Assembly program can be arranged into several modes. These are known as memory modes. This is very important since different mode has different impacts on the same instructions. Notice that so far we always mention model tiny clause at the beginning of our program. Recall our first chapter. The memory mode "tiny" is one of the modes that we can select. I will describe a little bit about how it is arranged. I will put the rest of the explanation later.
The model "tiny" restrict the program size 64Kbytes, which should be enough for many learning purposes. All data and code must fit within this 64KB boundary. No exception. Whereas DOS, our ancient operating system, "divides" the memory system into 64KB chunk segment, this "tiny" model fits snugly in one segment.
Note also that the memory address of our computer has 2 elements: a segment and an offset. This pair will define exactly where in the memory, which I had covered here.
Recall that we have segment registers in our processor. Since every thing fits into one segment, there is no need to set segment registers. By default, the assembly (or I should say the OS) will set all segment registers pointing into that single segment. That's why I said "Ignore setting DS" or something like that in our last chapter.
You should know that register CS by default points to the segment where the code resides. DS will point to the data segment. ES usually pointed to data segment too. SS will point to stack segment. Since CS, DS, ES, and SS point to the same segment, it means code, data, and stack resides in the same region. How can we manage this? If you think this is a mess, this architecture applies to the modern computer nowadays whereas the concept was invented somewhere in the 1940s. If you've heard the name "Von Neumann architecture", this is it. Code, data, and stack is put in the same memory.
OK, now a bit deeper. The stack is not only pointed by SS register. But also SP register. So, the pair SS:SP points the top of the stack. Initially, SP is set to the very bottom of the segment in "tiny" mode, at address 0FFFEh (not 0FFFFh, that's the bottom end of the segment). Each time we push something into the stack, this SP register will be decremented up by 2. If we push something, SP will be incremented down by 2. Whereas, our code and our data starts at offset 100h. So, the layout looks something like this:
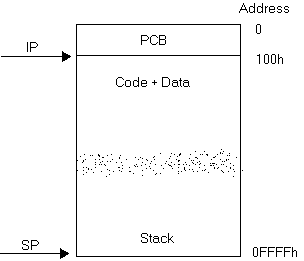
Notice that we have no boundary on stack. I draw a smear there since the boundary is not strictly defined. So, if you push too many things into the stack, the chance is it will overwrite your code. If your code is overwritten, your processor may be running garbage. But don't worry, this arrangement will provide sufficient room for normal use of stacks.
Note that I only mention IP there because CS:IP pair will define the next instruction to be run. How about data? Well, the segment usually has to be DS (or sometimes ES), and the offset part can point to anywhere in the segment.
To cope with this situation, recall our first assembly program:
:
:
org 100h
jmp start
; your data and subroutine here
start:
mov ax, 4c00h
int 21h
:
:
This org 100h actually tells assembly that our program will begin at offset 100h. Why is this necessary? It is because all running programs have Process Control Block (PCB) with it. It's sort of thing for operating system to manage stuffs, So, it's better for us not to interfere with that unless you're doing advanced stuff. After that, we have a jump, right? Then after that jump, you put all your data in, right? That's how we cope with this chaos. The unconditional jump ensures the space for data so that it does not interfere with code. and vice versa. It is usually the case when the code interferes with data, it will cause hangups, blue screen of death and so on, --again -- UNLESS you are an assembly guru that knows what you're doing (like doing some self-modification code stuff and similar arcane tricks).
When you exercise and try to build a "tiny" mode assembly program, how many bytes is usually the result after compilation? It's usually less than 200 bytes, right? So, it's far from the end of the segment. Thus, you don't have to worry about running out of stack space. There is a "huge" empty region in-between.
Application
Alright, so you know the internals of our "tiny" mode. Let's look at the following example. It's better for you to run this program in a debugger to see the effects.
ideal p286n model tiny codeseg org 100h jmp start ; your data and subroutine here start: mov ax, 100h ; initially SP = 0FFFEh, AX is set to 100h push ax ; now SP = 0FFFCh mov ax, 200h ; AX = 200h pop ax ; SP back to 0FFFEh, but now AX back to 100h mov ax, 4c00h int 21h end
See the effect? When AX is stored in the stack, we're free to modify AX. If we pop the old value back, voila! The old value is restored. This can be handy in storing (very) temporary value. You don't need to declare variables and thus reducing the code size by some bytes.
In fact, subroutine call will use a lot of stack stuffs. So, you'd better understand the underlying concept before going on.
OK, now for a surprise. Try changing push ax into push ah and pop ax into pop ah. See what happens? The SP is decremented into 0FFFCh, it is as if it is pushing a 16-bit value! Remember this gotcha!
Other Uses
Can we push a constant? In 8086 no. In 80286 or above yes. So, doing push 1, this will be treated as if a 16-bit value. No need to specify word ptr and stuff.
Pushing and popping to and from stack is useful in assigning values too. In the mov instruction, it is illegal to assign segment registers with constants. For example: It is illegal to say: mov es, 400h. Why? I don't know, ask Intel engineers. :-) Probably they try to avoid inadvertent segment changing. So, one may want to do a work around like this:
push 400h pop es
Of course this code is for 80286 or above. Well, I should say that code is not good. The better work around is to use register like this:
mov bx, 400h mov es, bx
The more useful usage of push and pop is to push flag and then pop it into register. That way, we can examine the flag content directly. Look at the following code:
pushf pop ax
There... we can examine the flag values in register AX, The net effect is the same like assigning AX with flags. Of course, the mov instruction cannot handle this.
Likewise, you can set the flag values using push ax then popf. This may be handy for a lot of cases, which I will explain further in latter chapters.
Closing
OK, I think that's all for now. See you next time.
Where to go
Chapter 10
News Page
x86 Assembly Lesson 1 index
Contacting Me
Roby Joehanes © 2001