Next: Algoritmo per il calcolo Up: Fase di addestramento Previous: Definizione di e Indice
1.begin:
2.
3. For each category:
4.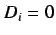
5. For each document:
6.
7. For each unique term:
8. Ifis
then:
9.
10. else:
11. Add
12. end if
13. end foreach
14. endforeach
15. For each term:
16.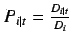
17. end foreach
18. endforeach
19.end
Se si assume che si può usare una HashMap HM per conservare i
risultati di ![]() , in modo tale che ogni ricerca o aggiornamento in
HM abbia un costo computazione costante pari a
, in modo tale che ogni ricerca o aggiornamento in
HM abbia un costo computazione costante pari a ![]() , nel caso peggiore
l'algoritmo per calcolare il parametro
, nel caso peggiore
l'algoritmo per calcolare il parametro ![]() ha un costo di
ha un costo di
![]() .
I simboli hanno i seguenti significati:
.
I simboli hanno i seguenti significati: ![]() è il numero di categorie,
è il numero di categorie, ![]() è il numero
medio di documenti per ciascuna categoria,
è il numero
medio di documenti per ciascuna categoria, ![]() è il numero medio di termini per ciascun
documento.
è il numero medio di termini per ciascun
documento.
Alessio Pace 2004-03-26