
Updated 8/20/2001
Examples using the "device driver" pattern are often brought up whenever I ask someone to demonstrate the alleged superiority of object oriented programming over procedural/relational (P/R) techniques.
Although the challengers often build what are in my opinion poorly designed versions of P/R to compete against, I will agree that there are some aspects of most object oriented languages that make the driver pattern a bit easier to deal with under certain circumstances.
However, in my niche of small and medium custom business applications, I do not encounter the need to build the driver pattern very often at all. The frequency is not nearly enough to justify adding OO to a language for the generally rare cases of occurrence. I would rather see the complexity "spent" on something more practical and common.
Some OO gurus suggest that the same language be used for both building and using. However, I disagree.
The feature set needs of a component/interface building language are different from an application building language. Adding features that are needed by one and not the other:
Some claim that they work better with non-scripting-like languages for application building. This may be a subjective mind-fit preference, and I will not tell such people what they do their best work in. I have heard good arguments from both sides of the strong-versus-weak typing debates. Strong typing often adds more protection, but it also may result in code clutter from conversion and adapter processing. Strong typing also sometimes encourages black box connector inflation.)
Designers of application languages should perhaps make linking to driver building languages like C/C++ easier, but still keep the niches separate.
However, I have yet to see how the OO approach adds any significant benefit for the driver user (application programmer). Like I said elsewhere, the biggest difference between the object approach and the procedural/relational (P/R) approach for usage is mostly just a matter of the syntactical ordering of the verb and the handle (a.k.a. object).
I have considered the possibility that this pattern is there more often, but that I simply fail to recognize it. However, OO fans in some web discussion groups were also unable to come up with decent business examples. This seems to confirm that the pattern is either rare in the niche in question, or at least very hard to recognize.
Why would it be so rare in the niche in question? I believe the answer revolves around these:
First, swappable interfaces are difficult to design. It takes a lot of experience with a topic to design a good interface, especially one with many commands. My experience, which correlates with that of others, is that building generic tools often takes at least 2 iterations to get close to right. And, this is assuming one is doing similar projects over and over, which is not always the case.
Further complicating the interface design process, if many implementations/projects depend on an existing interface, it is tough to change that interface without having a strong impact on all users (code) of the interface. (This is related to the Fragile Parent Problem.)
If one is going to design a generic interface, then they better be in it for the long haul, because it will usually take time away from the short haul.
I often like to build Data Dictionary frameworks. My later attempts were more usable than my first attempts. However, applications that used the first attempts would be tough to convert to the newer attempts.
(Building these data dictionaries was not a direct requirement of the projects; I simply decided to make perfecting data dictionaries a goal. However, even my early attempts resulted in increased intra-project flexibility in my opinion.)
Second, many interfaces and components are already pre-built. Most of the drivers on the above list are available in many languages and development tools without ever having to write a single OO class. Perhaps they were implemented using C++ classes, but the applications programmer may never have to see these classes.
Note that most of the listed interfaces are not direct business interfaces. They could be used by other niches also. This odd pattern leads into the next reason.
Third, business changes too fast. Things like collection manipulation are going to always be applicable. Perhaps new collection manipulation paradigms will come along, but even the old ones will still function as collection manipulators. This may not be the case with business rules. Today's Human Resources interfaces may not be applicable in the future because of law changes, common practice changes, and/or new management decisions.
The items on our list could perhaps be called "semi-static" in that they do not need to change that often. Most changes are for attempts at improvements, instead of change to keep up with marketing, investment, and legal trends, which is more common in business. Thus, a distinction between improvement changes and directional changes is being made.
Fourth, there is perhaps a resistance to cooperate to create generic business interfaces. The business belief is that one must outmaneuver one's competitor. If you cooperate on an agreed-upon interface to some business task, you then lose a chance to have a better system than them.
It would be like two western gun fighters agreeing on gun specifications such as bullet size and speed. The gun fighters then sacrifice some of their ability to alter or tune their guns to obtain a possible advantage. There is psychological comfort in knowing that you have control to change something. Accepting a standard reduces choice, or at least perceived choice.
Both paradigms require a translation layer or phase. Nobody disputes this since each participating company is likely using different languages, paradigms, operating systems, schemas, etc.
I usually find such diverse things needing to answer the same messages or protocols when different systems have to communicate, not the same system. If they come about in the same system, then they are usually factored into a very similar or identical construct (such as a shared table), and thus they are no longer "diverse" (unless poorly designed).A typical OO approach for translation would resemble:
class BobsChairs child of Client
method initIterator // iterator prep
[open or prepare collection emulator]
end method
method getNextBill // iterator
// convert and/or get data
self.bill = foobar....
return self.bill
end method
method getTotalDue
// calc or get total due
self.total = x * barfoo....
return self.total
end method
....
end class
Each client would then have a custom
subclass based on a similar template.
(The details of gathering each individual field or attribute
for getNextBill are not shown, but
would probably comprise the bulk of the code.)
A procedural/relational approach often would also have a module dedicated to converting each company (but possibly sharing some common utility functions). However, it would most likely concentrate on converting the information into an internally standardized list or table.
If a table, then a shared (internal) table for all clients may be possible rather than one table per client. A Client_ID field would be used to filter by client. If a file is used, such as XML or an EDI transfer file, then it may initially be one-file-per-client or per bill. Also, often there may be a separate Header and Detail table/file.
One advantage of the table approach is that you are not limited to a single kind of collection operation . You can do all kinds of queries and views on the table. They are also easier to inspect between the translation step and the data usage step. Once it is in a table(s), I can query and view and report it every which way til Sunday. Straight iterators are yawners in my book.
Note that the OO approach my also get info from a table/database from some clients, but it is still squeezed through the same kind of conversion methods (same interface). The "wrapper sequence" is roughly like this:
OO: Diverse_source -> DB -> Translation -> Interface -> Usage P/R: Diverse_source -> DB -> Translation -> DB -> Usage(Note that the first DB is not the same as the second one in the P/R sequence.) In the P/R approach, one "inherits" all the power of relational table systems. The OO approach potentially requires re-inventing query engines for each client to get the same operations.
I worked with an auction website in which the translation was done by the sender, and not so much the receiver. The active auctions were converted into a standard XML-like format as specified by the auction data broker/search-service. Actually, our system performed two different conversions because two different auction search services had different formats. Thus, sometimes the burden of conversion is on the sender and sometimes on the receiver. Actually, for a fee they would do some or all of the conversion on their side. But, in this case we did not want to pay the fee, so we stuck closely to their format specification.On another note, one could argue that even though plain (virtual) iterators are not as sophisticated as an RDMBS, they still provide faster turnaround. IOW, my approach requires something to fill a table(s) first.
However, I would argue that most useful business information is stored in tables anyhow, not floating around in RAM. Thus, you might as well design the system so as to take advantage of the power of relational engines and existing tables.
Things just seem to "flow together" better when everything is a table :-)
My solution was to place the out-going email information into tables. The main table in this setup acted as a message queue. The application would simply fill in (append) the table with the message and message attributes, and another process would process the queue (sometimes immediately, and sometimes on the cycle of a timed process). The sending process did not have to care about how the information got into the queue table.
This had several advantages over using a direct email API. First of all, we did not have to change the table structure if we switched the email engine/component, or if the component's API changed. The translation from table to email engine happened in only one spot.
Second, it gave us instance access to often occurring collection features. For example, if a message could not be sent for some reason (network error, full mail buffer, etc.), the system noted the failure in a Status column, and tried again later. (Ideally, there should have been an upper-limit to the retries. We could have also stored the retry count in the table.)
If we wanted to implement delayed retries using the native API, then some mechanism would be needed to store (persist) the message information between retries. A native email API will not necessarily provide such a feature. ("I'm a doctor, Jim; not a database!")
Further, it is easier to view the email information in a table. A native API is not likely to make it easy to view sent and pending messages. ("I'm a doctor, Jim; not a TV-set!") Even if it did, we would have to learn how to access that. Tables allow one to use existing knowledge to add, change, delete, view, persist, etc. The wheel does not have to be re-invented nor re-learned for every new component.
The table also served as a log of the out-going email. This made email statistics and debugging easier. Any error messages returned by the email component was also stored. ("I'm a doctor, Captain; not the Captain's Log.")
I often find typical collection/database features are needed again and again like this. One cannot rely on native API's to provide all such needs that keep popping up. (Sometimes fancy components do try to be a database-like gizmo, but it often backfires because it brings up the cost and complexity and learning curve of the component.) Collections are too important too keep re-inventing in different incarnations.
(Another look at procedural email API's is given later in the Case Studies section.)
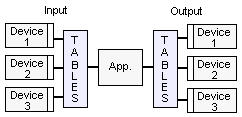
In my experience, most I.T. shops don't wish to support multiple interfaces for custom software, and end up "standardizing" on one. I will come back to possible reasons why this is so later. For now, let's assume that such will happen. The primary OO reasoning given is that if a new UI "device" is added, the existing code does not have to be changed. The new device is added as a new sub-class of the device interface.
However, the reverse is the case if a new operation is added to existing software: the OO version would most likely need more spots to be changed. This is the classic aspect battle of task-orientation (procedural) versus OO sub-typing (sub-nouns). See the shapes document for a deeper discussion of this.
Perhaps if new devices were more common than new operations (for all or many existing devices), then the OO version may have a point. However, that is not likely to be the case because the number of devices targeted will stay low for custom software. I cannot envision more than 3 fully different devices being supported, but can imagine a standardized UI interface with way more than 3 operations/methods/commands.
Now, lets return to the issue of why many shops don't end up supporting multiple UI's in practice. One possibility is that managers think it is too hard for non-OO software to handle, and thus don't ask for it. I don't think this is the case. For one thing, I see no difference in requests from seasoned and new managers. New managers are less likely to have experienced the alleged failures of non-OO multiple UI's. Of course, this is anecdotal information and you are welcome to conduct a survey.
I suspect that the real reason is two-fold. I will call the reasons the "LCD problem" and the "80-20 problem". LCD stands for "lowest common denominator". To support multiple UI's, often times one has to find a common set of services that all participating and perhaps potential new UI's can all share. This tends to limit what you can do with your interface. You cannot "take advantage" of UI-specific features that may make some tasks easier or friendlier.
For example, one interface may make it easy to scroll up or down a screen that has many data-entry fields (too many to fit on one screen). However, another interface may not readily be able to scroll screens with fields. Thus, you may be forced to break the set of fields up into digestible chunks. However, the best chunk-size for one UI may not be the best size for another. Perhaps you can make the field quantity self-calculating. However, the "splitter" mechanism may then split up two fields that best belong together, such as City and Zip-code. We could perhaps introduce grouping codes to assist with the auto-splitter, but then our system is getting progressively more and more complex. Plus, often such schemes turn out not to be sufficient and we have to keep adding features to patch up the prior attempts.
The second reason is the 80-20 rule. This states that one interface is usually dominant (80 percent) over others. (It could be 90-10 or 70-30. It is just a name.) It might be reasoned that it is simpler to find concessions for or convert the 20 percent rather than support two UI protocols. (It is sometimes said that this is why Microsoft Windows dominates.)
Thus, overall, businesses are reluctant to support multiple UI protocols. The primary exception that I have seen is web-pages. Because customers often use different versions of browsers, a business must cater to multiple browsers if they want sales. Unlike internal devices, businesses can't really control what UI devices customers are using.
One approach is to use lowest-common-denominator HTML. However, this limits the media experience in many managers minds. Although requests for browser-specific features probably has lessened after the dot-com fallout, it is probably still a fairly frequent request.
In my experience, dealing with browser-specific HTML does not quite fit the driver pattern. Most of the output is still shared between browsers, but places here and there need "tweaking" for the different browsers. In other words, the implementation is not independent between different browsers. Most of the implementation is shared. The matching of browser to "tweak" is often done via a trial-and-error process, and it is often hard to find a pattern that can be re-used at new spots.
I divide the tweaks into two camps: lack of support, and
esthetic anomalies. Lack of support is when a browser version
does not support something, such as dynamic-HTML or style
sheets. Esthetic anomalies are when browsers differ in the ways
that they display certain items. For example, the size of HTML
table cells can vary by about up to 3 or 4 pixels not only in
different brands, but on different platforms within the same
brand and version. The differences are often context-dependent
so that it is difficult to find an consistent rule or algorithm to
calculate the differences ahead of time for different spots or
different usage's.
Lets look at some example initialization code for some hypothetical ad banners using packages from two different vendors, Sun and HP.
One could replace the two vendors with "display types", such as HTML and GUI as the two options. The concepts are mostly the same either way. However, distribution issues may be different in practice, since one may want to group by operation instead of display type in the latter case. This is because new operations and operation-related changes are probably more common than "type-related" changes and additions. See "User Interface Variations" above.
// Example A banner_1 = new SunBanner() banner_2 = new HP_Banner() // Example B banner_1 = new banner(vendors.Sun) banner_2 = new banner(vendors.HP) // Example C banner_1 = banner(vendor="Sun") // get procedural handle banner_2 = banner(vendor="HP") // Example D banner_1 = banner(vendor="Sun", Color="green") banner_2 = banner(vendor="HP", Color="Blue") // Example E banner_1 = new GreenSunBanner() banner_2 = new BlueHP_Banner() // Example F banner_1 = banner(Color="green") banner_2 = banner(Color="Blue") // Example G banner_1 = new banner() banner_2 = new banner()Example A shows the typical way that OOP models device interfaces in code. Each device is a different class or subclass. However, from the interface user's perspective, the provider (vendor) could be an attribute as far as they are concerned. Approach A artificially elevates the "vendor-ness" above other attributes, such as color. From the interface user's perspective, vendor is not necessarily more significant than color (examples D and E).
Most would even say that example E is silly because it would generate a new class for each color combination. I see no reason from the user's perspective to treat vendor linguistically any different from a color attribute. Thus, if we want to be consistent, both should either be part of the class hierarchies (Example E), or both should be designed as attributes. I don't think anybody would defend the first option, especially when there are more than 2 attributes.
In fact, we may want a default vendor so that an explicit vendor is not even needed (Examples F and G). The approach of example A forces the user of the interface and/or a reader to care about vendor more than they should. (It is true that the Banner parent class could point to a default vendor.) We may start out with vendor being a required decision, but then later modify it to be optional.
If you agree with me that from the interface user's perspective, vendor is not necessarily more important than color, or any other attribute; then why is this practice relatively wide-spread? I believe that part of the reason is the over-emphasis of taxonomies in OOP training material.
However, another reason is probably code packaging. Vendors will usually distribute their drivers independent from other vendor's drivers. In OOP this often corresponds to a complete class (one file per "main" class often). Thus, it is convenient to match a class to a vendor's version of the driver in OOP.
The problem is that what is convenient for the distributor or the installer of the driver may not necessarily be convenient for the user of the driver (developer). The developer does not, and should not, have to care about how the distribution and installation is done. A car's steering wheel operation should be designed for the owner's needs, and not the mechanic's nor the manufacture's need, for the most part. In other words, de-couple the implementation and installation issues from the interface. One should optimize the interface from the user's perspective.
This does bring up the issue of how to actually implement and distribute drivers without mucking up the interface. One way or another, something somewhere is going to have to "dispatch" to (look-up) the proper vendor. Example A puts this dispatching burden on the interface user. This indeed may be more machine-efficient, but burdens the interface user, as already described.
The answers to this issue tends to be language-specific. It may involve some sort of "interface registry" database (roughly similar to the Microsoft Windows registry, but hopefully more robust). See Multiple Dispatching P/R Patterns for some ideas related to driver management databases.
There are probably some OO patterns that may also be used to attempt to isolate the raw vendor selection from the interface user. However, the advantage of the database approach is that more factors (dispatching dimensions) can be added without major code disruption. Other factors may include versions, different interface types (HTML versus GUI), etc. I have never seen OO scale well this way.
The above philosophy of simplifying the interface for the interface user's perspective shares some kin with reducing Protocol Coupling. Protocol Coupling can drag the interface user into a bureaucracy of protocols that he or she may not otherwise want or need to care about.
For instance, Java is not optimized for string and ASCII report parsing, but can do it if needed. If 50 percent or more of your daily programming efforts involve string parsing, then perl may be a better choice than Java. However, Java can still parse strings with more code and more work. But, if string and report parsing is only 2 percent of your tasks, then Java's disadvantage in that area is of minor concern. Java's other advantages may overshadow it's relative weakness in strings by your assessment.
In fact, perl programmers often brag about how easy it is to parse strings and reports in perl. Such bragging often falls on deaf ears because many readers don't spend that much programming effort parsing strings anyhow.
Similarly, many OO proponents and books keep showing off certain things that OO does well, but fail to explicitly consider how often such tasks are really needed for given niches. They have too many weapons that target ground troops, ignoring the more common air battles, or visa versa.
Example tasks or specialties could be: string parsing, component building, driver building, heavy persistence, SQL interfacing, execution speed, math, family variations (a group of similar applications), embedded systems, RAD, change handling, critical systems (medical and life-support), cross-platform, GUI-intensive, game programming, web programming, mass distribution, OS making, systems and networking software, scientific research, large, small, multithreaded, etc. (This list is not necessarily mutually exclusive nor exhaustive.)
It is of course not realistic to target a language to be everything. One should think about what tasks are important to optimize for and rank them. Example:
| Feature/Task | Commonness % | Complexity/ Effort |
Ratio | Include? | Running Total |
|---|---|---|---|---|---|
| Collection Manip. | 30 | 20 | 1.50 | Yes | 20 |
| String Comparing | 30 | 4 | 7.50 | Yes | 24 |
| User Interface | 20 | 15 | 1.33 | Yes | 39 |
| Report Writer | 14 | 25 | 0.56 | no | - |
| Validation | 13 | 7 | 1.86 | Yes | 46 |
| Parsing | 12 | 8 | 1.50 | Yes | 54 |
| foo | 9 | 12 | 0.75 | no | - |
| bar | 8 | 3 | 2.67 | Yes | 57 |
| fling | 6 | 19 | 0.32 | no | - |
| ding | 4 | 2 | 2.00 | no | - |
| Driver Pattern | 2 | 10 | 0.20 | no | - |
Our sample algorithm for choosing what to include or not is as follows:
This is not the only way to rank features; it is just a simple approach to illustrate some concepts.
Although we lump complexity and effort together, they are not always the same. Some features can be added as simple functions (API's), while others may end up being more integrated within the syntax. Something more integrated perhaps should be given a higher complexity score even if it only requires the same amount of effort. Part of the reason for this is that it is harder to undo tightly integrated decisions.
Also note that this chart mixes the solution with the problem. However, a more complete analysis would probably divide them. For example, string parsing can be handled with Regular Expressions (reg.ex), or just with a basic set of parsing functions (substring, position search, splitting on a character, etc.). A set of string manipulation functions is usually enough to get the job done, but reg.ex makes some chores a snap if you are familiar with it's conventions. Thus, building in language features to handle strings is not an all-or-nothing thing. A sub-issue is how much string handling.
Similarly, collection handling can be handled via 3rd-party libraries, built-in libraries (API's), or built-in collection-handling syntax (such as in XBase. See below).
For the sake of discussion, we will consider an "average level" of implementation if implemented according to our chart.
Should a language meant for custom business applications have strong string parsing capabilities? Strong enough to justify built-in regular expression operators? String parsing is encountered fairly often in business programming, but perhaps not enough to justify adding regular expressions to the built-in functionality. Regular expressions add to the learning curve and can greatly slow down code reading if the reader is not well versed in regular expressions. Regular expressions are not very self-explanatory. However, regular expressions are near the border of commonality in my opinion and experience. Perhaps about 12 percent of my code is dedicated to string parsing. Regular expressions could perhaps reduce it to 5 percent. (Not all parsing can be practically done via a typical regular expression implementation.)
The driver pattern and other patterns that OO does fairly well at are either not common, or modeled instead as relational tables (which allow data to be shared by multiple languages and paradigms more so than OODBMS). I probably encounter a need to build a driver-like pattern only roughly 2 percent of the time. In the target niche, the driver pattern's usefulness-to-complexity ratio is too low.
eSend(title, text, toAddr, toName, senderAddr)Although sufficient, one can envision a more complex interface variation that allows multiple recipients, for example. However, there are some problems with this approach.
First, can we predict ahead of time the most generic interface for handling nearly all variations?
Second, what if the driver in current use cannot handle the features of a more generic interface?
Third is such complexity worth it if we are only sending one message per recipient in our current application?
Fourth, is making it more generic within the current budget of the current project? Although I usually try to keep genericity in mind when building such items, full-out genericity planning and implementation could take many times longer than one that satisfies the current requirements.
One flaw I found in the above function approach is that it is tough to add new parameters in some languages (those that require parameter counts to be the same in the caller and callee). In such cases, one must visit all instances of the function invocation.
An OO-ish implementation may allow something like this:
eSend.title = "You too can win millions!" eSend.text = mySpamText eSend.toAddr = "joe@sixpack.com" eSend.toName = "Mr. Joe Blow" // (blank if don't know) eSend.senderAddr = "spammakers@spammers.com" eSend.sendHowever, this is not much different than using named parameters instead of positional parameters. Named parameters are not an OO-exclusive concept.
Either way, using named parameters (if supported), or OO-ish dot syntax allows one to add new parameters without having to change all the callees. Remember, though, that this only works if the new parameter is optional or has a "safe" default for existing users of the component/interface.
Note that dot syntax (or a similar syntax) is not exclusive to OOP.
XBase is the name given to derivatives of the dBASE III+ product language. XBase has a strong integration of relational table (collections) constructs built into it's syntax. For example, most clauses that act on a collection will take a "for" clause that tells which records to select. It is similar to SQL's "Where" clause. Example:
replace all payAmt with payAmt + bonus for sales > 2000 delete all for sales < 500 * Comment: Copy only top sales records to an Excel spreadsheet copy to file bunus.xls type xls for sales > 2000I found having the collection operations built into the language very useful for custom business applications. I am not that fond of SQL API's for such tasks. (There are some very annoying things about XBase, but it's collection integration was an overall plus in my opinion.)
The XBase dialect/product known as Clipper allows one to pick which collection engine to use for a given table or even the entire program. Thus, the collection engine could be switched without ever changing the syntax in most cases. These engines were known as Replaceable Database Drivers (RDD's). The Clipper vendor published the interface specification so that anybody could write their own RDD's.
Even though Clipper had a few OO extensions, these were not needed to make use of the different engines, nor were the OO extensions used for writing the drivers in most cases. Most of the RDD's are written in C or C++ I believe.
There are even Clipper RDD's that tie to Oracle and other SQL servers. (The original purpose of RDD's was to allow Clipper to use the indexes and memo files generated by other vendor-specific or obsolete XBase formats.)
However, the underlying translating from XBase collection manipulating syntax to SQL is not without it's hitches. For one, XBase has more of a cursor-orientation than SQL. (Note, however, that XBase does have many set-oriented aspects to it, but less than SQL.) Most SQL engines are optimized for set-orientation, not cursor-orientation.
Thus, many practices that are common in XBase software can be notoriously slow to implement using SQL engines. (The Clipper application can be rewritten to be more set-friendly, but this defeats the purpose of swappable drivers; plus, may change the feel of the UI.)
For example, many XBase applications give the user a "browse" screen, which is a data grid that one can scroll up and down in. This requires a collection engine to efficiently pull out a "previous" and "next" record (based on a controlling index or sort) from the entire table, not just a subset. The set-theory of SQL tends to shun such a concept; thus, it is tough to simulate it in an a database engine that is based on SQL philosophy. (See SQL Criticism for more examples.)
We can see that even though Clipper's RDD interface and the SQL interface (a.k.a. "protocol") are both collection manipulation interfaces, they are based on some different philosophies that make using/translating one to the other a bit tough. The lesson is that there are many ways to shave a cat and the differences can cause unanticipated problems. (For good or bad, XBase was not designed with SQL and set theory directly in mind.)
Footnote: One can start a fierce battle over whether set-orientation is better than cursor-orientation. In my opinion, cursor-orientation is more intuitive and natural, while set-orientation may be more machine optimizable. Perhaps a decent hybrid can be formulated. However, since SQL is so entrenched, it's approach will probably be given priority simply for compatibility reasons. Similarly, GUI interfaces may also be biased toward OO languages, and thus OO approaches may be needed for heavy GUI work simply for compatibility reasons, not out of raw paradigm merit.
One can envision a similar case where there is a standard collection manipulation package that has a choice between using arrays or a linked list for the implementation. Even though they both offer the same functionality, an operation to get the nth element would probably be much quicker in the array implementation in most cases. This is because an array usually allows the CPU to go directly to a given position; whereas, the linked list requires traversing the entire list up to the target node. On the flip side, the linked list might perform better if there are many insertions and deletions.
Even though they may both offer the same functionality, they have very different performance characteristics. If one does not take this into account when writing an application, converting to a different implementation may not be the simple plug-and-play that a common (shared) interface may imply. (Personally, I prefer flexible, agile relational tables to both arrays and linked lists.)