Navigation
Papers by Melberg
Elster Page
Ph.D work
About this web
Why?
Who am I?
Recommended
Statistics
Mail me
Subscribe
Search papers
List of titles only
Categorised titles
General Themes
Ph.D. in progress
Economics
Russia
Political Theory
Statistics/Econometrics
Various papers
The Questions
Ph.D Work
Introduction
Cost-Benefit
Statistical Problems
Social Interaction
Centralization
vs. Decentralization
Economics
Define economics!
Models, Formalism
Fluctuations, Crisis
Psychology
Statistics
Econometrics
Review of textbooks
Belief formation
Inifinite regress
Rationality
Russia
Collapse of Communism
Political Culture
Reviews
Political Science
State
Intervention
Justice/Rights/Paternalism
Nationalism/Ethnic Violence
Philosophy
Explanation=?
Methodology
Optimal centralization:
More links and mechanisms
by Hans O. Melberg
Introduction
In last week's paper I
made some half-rigorous remarks about how centralization might produce worse but cheaper
decisions. Worse because a Central does not know “local conditions” as well as a
local administrator would; Cheaper because centralization entailed specialization which,
in turn, reduced the amount of labour needed to decide, say, how 1000 different drug users
should be located between 100 different treatment institutions. In this paper I want to
make things more complicated by turning the argument upside down: Maybe there are ways in
which centralization improves the quality of information and decision-making. And, maybe
centralization increases the amount of labour needed to do the job?
Two links
It is probably true that
centralization decreases the quality of information the decision-maker has about local
conditions. On the other hand, the Central knows more about “global conditions”
than a local admission administrator. Recall the example of how to allocate different drug
users to different treatment institutions. A local administrator knows his own institution
very well, but he probably knows less about other institutions. Because of this asymmetry
he might accept a person for treatment who might have been even better served by going to
a different treatment/institution. Being local you do not know this and in this sense a
Central might have better information than a local office.
However, in order for the Central to know something about local conditions they have to collect the information. This, in turn, means that they need to hire more labour. They need an “Information Collection” unit in the Central. It might even be the case that the more labour needed outweighs the labour saved (due to specialization). We could make the process slightly endogenous by arguing that the larger the local information problem, the higher the costs to an information collection unit will be.
An organizing frame
So far I have described four
possible links between centralization and my two key variables: the average cost of making
the decisions (labour) and the average quality of the decisions made. A general frame for
organising the search for more, and for storing the ones we have, could be as illustrated
in the diagram below.
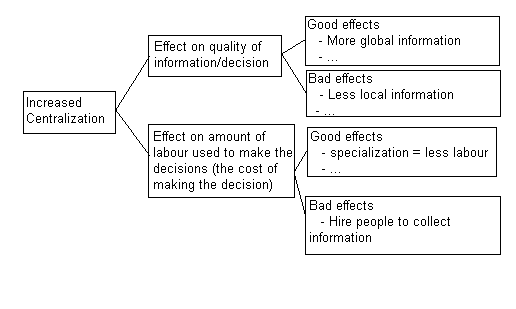
Complications
The frame in the
diagram above is, perhaps, useful in the initial search for more links between
centralization and its consequences. This is something I will continue to work on, and I
would welcome input from readers here (give me links!). As I look at the frame there are,
however, a few problems that emerge. For instance, it reveals one ambiguity that I have
ignored. That is, the connection between the quality of the information and the quality of
the decision. It is wrong, as I have done in the frame, to just equate these. Sometimes
information is important to make a good decisions; sometimes even the best quality of
information is of little help. For instance, the so-called Project Match in the USA shows
that we should not be too optimistic about the improvements that can result from
“knowing more” when it comes to how to decide where to treat people. Project
Match was a large research project aimed as finding out how to produce better results by
sending the “right” clients to the “right places.” As it turns out,
there were few significant differences: It often did not matter too much what kind of
treatment you received – different treatments were often equally good/bad for
different types of drug users. If this is the case there is little point in collecting a
lot of information about the client or the institutions in order to match them better. (In
fact, more information can sometimes produce worse decisions if people are led to focus on
things they believe to be relevant but which in fact are less relevant than the
information they already had.)
This leads me to the conclusion that I must introduce a parameter or a function that connects the quality of information and the quality of the decision. This is often easier said than done because the relationship between information and decisions may be very strange. The stereotypical relationship is, perhaps, a linear positive connection: The more you know the better the decision. Slightly more strange is a non-linear positive relationship; But what about negative and or discontinous relationship. (For discontionous relationships imagine a jury which has evidence all pointing to the accused and then suddenly they hear something that overturns all the information they have received so far – an alibi or some information that puts all the previous information in a different light). In any case, the distinction is needed and despite its complexity it cannot be ignored.
There is one more problem that I want to mention as well: The frame produces a slightly static image of the pros and cons of centralization. Might not one of the benefits of centralization be that it allows us to learn more over time. A central is in a better place to perform controlled experiments and since all “allocation administrators” work in the same central there is increased scope for communication and exchange of information between the administrators. This is potentially very important. Imagine for instance, the following argument. A person admits that centralization produces better quality information, but he believes it is slightly more expensive than local decision-making. However, he also believes - and the current state of theory and evidence supports him – that information is basically worthless. Hence, the large increase in the quality of information is not even worth the slight cost and he rejects centralization. The problem with this line of reasoning, is that centralization might in fact change the value of the information. Centralization might create the conditions (for learning and experimentation) that allows us to develop theories that make information that before was useless into something valuable. This “dynamic” element is missing from the frame I created above. (Of course, it might be also that a decentralized system sometimes is better suited for learning, but that is not my point here. The point is simply that we should look into the more “dynamic” consequences of centralization/decentralization)
Conclusion
It is too easy to say
that centralization implies that decision-makers have worse information than local
administrators and than centralization necessarily reduces the demand for labour. It is
also too easy to say that more and better information always produces better decisions.
Finally, it is wrong to focus on “static” effects of centralization and
decentralization since there may be important “dynamic” effects. All this simply
points to “more work” that needs to be done before I can put the topic of
centralizations aside.