
I have been called "outdated," "ignorant," and many other nice names for admitting that I like XBase in front of other computer professionals. I have found it the best standardized (or nearly standardized) Rapid Development environment there is. Don't get me wrong, XBase is far from perfect, and I have plenty of complaints and suggestions for improvement, but it still beats most other languages even with its flaws. (XBase is a term for languages derived from the dBASE III+ language, such as Clipper, FoxPro, and others.)
Many allege that I like XBase simply out of familiarity and habit. While there is some truth to this, there are specific features of XBase that I believe make it a very useful tool. I have described some if these features in an article on Table Oriented Programming.
In fact, I liked XBase before I even wrote my first XBase program. I saw dbase II in action during a summer internship at an Air Force base. The next summer I again decided to look for a temporary job, so I decided to buy a dBASE III book (dBASE was "big" at the time).
Reading that book made me fall in love with dBASE, even though I did not yet find a dBASE job. A few lines of code could sort, search, index, filter, and summarize tables. Commands like "Total On", "Index On", "Replace All For", "Locate For" and "Set Filter To" were simply amazing. In Pascal, BASIC, C, and FORTRAN it took sometimes hundreds of lines of code to do this with arrays. Arrays also required more "accounting"; you often had to know in advance the maximum size and you had to keep track of the next position to be filled. In dBASE the size was only limited by disk space, and a simple APPEND command would add the next element without worrying about its position in the table. dBASE did most of the grunt work for you!
The interactivity of XBase is also a pleasure. In the following command sequence example, I can define a filtering function, preview the results, and then perform an action using the same function when I am satisfied with the results:
use mydata && open table set filter to myfunc() && set view using my own function browse && inspect it do x with "myfunc()" && perform final action if kosher (see note)("&&" signifies comments.) Sure, you can do something like this with a "Where" clause string in SQL, but only if the equivalent of myfunc() is fairly simple. The function can contain loops, IF statements, and anything else in normal code. (Some RDBMS can have user-defined functions these days, but they are still not integrated into the application language. Also note that the "with myfunc()" portion may not be needed in many cases because the filter will still apply. )
Its interactive nature allows you to perform the commands in a test environment, and then paste them into a script module when you are happy with them. Also helping this is XBase's "context" nature. This is where you set the context once rather than keep referring to it over and over again as handle(s) or object(s). Context-ing does have its downsides though if one is not careful. But it is great for interactive experimentation and browsing the "state" of things.
About the same time I started using database functions (now called API's) with FORTRAN to access and process databases and tables, but these still required more syntax and had less flexibility than dBASE. API Functions tended to be bulky and a bit too formal for many operations. Later, SQL made some things with API's a bit simpler, but still left many barriers (see T.O.P. discussion). SQL and database API's were like afterthoughts; parts attached to the outside of a language simply to make it database-able. It would be like Henry Ford saying, "You mean the car is supposed to move also? Well, then add a d*mned motor or something!" This afterthought approach is very different from designing a language to be database-centric from the start (like XBase).
We liken API's to having to reach into a small hole to get tools in and out of a tool box. Table-oriented languages are like dumping the tools all over the floor around you so that they are readily available. Although this analogy makes it sound messy, it actually makes one much more productive because more of the programming code is to directly manipulate data instead of pre- and post-processing it as it comes and goes through API's.
A year or so later I finally got a chance to use dBASE for pay. Soon after I used Clipper, and later FoxPro for Windows. I was able to crank out applications at the speed of light by letting XBase do most of the grunt work. I learned Visual Basic because it seemed like something that was growing popular, but it usually took much more coding than an equivalent XBase program to do the same thing. (Visual Basic did have more powerful GUI operations, but nothing that could not be added to the XBase language.)
Rule X: The power of computing and programming generally comes from the ability to process large quantities of similar items (collections). Many programming languages and techniques seem to either ignore this fact, or make it a minor priority. C++ and Java, for example, tend to focus on building complex, in-memory objects, but do little to help the relationships among objects of the same or related classes, aggregate manipulations of these objects, and the storage of these objects. What good is a Ferrari if you only have dirt roads?
Creating, manipulating, and processing tables in XBase are given the primary focus. Over the years I have learned to view more and more constructs as tables. This includes the powerful concept of Control Tables, and the subset known as a Data Dictionary. (MS-Access has a Data Dictionary, but it is not customizable.) Even things like trees can easily be tablized; no more pointers and linked lists! Besides, saving a linked tree to disk is a pain in the wazoo. Automatic storage (persistence) of such structures is a highly underrated feature of XBase.
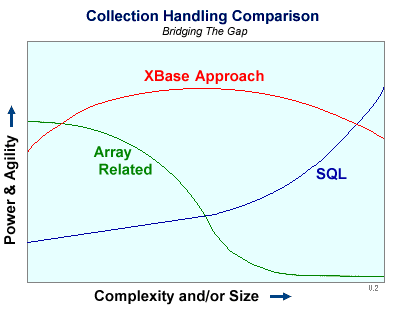
SQL does fairly well at processing large tables in a formal way, but is a bit cumbersome for middle and small stuff. (Most dialects of XBase currently support both arrays, and access to SQL servers. However, most have not attempted to integrate or hide SQL behind the often-friendlier XBase syntax. Admittedly, the translation process is not always simple to implement.)
XBase not only shines at the neglected, but much needed mid-level collection domain, but also handles the simple end and the large end of the spectrum reasonably well. Thus, a single collection engine/interface can be used to build something simple, and then scale with it into much larger works. You don't have to rewrite arrays into SQL code just because your project or collection grew up.
I recently had to maintain some ASP (VB-script) code that used arrays to store a web user's shopping cart of products. Just to add, change, and delete items in the cart required almost 3 pages of nasty array code. The same thing could have been done in XBase using about 10 lines of code and been much easier to follow.
The VB-script "dictionary object" probably would have simplified things a bit, but it is basically a 2-column RAM table. If the application grew to need 3 or more columns for carts, then a major rewrite would be needed. VB-script dictionary thingies are similar to Perl associative arrays. Microsoft just calls them "objects" to make them sound more buzzed up. SQL could also have been used, but it still would be larger than the XBase code. MS-Jet (MS-Access) also has some buffering bugs that complicate SQL usage.
However, the need for table orientation did not go away. GUI's did not do away with Rule X. GUI component references can even be stored in a table. To some extent FoxPro 2.5-2.6 did just this in its screen builder; although at that time, Foxpro did not integrate it's data grid (table browser) very well into windows for some strange reason.
OOP has also failed to deliver on many of its promises. (I liken OOP to Communism: it sounds great on paper, but does not work for many niches because it relies on faulty assumptions about human and business nature.)
There are other table oriented languages and packages, such as Paradox, MS-Access, and Clarion Developer; but these are based on proprietary languages. XBase is the closest thing to a multi-vendor standard in table oriented languages.
I am envisioning a language that does the same thing with tables, except provides automatic persistence. XBase is the closest (near standard) I have come to seeing table nervana. (Perl is also unnecessarily cryptic in many cases and is awkward handling tables with more than 2 columns.)
I have tried to find something like this in Object Oriented techniques, but have been unable to. OOP's goal seems to be modeling everything as self-contained little units, not productivity. These are not the same. OOP does not handle relationships between things and groups of things very well. It is too obsessed with individual objects such that it lost focus of collections. (I don't believe that OO's brand of abstraction makes for real improvements because the real world does not bother to grow and change based on OO's abstraction patterns. The real world has it's own agenda.)
Thus, XBase has often been a victim of its own success--it quickly takes a company up to the next level. (As the links below describe, there is no reason that XBase or variations cannot handle access to high-end database engines with some effort or changes. There is also a product called Advantage Database Server that gets great reviews. Further, there is OpenPath's RDD's for Clipper. There are also rumors of ODBC drivers being written for Clipper RDD's.)
See Tabled GUI Notes for more on this.
I am not saying that the current GUI-enabled XBase products are no good, I am just saying that it could have leapfrogged the crowd and done something more in the spirit of XBase. Why be just another clone -- Think Different!
Further, VBA requires one to go through object-oriented API's to access data. These API's are known as DAO and ADO. Object orientation and tables generally don't get along very well. Thus, when one is programming in Access, they have to translate back and forth between three different kinds of things: VBA, data API's, and the tables. This tends to be awkward and time-consuming.
Access makes up for such weaknesses in part by having handy mouse-oriented shortcuts. However, if you wish to move away from manual fiddling and script an action instead, manual mousing won't help anymore. If you are automating something for hundreds of future uses, then the extra cost of programming in Access won't matter as much. But if it's an ad-hoc or infrequently-used operation, then Access programming is not worth it. Access thus poorly feels the gap between manual fiddling and long-lasting programs.
I find that I often want to script actions used to test ad-hoc requests. The user/requester often comes back and wants some changes. If it is already scripted, then one does not have to go through all the manual steps over again to regenerate the results with some changes. Thus, the easy up-front scripting ability of XBase pays off when changes are requested. Having the script ready not only speeds up your productivity, but reduces the chance of making human errors compared to Access's manual process. In Access you might click on the queries in the wrong order, for example. (Sure, you can create "macros" in Access, but this is yet another thing that has to be translated to code if you later want more control. Plus, it does not visually put related queries together, as described later.)
XBase was designed before mice became common and thus is optimized for quick keyboarding. However, programming via mouse has not been perfected yet. Access tries to make it possible to build SQL via dragging and clicking, but they had to contort the resultant SQL so much that it is verbose and hard to work with as programming code.
In contrast, the keyboard commands one uses in XBase can often be used with little or no modification for more formal scripts. Thus, XBase has little or no transition cost that one often finds in Access going from mouse-centric activities to programming code. In Access, the mouse is one world and the programming arena is another world, and traveling or translating between them is time-consuming and cumbersome.
Further, it is hard to "inline" Access queries. One either has to paste in a query and manually put quotes around each line, or reference a formally named query by name in the programming code. If you use the named-reference approach, you cannot see the query code (SQL) from multiple related queries together in one spot: you have close one query edit screen to view another query. It is a lot of going back-and-forth. And, just try to print all that out in Access.
XBase's biggest weakness used to be with data joins (cross-referencing data). However, some key dialects have since added SQL ability, improving the join story. Thus, one can use both SQL and XBase queries as best fits each task. One has the best of both worlds. And, one does not have to manually put quotes around SQL statements in most dialects to inline it.
Access also makes it tough to break out of certain actions when you want to discontinue an activity. Hitting the Escape key almost always immediately ends or pauses an XBase script. Access sometimes waits several minutes before waking up.
The philosophies behind each product show through. The people who designed XBase were actually lazy and it shows; they wanted the machine to do as much work as possible with the least amount of programmer typing and effort and they achieved this goal more than competitors have. The goal of Access was to allow newcomers to get up to speed quickly using the mouse. However, learning fast and being productive once learned is not necessarily the same thing. To add programming for "power users", The Access designers bolted on the VBA language that Microsoft had sitting around for other purposes. The seams between the mouse world and the VBA world are thick and cumbersome.
First, Perl deals with data mostly on the character level instead of the "cell" level. One has to parse characters into table cells to be able to manipulate data as cells and rows. In XBase the fundamental "atom" is the table cell, not characters, so one is working with a more appropriate level of abstraction for the task at hand.
Second, Perl does not natively support tables. To get a table one has to nest data structures such as lists and associative arrays, and they don't automatically obtain common table-processing features: you have to build those yourself or find an obscure, poorly-tested library that does it. Some Perl fans say that one does not really need tables and that nested primitive data structures are "good enough". However, their arguments have been weak. In debates, their sample code to compete with typical Xbase and SQL queries was more complicated, harder to read, and more error-prone (although I will concede that "code elegance" is perhaps a subjective metric).
Third, Perl lacks visual editing and inspection features found in XBase commands such as Browse, Edit, Modi Struc (Modify Structure), etc. Sure, one could probably add such to Perl with enough programming, but then one is just reinventing XBase from scratch.