| Plan | Add money | Subtract Money | Checks | Interest | Feature 5 | Feature 6 | Feature 7 | Feature 8 | Feature 9 | Feature 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Checking | X | X | X | - | - | - | - | - | - | - |
| Savings | X | X | - | X | X | - | - | - | - | - |
| Plan C | X | X | X | - | - | X | - | - | - | - |
| Plan D | X | X | - | X | X | - | X | - | - | - |
| Plan E | X | X | - | X | X | - | - | X | X | - |
| Plan F | X | X | - | X | X | - | - | X | X | X |
Note that the plan information could perhaps be stored per-customer instead. An example of this can be found in the Business Modeling document. Further, there are often more than just Boolean flags, as described below. For example, there might be an interest calculation strategy code (daily, monthly, yearly, etc.) and/or some rates. The example uses Boolean flags to make certain patterns more clear in the examples.This banking example is roughly based on a Smalltalk tutorial by Andrew Valencia. Smalltalk is an object oriented (OO) language. Note that the root class is assumed to be an "abstract class," which means that it is not to be used directly as a live bank plan. That is why there is no corresponding row for it in our example table.
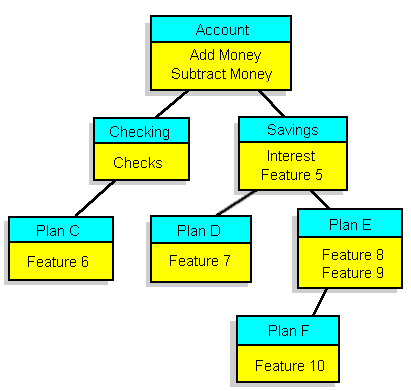
Andrew's tutorial showed how the root class, Account, had the operations that all banking accounts would need. These include the operations "add money" and "subtract money". It then showed how accounts are often split into checking and savings accounts. Both these accounts inherit their parent's operations, which are Add Money and Subtract Money in this case. This is a very typical object oriented inheritance example as found in many OO language books. This example assumes checking accounts and their variations (such as plan C) have checks, and savings accounts and their variations (Plans D, E, and F) have interest.
In the middle of Andrew's example it suddenly occurred to me that I once had a bank account that had both checks and interest!
This issue highlights a typical problem with inheritance. Changes and variations rarely follow a hierarchical pattern in the real world. Both marketing and management would much rather view the customer banking plans as combinations of features rather than a hierarchy.
What if management suddenly decided to also include Feature 6 in Plan F? (see above illustrations.) In object oriented programming, the code for Feature 6 would likely have to be moved or linked into the top (root) class in order to be inherited by both Plan C and Plan F. However, this would then allow every banking plan access to Feature 6, which may not be what management wanted.
Hierarchies like the bank tree example are very nice when they occur; but in the real world, variations rarely have all or even most of their features (methods and properties) fit into nice hierarchies. Inheritance can only be realistically applied to a very very limited set of real world structures and organizations if you want to keep them flexible.
We could select any combination of features by putting an 'X' in any slot we want in our table. However, the tree can only represent a very limited set of feature combinations unless you want to put up with a gigantic tree. (Some combinations may not be valid combinations for real-world situations.) In this example, the hierarchy assumes either checking or savings, but not both. "Why a tree?" one may ask. Because OO doctrine says trees are good?
At least two experienced OO proponents that I have debated agree that inheritance is not really meant to model real world business items. They suggest that inheritance is better used for internal software organizational structures, such as the structures presented in a fairly new software engineering trend called "patterns." If the proper place for inheritance is in internal software structures, then why do so many OOP books strongly suggest that inheritance is highly useful for external structures and data? This seems to be very misleading.
subclass Checking {
add_money = yes
subtract_money = yes
checks = yes
interest = no
feature_5 = no
feature_6 = no
feature_7 = no
feature_8 = no
feature_9 = no
feature_10 = no
}
subclass Savings {
add_money = yes
subtract_money = yes
checks = no
interest = yes
feature_5 = yes
feature_6 = no
feature_7 = no
feature_8 = no
feature_9 = no
feature_10 = no
}
subclass Plan_C {
add_money = yes
subtract_money = yes
checks = yes
interest = no
feature_5 = no
feature_6 = yes
feature_7 = no
feature_8 = no
feature_9 = no
feature_10 = no
}
subclass Plan_D {
add_money = yes
subtract_money = yes
checks = no
interest = yes
feature_5 = yes
feature_6 = no
feature_7 = yes
feature_8 = no
feature_9 = no
feature_10 = no
}
subclass Plan_E {
add_money = yes
subtract_money = yes
checks = no
interest = yes
feature_5 = yes
feature_6 = no
feature_7 = no
feature_8 = yes
feature_9 = yes
feature_10 = no
}
subclass Plan_F {
add_money = yes
subtract_money = yes
checks = no
interest = yes
feature_5 = yes
feature_6 = no
feature_7 = no
feature_8 = yes
feature_9 = yes
feature_10 = yes
}
Note that in this case we could define the "defaults" in the
parent class such that we only have to include the
"yeses" in the plan detail. Example for Plan F:
subclass Plan_F {
add_money
subtract_money
interest
feature_5
feature_8
feature_9
feature_10
}
This approach may reduce the code size, but has it's
own problems and tradeoffs. Further, it does not extrapolate to
non-Boolean (non-yes/no) attributes very well. (Normally
there are a wide variety of feature specifications.
There may be rates and
strategy codes,
for example. Our use of mostly Boolean features here is only
to keep the examples clean.)
It is obviously easier to manage the features and see patterns in the table version than the code version. In the table we can in one view compare feature-wise (columns) and plan-wise (rows). Our code can only show each feature in it's plan context. We can invert the code to put each same-named feature together, but we have to do this at the expense of the other view. Because the table is two-dimensional, we are not forced to choose one perspective at the expense of the other.
By the way, the inverted view would resemble:
Method Add_money {
case checking = yes
case savings = yes
case plan_C = yes
case plan_D = yes
case plan_E = yes
case plan_F = yes
}
Method Subtract_money {
case checking = yes
case savings = yes
case plan_C = yes
case plan_D = yes
case plan_E = yes
case plan_F = yes
}
Method Checks {
case checking = yes
case savings = no
case plan_C = yes
case plan_D = no
case plan_E = no
case plan_F = no
}
Method Interest {
...etc...
Note that the Add Money and Subtract Money are applied to all
plans (subclasses) in this case. Thus, we may want to "hardwire"
them so that we don't have to specify them for each plan.
However, there may be some legal conditions where a plan user
may not be able to add or subtract money. Our approach would
depend on how likely customization of a feature may be called
for. A programmer may have to interview banking experts before
making such decisions.
Note that the "features" are Boolean in this case. However, Control Tables can have much more than boolean expressions in them. Also, a control table would probably not be justified in this case unless there were at least a few dozen bank plans.
See the Client Representation
example in the Publications case study for other possible
OO solutions or syntax.
The code to process our Control Table (CT) could resemble this snippet:
sub printChecks()
mysql = "select * from customers, accntCT CT ; // continue line
where customers.plan = CT.plan"
T = open( _sql mysql) // open table with SQL statement
while not eof(T)
if T.checking = "X"
print_a_check(T)
endif
nextRec(T)
endwhile
endsub
As a side-show, an alternative way to loop
using table-friendly
constructs could look like this:
T = open(......) print_a_check(T) _scan T _where T.checking = 'X'The "scan" modifier tells the system to loop through each record using the "where" filter, and executing the "print_a_check" function for each applicable record. ("Scan" is roughly borrowed from some XBase dialects.)
sub doMany( feature, funcName)
mysql = "select * from customers, accntCT CT ; // continue line
where customers.plan = CT.plan"
T = open( _sql mysql) // open table with SQL statement
while not eof(T)
if eval("T." & feature) = "X"
eval(funcname & "(T)" )
endif
nextRec(T)
endwhile
endsub
// example calls:
doMany "checking", "print_a_check" // same as first example
doMany "interest", "calcInterest"
doMany "feature_7", "FeeIfLow"
The "eval()" function simply evaluates
the string expression. (It is similar to
perl's and FoxPro's eval().) Also, we may not
need to open the table (T) for every
call to doMany(). We could possibly just
perform the SQL once and pass T to
doMany (and other subroutines).
Thus, there are many ways to reduce the repetition and maintenance for control table handling code. These are only a few variations. Experience with control tables and eval()-like operations will bring to mind many other code simplification ideas and variations.
class Account {.....}
class Checking extends Account {
method calcFees() {return foo * checkCount}
.... // other possible methods
}
class Savings extends Account {
method calcFees() {return bar * amt}
....
}
If change in policies comes along and
accounts were then allowed to be both checking
and savings, the OO approach would be a lot of code-rework,
as we will see below.
However, in a typical procedural/relational approach the change would be relatively simple:
// *** BEFORE ***
sub calcFees(account) { // pass in a record set
fees = 0
select on account.accountType {
case "checking" {fees = foo * checkCount}
case "savings" {fees = bar * amt}
}
return fees
}
// *** AFTER ***
sub calcFees(account) {
fees = 0 // init
if account.hasChecking {fees += foo * checkCount}
if account.hasSavings {fees += bar * amt}
....
return fees
}
No code has to be moved out of the subroutine.
We simply changed case blocks into
IF statements and made some minor changes
to add a summation process. (Summation may already
be in place if say tax was calculated on the total fee.)
Also, note that we don't have to change the class or entity
membership or type of any existing instances if and
when they change account "types". (Perhaps "features"
is a more appropriate description than "types", especially
if there are other
orthogonal
ways to divide accounts.)
Whether one has to change the table schema or not is not a strait-forward issue. Since it may not be practical to have neither checking nor savings in a given bank, perhaps only HasChecking is needed. We could use the existing field to mean the same thing probably. We also may only need one IF statement, perhaps with an ELSE. You can however see that as the rules change, we can change or add IF statements as needed around applicable sections of code without the need to move code (contents inside of IF blocks) in and out of a routine. As stated elsewhere, this tends to resemble a rule-based expert system. The triggering of the rule depends on it's criteria and not so much on where it is placed.Lets look at the OO possibilities a bit closer. One suggestion is to make a new subclass that encompasses both:
class Account {.....}
class Checking extends Account {
method calcFees() {return foo * checkCount}
}
class Saving extends Account {
method calcFees() {return bar * amt}
}
class CheckingAndSavings extends Account {
method calcFees() {
fees = 0
fees += foo * checkCount
fees += bar * amt
return fees
}
}
If things stay small and simple, this may
be feasible. However, it is a nasty
road down the path of the
Attributes-In-Name
Pattern. If we start adding other orthogonal
attributes as subclasses, then we risk a combinatorial
explosion in subclasses. Subclasses
with rather goofy names at that.
We may also have to move some code out of the Checking and Savings subclasses and move it into the parent class in order to share it with the existing subclasses. We could copy-and-paste it into the new subclass like shown above, but this is poor repetition factoring, especially if the algorithms were longer. The actual calculations should probably be specified in only one spot so that we don't forget to change the second one if we need to change the first.
// refactoring shared methods example
class Account {
.....
method sharedFoo() {return foo * checkCount}
method sharedBar() {return bar * amt}
}
class Checking extends Account {
method calcFees() {return parent.sharedFoo()}
}
class Savings extends Account {
method calcFees() {return parent.sharedBar()}
}
class CheckingAndSavings extends Account {
method calcFees() {
fees = 0
fees += parent.sharedFoo()
fees += parent.sharedBar()
return fees
}
}
The p/r version does not need to refactor shared algorithms
since there are no "subtypes"
which have to share anything. Which
action is triggered per instance (account record)
in the p/r version
is based on a relational
or Boolean formula/expression, and not
code that is positionally coupled to a "node"
on a taxonomy tree.
Sometimes logic shared among tasks may also be factored to a "central" location to enable sharing. However, business rules tend to be task-specific, so the sharing factor is not very high. An exception may be UI, navigation, and data manipulation frameworks (if no DB avail.), but these should probably be centralized anyhow from the start.It is pretty clear that the p/r version suffered significantly fewer changes in this example.
The remaining choices for the OOP version are either to convert to an attribute-based approach and use IF statements, which requires not only moving the code out of the subclasses, but perhaps even demolishing the subclasses themselves. Instances would have to be re-typed somehow (re-classing effort may vary widely depending on the OOP language).
Somebody suggested multiple inheritance along the lines of:
class Account {.....}
class Checking extends Account {
method calcFees() {return foo * checkCount}
}
class Saving extends Account {
method calcFees() {return bar * amt}
}
class CheckingAndSavings extends Checking, Saving {
method calcFees() {
return Checking.calcFees() + Savings.calcFees()
}
}
However, this still has the Attributes-in-Name problem,
and it is not clear whether most actual situations
can simply be added or appended together as it can
be under our over-simplification of the world here. Use of
multiple inheritance is somewhat controversial,
especially when the features are so similar as
to make it hard to track or understand which inheritance path
is being taken. (I would usually rather use tables to manage
a complicated graph {calculation network} than linear code.)
Most OO proponents perhaps would suggest some more complicated OO pattern for management of many such features (such as perhaps Decorator). P/r can also usually apply similar patterns. However, the p/r code is still likely to need less changing to "convert" to a pattern. The rule triggering of the p/r versions of many of the OO patterns are not based on code position nor containment membership, but expressions and formulas. Thus, one may have to change IF statement expressions and/or query (SQL) formulas perhaps, but the existing code (block body) will pretty much remain where it is. The structure will thus remain relatively stable throughout the life-time of the project.
The word "convert" was put in quotes above because p/r tends to view GOF-like patterns as temporary, or relatively non-invasive views of the data and relationship. In other words, a task "has-a" view, instead of "is-a" view. It is a formula applied to the data which gives one the pattern view, and not physical code structure. Decoupling the patterns from the code structure makes p/r more change-friendly in my opinion.