La valutazione sperimentale di un classificatore misura
la sua abilità nel prendere le giuste decisioni, e non quanto efficientemente le prende. Pertanto si è
deciso, come è consono per il dominio della Text Categorization, di misurare i risultati in
termini di Precision ( ) e Recall (
) e Recall ( ).
). 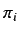 è la probabilità che se un
documento
è la probabilità che se un
documento  è classificato sotto la categoria
è classificato sotto la categoria  tale scelta è corretta;
tale scelta è corretta; 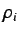 è la probabilità
che se un documento deve essere classificato come appartenente alla categoria , tale decisione
è presa. Queste sono delle probabilità ``soggettive'', che indicano solo all' utente quanto bene il
classificatore si comporterà nel misurare un nuovo documento per la categoria . Abbandonando
la terminologia adottata fino a questo punto con cui nella classificazione di messaggi di posta
elettronica si chiamava falso positivo un messaggio legittimo incorrettamente classificato
come spam e falso negativo un messaggio spam incorrettamente considerato non spam, per l'
esposizione delle misurazioni dei risultati si userà la seguente terminologia più appropriata:
è la probabilità
che se un documento deve essere classificato come appartenente alla categoria , tale decisione
è presa. Queste sono delle probabilità ``soggettive'', che indicano solo all' utente quanto bene il
classificatore si comporterà nel misurare un nuovo documento per la categoria . Abbandonando
la terminologia adottata fino a questo punto con cui nella classificazione di messaggi di posta
elettronica si chiamava falso positivo un messaggio legittimo incorrettamente classificato
come spam e falso negativo un messaggio spam incorrettamente considerato non spam, per l'
esposizione delle misurazioni dei risultati si userà la seguente terminologia più appropriata:
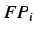 (false positives) è il numero di documenti incorrettamente classificati come a dover appartenere
alla categoria ;
(false positives) è il numero di documenti incorrettamente classificati come a dover appartenere
alla categoria ;  (false negatives) è invece il numero di documenti che non sono stati classificati
come appartenenti alla categoria quando invece tale decisione sarebbe dovuta essere stata presa;
(false negatives) è invece il numero di documenti che non sono stati classificati
come appartenenti alla categoria quando invece tale decisione sarebbe dovuta essere stata presa;
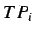 (true positives) e
(true positives) e  (true negatives) hanno ovviamente il significato che ci si aspetta.
(true negatives) hanno ovviamente il significato che ci si aspetta.
Le misure di e sono dunque calcolate in questo modo:
Per ottenere una stima di e , ovvero le probabilità relative a tutte le categorie del
dominio (che sono  : ham e spam), si è scelto di calcolare la loro macro-average:
: ham e spam), si è scelto di calcolare la loro macro-average:
- Macro Recall:

- Macro Precision:

Come si vede la macro average di tali valori altro non è che una media aritmetica delle
singole recall e precision.
Alessio Pace
2004-03-26