you can miss if you get type-happy
Updated 8/7/2001
Jim Weirich has a webpage where several implementations of a version of the classic OOP shape example are supplied. I have presented an XBase version below. (XBase is derived from dBASE III+ and "clone" dialects of this once popular desktop and LAN relational database system.)
The XBase version stores the shape data in a table rather than just RAM (memory). This is much more typical of business applications. It also highlights some of the base assumptions behind Object Oriented Programming with regard to real-world projects.
Jim's C++ example assumes that the shape instances are born and die in memory. However, most dynamic information (data) of the world is stored in RDBMS's (relational tables). An OO fan can argue that it belongs in OODBMS's (OO databases), but that is another topic. For now, they must accept the fact that it's mostly in RDBMS's for now and the near future.Note that shapes are not very representative of real world needs in general business programming partly due to the subject matter and partly because geometry is quite static compared to business rules. However, we are looking at the shape example because of it's familiarity to students of OO. In general, I do not find the need to have large repeated lists of case statements very often in my procedural/relational code; thus, this debate is mostly academic. However, some of the philosophical issues that appear here resurface in other debates. Large and repeated case lists are often a sign that a table should be used to control the "feature selection" of the variations instead of case lists. OO books greatly exaggerate "case proliferation".
The OOP version could map it's structures to an RDBMS, but mapping is an extra layer to add to the program.
Our relational version (XBase in this case) is certainly not more overall code than the C++ version. So, what are the differences? For one, the XBase version uses SIMPO orientation (case/switch statements) instead of the SOMPI (by subclass) of the C++ version. (Don't worry about the strange terms; we will illustrate them with code examples below.)
Case statements are considered to be a great evil in the church of OOP. One of the reasons stated for this is that in OOP, dispatching data to the "proper" method/function is done "automatically", and thus does not need case statements.
The use of the term "automatic" by OO fans is a bit misleading. The OO approach is simply a 2-step process where in p/r it is a one-step process. OO first assigns something to a "type". The behavior is then "inherited" in a way by being a member of that type. (One disadvantage of being type-tied is that if typing {is-a} turns out to be the wrong modeling approach, then you have a lot of changing to do. P/r slides from is-a to has-a much smoother for the most part.) Comparing the approaches of the 2 paradigms is like comparing apples to oranges and gets into some messy philosophical and linguistic battles. Thus, rather than get pedantic about the term "automatic", I find it much more useful to focus on the total effort to set up and manage the related structures. As a general rule, whenever software engineering debates get bogged down in terminology and classifications, it is best to change focus to measuring effort and results. Another related and equally messy debate issue is whether one approach is faster than the other as far as CPU usage. This often relates to whether compile-time binding or weak binding is used. More on dispatching is discussed below.However, this "automatic" dispatch does not make OOP programs shorter, nor necessarily better organized. This is essentially because the proximity structure of the relationship between methods and subclasses (shapes) has been inverted. A negative photographic image takes up just as much information as the positive. It is just an inverted version of the same thing:
OOPish:
Circle
Draw
Move
Rotate
Rectangle
Draw
Move
Rotate
Polygon
Draw
Move
Rotate
Procedural:
Draw
Circle
Rectangle
Polygon
Move
Circle
Rectangle
Polygon
Rotate
Circle
Rectangle
Polygon
(We added some methods not in the original
for illustration purposes.)
As you can see, both types of organizations take up roughly the same amount of code.
With the procedural/relational approach, the case statements serve as sort of "dividers" and are roughly equivalent to, or at least take the same space as, OOP method headers.
OOP programs can actually be longer if they are getting information from an RDBMS. This is because they need to map from the table into memory variables. This mapping will require a case (switch) statement or something equivalent even though one is using OOP. Thus, even OOP cannot always escape case statements. Especially when dealing with outside information.
The reasoning goes that if you add a new shape to the program, then you only have to make additions to one spot in OOP. Adding a new shape type, say ellipse, will only require the creation of one subclass from start to end:
Subclass ellipse {
...
method draw(...) {...}
method move(...) {...}
method rotate(...) {...}
}
However, what if you have to add a new procedure (method)?
Suppose we wanted to add a FindCenter method/function
to each and every shape?
In this case the procedural approach requires less "jumping
around," because you only have to visit one procedure
(the new one, "FindCenter()").
However, adding a new method may require
visiting every shape subclass in the OOP program.
(Inheritance is discussed later.)
You would have to hop around from shape type to shape type.
It would be like having to visit every house on the block in
order to add a new function to their phones.
Thus, which paradigm requires the least jumping around depends on the type of addition or maintenance needed. Neither paradigm has a monopoly. A tradeoff is forced upon the developer.
Some OOP developers claim that adding new subclasses is more common that adding new methods/operations. If such additions are quite frequent, then perhaps they should be put into a table and have an input form so that the programmer is not burdened with frequent additions. (This is obviously would not work for shape types.)
One thing I have noticed is that new subclasses (or their procedural equivalent) are rarely coded in isolation. In other words, the programmer does not just sit down and code the new shape type from start to finish. They usually want to see how the other shapes implemented related operations.
OOP tends to force related methods apart, and thus isolates them. This is a feature of OOP that I don't like. (Sure, multi-windowed code viewers can help, but they can also be used in procedural programs to help with their proximity weaknesses as well.)
Also, in procedural programming, procedures related to a given procedure tend to be nearby the procedure. Thus, information about implementing a procedure is all in one place, and this is good. Example:
Routine Draw(shape) // (procedural pseudo-code)
select on shape.typeField
case rectangle
penDown(topX, leftY)
movePen(topX, rightY)
movePen(bottomX, rightY)
movePen(bottomX, leftY)
penUp
case polygon
penDown(nodeX[1], nodeY[1])
for i = 2 to shape.nodeCount // "nodeCount" is a field.
movePen(nodeX[i], nodeY[i]) // Arrays shown here, but
end for // could also be tabled
penUp
case ellipse
// to be inserted. See discussion.
End Routine
Routine penDown(...)
...
End Routine
Routine movePen(...)
...
End Routine
Now, if we had to add a new shape to Draw(), such as Ellipse, we could
see how the other shapes implemented Draw. We can
also see drawing-related routines nearby, such as PenDown(), MovePen(),
etc. (We will call these "utility" routines.)
This helps us implement Draw() for new shapes because we can learn from the other shapes' implementations and can also readily review the other drawing-related utility operations, which are likely to be nearby.
For example, inspecting the drawing code for Rectangle and Polygon we see a pattern of "penDown(), movePen()...movePen(), penUp()" for both shape types. This acts as a guide or template to implement new shapes. (The new ones might not always use that pattern, but it helps us to see if we are on track by comparing.)
Using the OOP approach would not make it easy to see how similar shapes implemented Draw() because they would be well-separated from each other. Because you could only see one shape type at a time (without extra effort), you might not notice the "pen" pattern we just described, due to the fact that they are not adjacent. It is much tougher to see patterns unless related things are next to each other. One might also miss some good factoring opportunities.
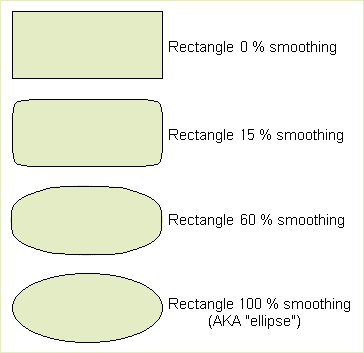
Below we described how one may view and/or implement an ellipse as nothing more than a rectangle with a 100 percent smoothing factor. Viewing the implementation of each subtype in isolation may cause a programmer to miss this simplification trick. (Note that a smoothed rectangle is probably not the most efficient implementation, but often times in one-off business dynamic applications, simpler code is more important than CPU usage.)Also, there is no way to put PenDown() and MovePen() near where they are likely to be used because there is no "near"; It's callers are scattered about in different OO subclasses. OOP sacrifices the convenient gathering of draw-related stuff all in one place that procedural orientation gives us.
Many OOP books fail to point out this important proximity loss for some unknown reason. They only describe the pro-OOP side of the tradeoffs. OOP's grouping by subclass has its set of advantages, but there is a clear and nasty tradeoff. (Note that Control Tables attempt to eliminate making such proximity tradeoffs by taking advantage of a table's 2nd dimension.)
In OO it is often said that "nouns handle themselves". Well, in procedural code often the "verbs handle themselves". Nouns are no more important than verbs. Yes, they are very different aspects of software modeling, but they are both important.
Some of these complaints seem to be based on unpleasant experiences with case statements from specific languages. There are many variations and approaches to case statements out there. Please don't dismiss case statements based on a specific syntax or implementation of them. They vary widely. (XBase case statements are probably not the best representation around. Visual Basic has a fairly nice case statement, although it is a little wordy.)
Also see Block Discrimination.
Note that some have complained that this XBase version is not really polymorphism for various, but somewhat vague reasons. There seem to be many variations of definitions floating around. This article views polymorphism as being able to hand-off various items to another entity and get a result corresponding to a given name or description regardless of the type of item handed over. In other words, the user (including component user) should not have to explicitly pre-sort or pre-label items based on their type or nature in order to use a "polymorphic" operation.
Even if my example does not qualify under somebody else's definition of polymorphism, my main focus will remain on what is the best way to do something based on the circumstances, not what it is called. Some OO-fans get too caught up in definitions and lose sight of more practical concerns. In other words, worry about whether something is good before worrying about what name to assign to it.
However, the case statement equivalent also makes the code smaller. For single-level inheritance, a default is "fallen into". This is very analogous to letting an OO parent implement a method if nothing is stated in the subclass. Both are a kind of "programming by silence". (If an implementation is required, then the case default is often an error message. It depends on the circumstances.)
The Equivalent of multi-layer inheritance is done by listing multiple subtypes on a given case line. (Not all languages support this feature.)
The case approach has the added advantage of allowing this to happen if only parts of a "subclass" are inherited. It is easier to get away from the tree organization of subclassing. In casing you can pick and choose in more of a set-oriented fashion. OO requires loading up the top parent class in order to do this.Here is an illustration of single-level and multi-level inheritance equivalency:
sub mySample(rs)
select rs.type // field "type"
case RECTANGLE
blah...
case CIRCLE
blah...
case POLYGON
blah...
case TRAPEZOID, POLYGOID, HYPERGOID // multi-layer inher. equiv.
blah...
case else
blah... // default (parent) code
endSelect
endSub
This example is roughly based on Visual Basic case syntax, which
does allow multiple items per case block.
Note that if most of the implementation code is shared per routine, or the differences not "even" from variation to variation, then case statements may no longer be recommended. See Change Boundaries for more on this.
See the Inheritance Compared document for illustrative and quantitative code examples regarding case statements and inheritance.
Same have claimed that OOP can potentially check for missing method implementations at compile-time. However, this assumes that you are never going to use the parent's implementation. In other words, for compile-time checking to work, you either have to decide to override every "enforced" method, or always use just the parent's. This prevents selective-inheritance, which is supposed to be one of the selling points of OOP inheritance. I agree that in some cases this might be useful, but only in very limited circumstances.
It seems that OO does save on dispatching code, but takes up more code in defining the parent class. Procedural/relational programming does not (usually) have the equivalent of this in the form of a "parent case" structure. Thus, as far as code size, it is generally a wash. (See Inheritance Compared.)
Some also claim that the "manual" dispatch makes case statements more error-prone. My experience is that it does not, simply because case statements that repeat the case list in multiple routines are generally rare. This "textbook case" pattern is mostly a figment of OO books (or bad proceduralists).
Further, the OO approach can have problems in declarations, such as assigning the wrong subclass to a given instance. (Although the ratio of usage to declaration is admittedly generally higher.)
If such a case pattern was more frequent, then dispatch protection perhaps would approach something to look into further.
Even the toy shape examples can fall under this. Somebody suggested that a "smoothing factor" be added to shape instance records/objects. An ellipse can then be nothing more than a rectangle with a 100 percent smoothing factor. The "type" distinction is then blurred and messy. What "type" is a rectangle with a 90 percent smoothing factor?. This "attribute view" instead of the type view reflects the real world more accurately and is more flexible IMO.
I keep finding instances of "in between" situations. For example, I have been making the distinction between "temporary" and "permanent" files for many years. However, I have grown to realize that what I really need is a "disposition" attribute. A disposition attribute indicates how long for the system to "keep" the file. A typical "temp" file may have a disposition setting of 12 hours, for example. However, some files I may want to keep for just a month, or a year. If the file system supported this, then many files on my system would clean up themselves more or less. For example, a resume that is customized to a particular company probably has a useful life of a few months. Five years from now it would be of no use because my skills and experience will change (unless my OO-bashing gets me black-listed :-)Further, the importance of attributes can change over time. If somebody turns one attribute into a type and makes subclasses based on it, what if that attribute then falls out of importance? The subclasses then become a ball and chain that no longer reflect anything significant about the instance.
To get an idea of the interchangability, think about a fulltime/parttime flag in an Employee class or table. One could (ill)conceivably make 2 subclasses instead called Parttime and Fulltime:
class Parttime extends Employee {....} // Java-like syntax
class Fulltime extends Employee {....}
In regards to the applicability of shapes to real world
problems, the rules of Geometry are generally immutable (timeless)
and shape properties well documented. However, the business
world is much more unpredictable and dynamic.
One can state with confidence that no rectangles will ever have a radius. However, most analogous rules in the business world are generally subject to change.
"All bank accounts must either be savings or checking, but not both."
If this is a current rule, it could change over night. New civic laws, or a Grand Marketing Gimmick could allow BOTH.
Suppose an OO designer splits "real estate" into two types: "land" and "buildings". What then is a peice of land with a small kiosk on it? Land? Building? Both? Even if there is a strict legal definition that distinguishes for the time being, laws are being changed all the time.
In software engineering terms, one is often called an "is-a" relationship, and the other is called a "has-a" relationship. "Has-a" can more or less be translated as, "has an attribute or feature."
I contend that to mistake an is-a relationship for a has-a relationship is safer than the other way around. The "collection of attributes" view (has-a) simply "bends" better with change. Types have to be mutually exclusive by definition. However, attributes can toggle between mutually exclusive and complementary with relatively minor code changes.
See Subtype Proliferation Myth for more about this and other problems with the "type" view.Note that restrictions on combinations of attribute values can be enforced via RDBMS rules and "triggers." For example, a global rule can be applied to a Shapes table in the form of: "Reject update if type='rectangle' and radius <> Null".
This depends highly on the table/DB engine being used. In many DB engines, unused fields are simply not populated per record. Only the schema (field list) needs to know about any new or unused fields. See Control Table Notes for more about this.
I am afraid that the OOP shape examples fail to demonstrate any clear superiority of OOP for typical business programming.
****** Procedure to illustrate persistent shapes
set exact on && Typical Xbase settings
set deleted on
set talk off
set safety off
clear
do main && main moved to bottom to match C++ example
return
*--------------------------------------
Procedure Draw && draw current record
* [see note below about table handles in parameters]
do case && The "evil" case statement
case shapetype = "rec"
? "Drawing rectangle at (" + fmt(x) + ", " + fmt(y) ;
+ ") Width " + fmt(width) + ", Height " + fmt(height)
case shapetype = "cir"
? "Drawing circle at (" + fmt(x) + ", " + fmt(y) ;
+ ") Radius " + fmt(radius)
otherwise
? "Error: invalid shape: " + shapetype
endCase
return
*--------------------------------------
Procedure MoveTo && move coordinates in current record
Parameters newX, newY
replace x with newX
replace y with newY
return
*--------------------------------------
Procedure RMoveTo && move relative coordinates in current record
Parameters newX, newY
replace x with x + newX
replace y with y + newY
return
*--------------------------------------
Procedure NewShape && create a new shape record
Parameters pShapetype, px, py
append blank
replace shapetype with pShapetype
do moveto with px, py
return
*--------------------------------------
Function fmt && format numbers
parameter thenum
return( ltrim(trans(thenum,"########")))
*--------------------------------------
Procedure DoSometh
* Operates on current record. See "handle" note below.
do draw
do RMoveTo with 100, 100
do draw
return
*--------------------------------------
Procedure Main
select A && pick a table work area
use shapes exclusive && open table
zap && empty out table (for example only)
* Add rectangle (normally done in a form or other method)
do newshape with "rec", 10, 20
replace width with 5
replace height with 6
* Add circle
do newshape with "cir", 15, 25
replace radius with 8
* Loop thru shapes
goto top
do while .not. eof()
do doSometh
skip && next record
enddo
*
do newshape with "rec", 0, 0
replace width with 15
replace height with 15
replace width with 30
do draw
use && close table
return
*--------------------------------------
***************************************
*
* - NOTES -
*
* - This uses a table called "Shapes" with the following
* structure:
*
* ShapeType - Char(3)
* X, Y, Width, Height, Radius - all Numeric
*
* - I wish Xbase allowed "t.fieldx" to make it easier to
* pass a table handle (t) to the routines, which would
* be better organization for larger programs.
* Although one can do:
* &t.->fieldx
* that is a bit awkward, especially for this
* example. Some dialects do have slightly better shortcuts;
* but, we are striving to be generic and therefore using
* Xbase's "record context" heavily. Ideally the
* routines would look more like:
*
* Procedure Draw(t)
* ...etc...
* case t.shapetype = "rec"
* ...etc...
*
* See the "L" code example (link below) for a
* cleaner approach.
*
*
* - I did not include the SetRadius and similar
* rectangle operations because it is so trivial
* to assign a value to a field that making a new
* function/method just to assign a field results in
* unnecessary code bloat, especially with tables
* that have several dozens of fields. If one wants
* protection or validation, then RDBMS triggers
* are usually used for such purposes.
*
* - We shortened the name of "DoSomethingWithShape"
* because some older dialects may not like longer
* names.
*
* - There are some dialect-specific shortcuts that we
* could have taken to make the code shorter; however
* we are trying to be as generic as possible here.
*
* - This example assumes integers only. Xbase is admittedly
* awkward for floating point work, other than
* things like currency.
*
* - XBase case statements are not very elegant compared to
* other languages.
*
* - Tested in Foxpro 2.6-Windows and Clipper 5.2
*
Drawing rectangle at (10, 20) Width 5, Height 6 Drawing rectangle at (110, 120) Width 5, Height 6 Drawing circle at (15, 25) Radius 8 Drawing circle at (115, 125) Radius 8 Drawing rectangle at (0, 0) Width 30, Height 15