Title Table (input), Output:
Lousteau,
Bixiou,
Bianchon,
d'Arthez]
- Get All References to a Character in a Collection of Stories
- Extracts references, finds all occurences of a word
(or more generally a regular expression)
in a collection of texts and records their location and context (surrounding words).
Uses string Search.
The output of this program can be used as input to the program 'countrefs1'
above. This program is just a script immitation of "Find in files" as found in
well-known programming editors such as
the shareware "Editplus" editor,
Microsoft's VC++ 6, or Python's IDLE.
(This script is significantly slower the editors I've just mentioned
but usable by a python program instead of manually through the editor).
(Unixspeak: "Grep" all regex matching lines from a directory of files.)
[getrefs1 (program),
Output]
- Find Important Periods of Time in a Story
- For every Balzac title, find the years referenced.
This gives a rough timeline for the work.
The distribution of years in a work
provides an idea of which years are important in the work.
Plotting a histogram of this distribution allows one to
*visually* judge the importance of different periods of time in a work.
(The years collected are restricted to years in the nineteenth century
up to Balzac's death: 1800-1848)
[Input
yearrefs1 (program),
Output]
- Provide readers with relative reading times for different titles
- In this busy world it would be nice if a reader could estimate
the amount of time a story is going to take so he can fit
it into his busy schedule. Usually people eyeball the thickness
of the book, or see how many pages there are. For an ebook
they might look at how many bytes long the file is (e.g. 654 KB).
Since we are interested in one collection of texts,
namely stories written by Balzac, we can do better than this.
We can rank his works and break them into groups:
- very long (> 80,000 words)
- long (> 50,000 words)
- medium (> 26,000 words)
- short (> 12,000 words)
- very short (< 12,001)
One simplifying assumption we make is that the time
it takes to read a title is a linear function of the
number of words (time = k * words).
In fact if a story has a complicated plot then there
could be significant non-linearities,
in which case the best way to measure reading time might
be to measure people reading it. Uses word counting.
[wordsperfile2 (program),
Output]
- Lookup extracted references in the full body of the text (GUI)
- So you have references, what if you want to see what they refer to?
Here we give you a very simple reference file viewer.
Just double click the reference line with
your mouse and the larger file is opened
and positioned to the item referenced which is highlighted.
Just like the programming editors VC++6,IDLE(Python),and Editplus.
- Get word frequencies in the Comedie Humaine Corpus
- Word frequencies in the total corpus are essential for calculating
statistics to identify significant collocations used by Balzac in his
descriptions. (e.g. faces, noses, hats, rooms, food,...)
Since Balzac used the 18th century folk "science" of phrenology
(still regarded as a science today by many where I live in Rangoon, Myanmar)
to design his characters, one can look at a character's face as a control
panel for the story's plot in Balzac, so you can see these "physiognomy collocations"
are an essential foundation for any simulation of Balzac's fictional world.
[wordcount0 (C++ program),
wordcount00 (Python program calling wordcount0),
wordcount1 (program)
Output sample]
- Recurring Character List
- Balzac like Proust is famous for his recurring characters.
The only problem is that in the Project Gutenberg edition of
Balzac there isn't a master list, only partial lists at the each of each title
that list the other works that the characters of that title appear in.
Our program just reads these files and uses Python's dictionary data
structure (Perl Hash, C++/Java Map) to accumulate these lists over all
the titles in the Balzac collection.
[recur2,
Output]
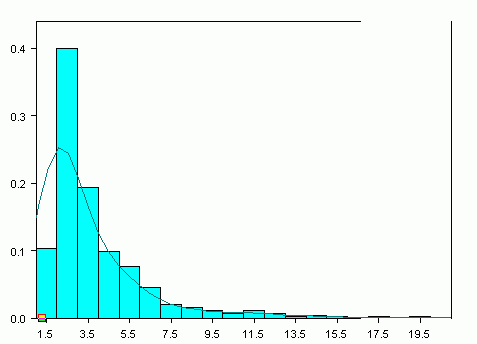
(Distribution of recurring characters. The average number of titles
a character occurs in is about 2, but some, like the doctor Horace Bianchon,
occur in or narrate in as many as 26 titles.
Points plotted in the histogram.)
- Dummy Project
- Whatever dummies like me do.
Python Code Snippets of Useful Functionality:
- extractwords1 Extract all the words from a text.
- findall2 Finds all regex matches in a string,
for each match returning the matched string and the start character of the match.
- extractwords2 Extract all the words from a text
with their start positions. Uses "findall2" instead of "findall".
- Stoplists of commonly occurring words to eliminate before indexing
(in order of increasing size):
stoplist1 < stoplist2
< stoplist3
[loadstoplist (program);
stoplist (program),
Output (for stoplist)]
- makewordlists Executes a fast C++ program repeatedly to make wordlists.
- wordchop3 Chops the first and last five words off of a string.
- textwindow4 matching with context
- textwindow6
Finds places in a Project Gutenberg file where a word or phrase occurs (w/ a regex),
extracts a context of five words on either side of the word,
and prints the word in context (the larger context of the line in the file
containing the word concatenated with the line before and after, is also provided).
- textwindow8
Collects "span occurences" of a word, used to calculate the "span frequency"
which is used to find significant "collocations" of a word in a "corpus"
Read whole file into a string, find the offsets for each occurence of the word
being searched for, iterate through these occurences,
extract a sub-string of 80 characters on either side,
and then extract the left and right neighbors of the word occurence from these sub-strings.
- textwindow11
Calculates the "span frequency" in a file of a word as a collocate of another word in a corpus
e.g. the 5-word-to-either-side span frequency of the word 'sharp'
as a collocate of the word 'nose' in the corpus of all Balzac's stories.
[Output: Sorted By Count,
Sorted Alphabetically]
- loadwordcounts
Loads the corpus wordcounts out of a plain text file with
fields delimited with a colon into a dictionary.
Regular Expressions
- matchline2
Find all matches of the pattern within the string
return a list of tuples with three items for each
match: (match,start,end).
- matchline
Extract all words in the file with their location in the file so you can trace
your way back to where the words came from.
(Word location consists of a line number, a character offset
within the line, and a character length.)
[Some Output]
Word Lists
Text Tiling
- wordsperfile Extracts/tokenizes words in a
file into a list via regular expression.
- buttonseries
Display a series of intensity values as greyscale buttons.
Series of very small grey-shaded buttons
for displaying relevance of a topic in a section of text.
[screenshot]
- buttonseries1
Buttonseries above made into an object.
- tile2 (not finished)
- tile1 (not finished)
- matchline4
Finds density of topical keywords in the text.
(Extracts all the words from the file, chunks them into contiguous
blocks of 100 words, and counts the occurence of words from certain keyword groups
in each block).
Clustering
- recur2
Makes a list of all recurring characters in the Comedie Humaine
and the works they appear in.
Also writes out a distribution of number of character occurences in titles
for the whole Comedie Humaine.
(Accumulates the lists at the end of each Project Gutenberg Balzac work into
a master list and prints it out in the same format as the Project Gutenberg lists.)
- recur3 Create character vectors for clustering.
To make groups of recurring characters which recur in the same works.
Also prints out a list of last names for full name, to be used to find
the number of references per work for each character, a more finely grained
measure for calculating character dissimilarity and clustering.
(Note: Pairwise interation counts like the number of times they talk to
each other would be even better.)
- cluster Takes output of S clustering algorithms
and prints out clusters of characters.
It takes the output of S as input:
an ordered file of titles and a file of cluster assignments in the same order.
- recurring
List of recurring characters used as input to S clustering algorithms.
- characters1
Character in title occurence data formatted in a one vector per line plain text
file for importing into S.
{kind=link}