Next: Fase di categorizzazione Up: Fase di addestramento Previous: Algoritmo per il calcolo Indice
1.begin:
2. For each category:
3.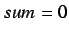
4. For each termin
:
5. For each categorywhere
:
6. Ifthen:
7.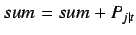
8. end if
9.
9. end foreach
10. end foreach
11. end foreach
12.end
Anche in questo caso, se si assume che ![]() è implementato come una Hash Map con
costo costante
è implementato come una Hash Map con
costo costante ![]() per accessi e ricerche, allora il costo computazione totale di questo
algoritmo è
per accessi e ricerche, allora il costo computazione totale di questo
algoritmo è
![]() , che è quadratico rispetto al numero delle categorie
, che è quadratico rispetto al numero delle categorie ![]() (la cui quantità comunque è di gran lunga inferiore rispetto al numero totale dei documenti),
pertanto effettivamente questo secondo algoritmo è meno costoso di quello del calcolo della Presenza
visto nella sezione precedente.
La complessità computazionale della fase di addestramento è quindi
(la cui quantità comunque è di gran lunga inferiore rispetto al numero totale dei documenti),
pertanto effettivamente questo secondo algoritmo è meno costoso di quello del calcolo della Presenza
visto nella sezione precedente.
La complessità computazionale della fase di addestramento è quindi
![]() .
.