Vengono esposti sinteticamente i costi computazionali di alcuni algoritmi utilizzati nel
dominio della Text Categorization, con riferimento a quanto illustrato da Fan Li [43].
Nella Tabella 3.3 i simboli hanno i seguenti significati:
 : numero di documenti utilizzati nella fase di training
: numero di documenti utilizzati nella fase di training
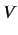 : numero di parole (il vocabolario)
: numero di parole (il vocabolario)
 : numero di categorie (classi)
: numero di categorie (classi)
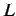 : lunghezza media di un documento
: lunghezza media di un documento
 : numero medio di caratteristiche (features) in un documento
: numero medio di caratteristiche (features) in un documento
 : la lunghezza di un decision tree
: la lunghezza di un decision tree
I costi di GAME, rispetto a quanto visto nei paragrafi precedenti, sono stati espressi quindi
in modo leggermente diverso, per facilitare il confronto con le misurazioni degli altri algoritmi.
Dai costi si vede come esso si colloca fra gli algoritmi di classificazione più leggeri (sullo stesso
livello del Naive Bayes, del quale però ha migliori prestazioni), mentre l' SVM computazionalmente è
più dispendioso e non sempre utilizzabile. Il suo utilizzo per la progettazione di un filtro anti spam
è stata dettata quindi dal fatto che risulta essere un ottimo compromesso fra prestazioni ottenibili
e complessità computazionale richiesta.
Alessio Pace
2004-03-26