DISTRIBUCIONES DE PROBABILIDAD
Distribuciones discretas de probabilidad
Cuando en un solo ensayo de algún proceso o experimento puede ocurrir sólo uno de dos resultados mutuamente excluyentes, como vida o muerte, alivio o enfermedad, macho o hembra, el ensayo se llama ensayo de Bernoulli.
Una secuencia de ensayos de Bernoulli forma un proceso de Bernoulli, si se cumplen las siguientes condiciones:
Se utiliza la siguiente fórmula:
f(x) = nCx px qn-x
Otra forma de escribirlo:
p(x) = px (1-p)1-x para x=0 y x=1; 0 £ p £ 1
p(x) = 0 para otros valores de x
y tiene
E(x) = np
V(x) = np(1-p)
EL cálculo de la probabilidad utilizando esta ecuación puede ser una labor difícil si el tamaño de la muestra es grande. Por eso las probabilidades para diferentes valores de n, p y x ya están tabuladas.
Ejemplo: se sabe que el 30 por ciento de la población es inmune a alguna enfermedad. Si se escoge una muestra de 10 elementos de entre esta población, ¿cual es la probabilidad de que dicha muestra contenga exactamente cuatro personas inmunes?
p= 0,3
q = 0,7
n = 10
x = 4
Utilizando la fórmula:
f(4) = 10C4 (0,7)6 (0,3)4 = 10!/4!6! * (0,1176) (0,0081) = 0,2001
Utilizando la tabla:
Se busca en la tabla el valor para n=10, x=4 y p=0,30. Este valor representa la probabilidad acumulada hasta x=4, es decir es igual a P(X £ 4). Para hallar P(x=4) se le debe restar a este valor el de P(X £ 3). Entonces:
P(X £ 4) = 0,8497
P(X £ 3) = 0,6496
P(x=4) = 0,8497 - 0,6496 = 0,2001
Cuando p > 0,5
Se deberá replantear el problema en términos de la probabilidad de un fracaso (1-p), en lugar de la probabilidad de un éxito:
P(X = x|n, p > 0,5) = P(X = n-x|n, 1-p)
Que se lee: "la probabilidad de que X sea igual a algún valor
específico, dado el tamaño de la muestra y la probabilidad de éxito mayor a
0,5 es igual a la probabilidad de que X sea igual a n-x dado el tamaño de
la muestra y la probabilidad de un fracaso, 1-p.
Distribuciones contínuas de probabilidad
Si tuviéramos una gran cantidad de valores de una variable contínua y construyéramos un histograma con intervalos muy pequeños, la forma del mismo se acercaría a la de una curva suave.
Función de densidad:
Para calcular las subáreas por debajo de la curva se debe utilizar el cálculo integral. Por ejemplo, para calcular el área bajo la curva entre dos puntos a y b, se integra la función de densidad de a a b. Una función de densidad es una fórmula empleada para representar la distribución de una variable aleatoria contínua.
La función de densidad es:
f(x) = ( 1 / sÖ(2p) ) * e-1/2 ((x-m)/s)2
y tiene
E(x) = m
V(x) = s2
Los datos p y e son
conocidos, por lo que los únicos parámetros m
(media) y s (desviación estándard).
La gráfica de ésta distribución produce la conocida curva en forma de
campana.
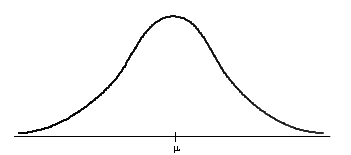
Características importantes de la distribución normal:
Tiene las siguientes características:
Para ésta distribución no es necesario realizar cálculos porque existen tablas con los reultados de todas las integraciones en las que se pueda estar interesado.
Para resolver casos que poseen una distribución normal no estándard, es posible transformarlas en estándard. Lo que se hace es transformar todos los valores de X en valores correspondientes de z. Esto significa que la media de X debe igualar a 0, que es la media de z. Se utiliza la siguiente fórmula:
z = (x - m) / s
Se transforma en cantidad de desviaciones estándard a la distancia entre la x y la media.
Ejemplo:
Un profesor piensa que los puntajes de un exámen tienen una distribución aproximadamente normal, con una media de 10 y una desviación estándard de 2.5. Si a un individuo, elegido aleatoriamente, se le aplica el exámen, ¿cuál es la posibilidad de que logre un puntaje de 15 o más puntos?
Sean X1, X2, ..., Xn n variables aleatorias contínuas, independientes y cada una con distribución normal de media mi y varianza s2i. La variable aleatoria:
U = å ((Xi - mi)/si)2 = å Zi2
tiene función de densidad:
f(U) = (1 / ([(n/2)-1]! . 2n/2)) * U(n/2)-1 * e-U/2
y tiene:
E(U) = n
V(U) = 2n
donde n representa el número o cantidad de términos independientes que son sumados para construir la variable U y recibe el nombre de grados de libertad. Es es el único parámetro de la distribución.
La función de distribución f(U) está tabulada para diversos valores del parámetro grados de libertad y permite calcular probabilidades del tipo P(U £ u).
Notación:
X2n = variable aleatoria con ditribución ji-cuadrado
X2n;(1-a) = valor
particular de la variable aleatoria que acumula entre 0 y él mismo el 100(1-a)%
del área total, con 0 £ a
£ 1.
Ejemplo: se representa la función X210;(1-a)

Sean las variables aleatorias X y U, independientes y con distribución N(m;s2) (normal) y X2n (ji-cuadrado) respectivamente. La variable aleatoria:
t = ((X - m) / s ) / Ö(U/n)
que se puede escribir:
t = Z / Ö(X2/n)
tiene función de densidad:
f(t) = [((n-1)/2)! / Ö(np) ((n-2)/2)!] * [1+(t2/n)](n+1)/2
y tiene:
E(t) = 0
V(t) = n/(n-2)
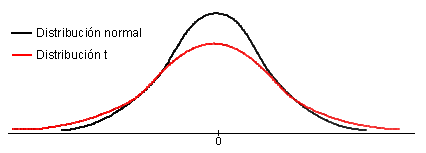
La variable aleatoria t se contruye mediante el cociente entre una variable aleatoria N(0;1) y la raíz cuadrada de una variable aleatoria ji-cuadrado dividida por sus grados de libertad. La restricción fundamental es de que las dos variables deben ser estadísticamente independientes. Como consecuencia de su estructura esta distribución depende del parámetro n llamado grados de libertad. La función de distribución, F(t), está tabulada para diversos valores de n.
Notación:
tn = variable aleatoria con distribución de Student con n
grados de libertad
tn;(1-a) = valor particular de la
variable aleatoria tal que (1-a) = P(tn
£ tn;(1-a))
La distribución tiene las siguientes propiedades: