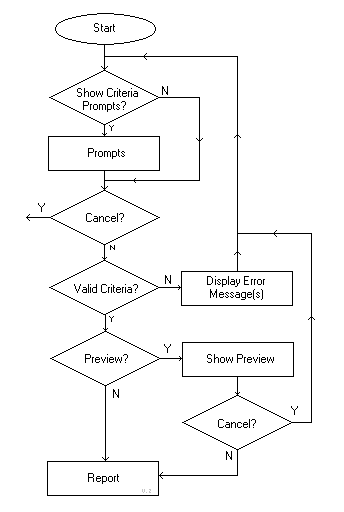
General Flow-chart
Updated: 12/19/2001
The same given report may also be run directly by supplying any report-specific parameters without going through the criteria prompts if desired. For example, the criteria data my come from another screen that is not necessarily dedicated to report criteria. Or, it may be run in batch mode in which the batch script supplies the needed parameters.
If there is physical printing (paper), then a preview option should be available. The preview should allow cancellation of a final print and return to the criteria prompts (if used).
The analysis is to mostly focus on the organization of such a system, and not so much on the mechanics of generating the reports themselves. It should be assumed that off-the-shelf software may be used to actually generate some or all of the reports.
We agreed to try to avoid focusing on specific GUI or reporting API's, although we found this tricky. For there are many nagging details that seem to hinge on the specifics of API's, screen design, and platform capabilities. For example, a design that assumes that each prompt can be validated before the entire prompt screen is finished may not work well in HTTP or some character-based interfaces. To keep the example simple, we will assume only screen-level (submit) validation.
I have created two variations of a procedural/relational version. The first one is mostly code-based, and the second one is table-based in that the report setup and report criteria prompt fields are generally stored in tables instead of code. The tabled example is a web application. A web application was chosen to avoid comparisons related to vendor or OS-specific GUI interfaces. However, it is harder to manage parameters and state in web code. But, comparisons to the non-web version should allow one to envision a client/server tablized version.
Jim translated psuedocode of my first version into a Ruby version. (Although I have a few qualms with it, it is close enough for comparisons to be done. Overall, Jim did a good job at the translation.) I agree with Jim's assessment that it should probably be split into subroutines, which Jim did. However, his justification for his OOP version is weak in my opinion. I will present my reasoning below.
The code-based version is generally targeted for a system that may have a few dozen reports and not likely to greatly exceed that. The tablized version is better geared toward hundreds or thousands of reports. It does this by turning a coding process into a more or less a data-entry process. The specifications for each report is treated as data instead of code.
No user interface, beyond off-the-shelf table browsers, is provided in this example for report setup editing under the tablized version. Whether a table browser alone is sufficient probably depends on staffing arrangements and skills distribution. It probably would not be hard to turn out a set of report management screens using off-the-shelf RAD tools that use tables to generate default/draft screens. I will leave that as a reader exercise.
Both p/r approaches generally have these routines or areas:
The code-based p/r approach is assumed to have each different report in a different module. However, code repeated in each module should be factored to a shared routine (or "include" file). For example, the Flow Controller routine/section would most likely be the same for most reports. It would be a good candidate for such factoring. (Whether a routine or "include" directive is used probably depends on the language being used.)
On the other hand, the tablized version does not have a different module for each report. Most of what is different for each report is factored into tables.
....
if reportID = 37
[do something special]
end if
....
Or
....
if reportID = 37
[do something special]
else
[do normal stuff]
end if
....
If a given features grows more common, then
it can be made into a tablized feature:
if reportID = 37 // before tablization
....
if rs.hasFeatureX // after tablization
....
Note that the "liaison layer" allows the "hasFeatureX" field to be in and move among say the report level or criteria field level without altering such IF statements in most cases. The "access path" to the information is decoupled from the code, reducing the affects of changing which entity a given feature is associated with. (See The Three-Graph Model for more on liaison layers.)OO proponents sometimes cringe at these approaches, but do not offer a satisfactory alternative. One often cannot know where the exceptions will be ahead of time, so one cannot make a clean slot for them in advance. Unexpected alterations or unanticipatable new rules are a fact of life in business applications. Methods for the most part must be either entirely overridden or entirely inherited. However, the difference (exception) may be only in a portion of a method for a given report. See Boundaries and Granularity for more on this. ("Exception" in this context means a "lonely rule", and not an error violation.)
Another way to "organize" exceptions is to put a call to an "exception routine" in key spots. For example, there may be an exception routine for each SQL clause section (whereClause, OrderByClause, etc.) The exception routines could alter such clauses if needed. If the spots are well-chosen, then roughly 80 percent or more exceptions will fall into these. I recommend not putting them in (use IF's instead) until you have some experience with the patterns of the exceptions. The patterns need to be analyzed as they "build up" over time. I suppose an OOP version may use method overriding for similar purposes, but it is harder to factor shared methods. The "CustomFmt()" routine in the Medical Measurement example is an example exception routine.
Here are some possibilities for "intercepting" the SQL generated by the routine GenReport. The interception could take place right before the call to DisplayQuery.
// One-off variation
sql = [regular suff]
if reportID = 14 then
sql = [custom stuff for report 14]
end if
displayQuery sql, title ,100
OR
// Standard feature in Reports table
sql = [regular suff]
if rpt("hasFeatureX") then
sql = [sql for feature X]
end if
displayQuery sql, title ,100
OR
// If many reports need different customization
sql = [regular suff]
customSQL sql, [parameters]
displayQuery sql, title ,100
....
sub customSQL(sql, ....)
if inList(reportID, "14,22,57,102") then
sql = foobar....
end if
if reportID = 67 then
sql = barfoo....
end if
.....
end sub
In the last example, passing all those parameters (such as the parts of an SQL clause) could get a little messy. A nice feature of some languages is the ability to make routines such as CustomSQL a sub-function of GenReport, so that it "inherits" the parent's variable scope. But, VBS does not offer such a feature. Also, it may be argued that CustomSQL should be a function and not a routine. I won't take up the pro's and con's for that here. We used "//" for comments here even though VBS uses different comment syntax.
// Example A
var crit[] // declare dictionary array
crit.clientID = 28
crit.dateLow = "1/1/2002"
crit.dateHi = "2/15/2002"
InvoiceReport(true, true, crit)
// Example B
var options[], crit[] // declare dictionary arrays
options.prompts = true // criteria prompt option
options.preview = true // preview desired
crit.clientID = 28
crit.dateLow = "1/1/2002"
crit.dateHi = "2/15/2002"
InvoiceReport(options, crit)
// Example C
var options[], crit[] // declare dictionary arrays
options.prompts = true // criteria prompt option
options.preview = true // preview desired
crit.clientID = 28
crit.dateLow = "1/1/2002"
crit.dateHi = "2/15/2002"
Report("invoice", options, crit)
// Example D
var handle[] // declare dictionary array
handle!reportID = 17 // The "invoice" report number
handle!prompts = true // criteria prompt option
handle!preview = true // preview desired
handle.ClientID = 28
handle.dateLow = "1/1/2002"
handle.dateHi = "2/15/2002"
Report(handle)
The exclamation marks above are to distinguish between fields (using dots) and settings. It is similar, but reversed, to Microsoft's usage of "!" to separate collections from methods or attributes. However, in my pet language, the exclamation would be a shortcut to a prefix that would distinquish the dictionary key from any likely field name. This avoids the need for nested arrays just to avoid occasional name clashes. See the field identification footnote in Part 2 of the OOP Criticism article for more on the need for this. Some convention for dealing with this issue is helpful for table-oriented programming.Each approach has different merits depending on different factors. For example, having the report name not be part of the subroutine name (like examples C and D) is more conducive to the tablized version, which doesn't have a different code module for each report.
The tablized version would probably not have parameters as shown above. Instead, any criteria values are supplied (updated) to the table. Since the tables are based on a userID, batch operations can be given a special userID. If the need to update parameters in code is common, then some functions to simplify the process could be made. It could even be made to resemble example D above.
def test_criteria
criteria_reader = MockCriteriaReader.new
report = InvoiceReport.new(criteria_reader)
.....
end
As you can see, the interface user has to
initiate and supply a "criteria reader"
object. I believe it also
requires initializing and supplying
a "report writer" object.
This is unnecessary Protocol Coupling in my opinion. It drags the interface user into more than they need to know to perform reporting in most cases. It unnecessarily exposes the internal bureaucracy. Most likely there will only be one "criteria reader" for each report for reasons described under UI Drivers. (Also discussed below.) However, even if there is more than one, it can be selected with a simple attribute:
myReport.criteriaReader = "BobsCriteriaReader" or myReport.criteriaReader = new BobsCriteriaReader()If the interface user does not supply a specific selection for this attribute, then it would have a default. Jim does not even have to give up OOP to achieve this. The key is to simplify life for the interface user. There is no identifiable reason to force the user to have to supply and grok some goofy protocol ("goofy" to the uninitiated, that is).
Jim did hint that his interface could use some simplification, but did not supply any specifics.
Part of the reason for its prominence here is that I more or less have to mirror the type-happy thinking of the external world with regard to RDBMS field types. (Me against the world again, ha ha. Actually I think the SQL field type standards are based on FORTRAN, rather than script-ish languages like Perl or Smalltalk.)
For example, I see no reason why numbers, strings, and dates need to have different delimiters. This was a very change-unfriendly decision on the part of the DB vendors or standards bodies. For instance, sometimes one has to change an ID field from a string to a number or visa versa. Having only one delimiter would eliminate having to change the SQL interface code if such a change was made. (Delimiter should be optional for numbers, and note that some vendors *are* flexible this way. But, it is not part of the standard.)
Even though we have to deal with a type-happy world, the case statements are still not very "symmetrical" (one-to-one list match). Take a look at this snippet from the CriteriaPrompts routine:
select case ucase(rs("fmtType"))
case "T","N","D" ' text, number, or date
hout inputBox("text", fldRef, useValue, useWidth, useWidth)
case "Y" ' Boolean
.....
When I was originally typing in this code, I started making
text, number, and date different case blocks. I then quickly
noticed that their implementation was the same, and factored
them into a single case block. If they were under separate
field-type subclasses (a likely OOP design), then one may
have missed such a pattern because they are so far
apart, and left the duplication
in. (Since it's only one line here, it would not be that
big of a sin in this case, but bigger blocks could happen.)
Further, it would be more code rework to perform such a refactoring in OOP since you would have to make changes to four classes while I only have to change one routine. (Although classes are not fully analogous to routines, you still get similar numbers if you count methods.) A similar issue would happen if they grew different and later had to be split.
An OOP proponent is also likely to say something like,
"If I needed to add a new field subtype, I would only have to add one class. However, you will have to find every routine that has such a case statement and remember to add it. You not only have to remember or find where to add them, but have to change more existing named units (routines or methods) than I have to."This issue is a classic aspect tradeoff. For the reverse is true if one needs to add a new operation that uses the field types. If I added a new operation that used the field types, I would probably not have to touch the existing routines that use them. However, the OOP'er will have to visit and alter potentially every field-type sub-class. The "hop counts" are nearly the mirror image of each other for both approaches. One favors subtype-oriented changes and the other favors operation-oriented (task) changes. See the Shapes Example for a more detailed discussion on these issues.
Note that I have not found the paradigm symmetry for the "spotting similar algorithm" procedural benefit I mentioned above. If there was symmetry, then the OO subtyping approach should make something else easier to spot in exchange. If you find such, please let me know.If there were many prompt "types", or types were added frequently, then I might explore tablizing them. A prompt type table could have attributes such as SQL delimiter and default SQL comparing operator. In this case such is not warranted IMO. New prompt types are likely rare unless somebody is doing something silly. The "exception routines" described above may be able to handle one-off customizations that an overzealous individual might otherwise interpret as a new "type". Roughly 3 or more reports should share an exception before it should be a candidate for a new "type". How different it is in each case statement should also be a factor.
Also see the translation lists notes below.
Supporting multiple UI devices (or interfaces) is a large and tricky undertaking partly because a clean one-to-one translation is usually nearly impossible without accepting limited compromises (such as lowest common denominator). This greatly limits the quantity of different "devices" supported in practice for custom business applications. Thus, the typical OOP approach will not likely win the age-old "new-types-versus-new-operations" battles.
If the context was not custom business applications, then the ratio of new variations (UI protocols/devices) to new operations may be much higher, tilting the benefit weights. For example, perhaps the Crystal Reports company or makers of R & R may face such ratios. The polymorphic approach may indeed work better for them if they target many platforms. But, we cannot necessarily extrapolate the best approach for them to custom applications or frameworks.
For more details on such issues, see the
User Interface Drivers
section of the Driver
document.

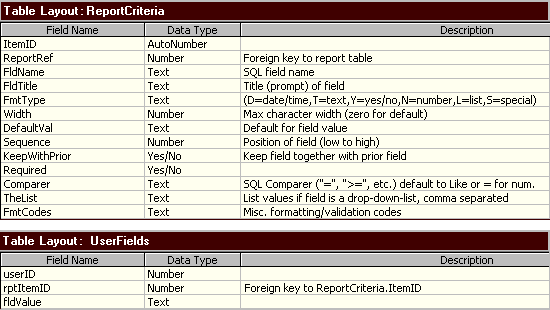
Note: A view of data in the ReportCriteria table
can be found at the
Data Dictionary Example document.

Sample reports list. The last report is
a "hard wired" test.
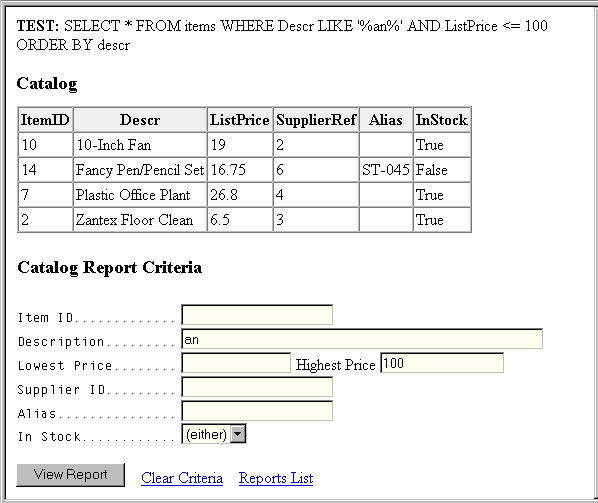
Sample web-based results screen with criteria prompts
and SQL echo.
STATUS CODE TRANSLATION TABLE
Code Description
* (any)
0 Not Reviewed Yet
1 In Review
2 Approved
3 Rejected
4 Approved With Modifications
5 On Hold
BOOLEAN TRANSLATION TABLE
Code Description
* (either)
0 No
1 Yes
Asterisks represents a blank or un-initialized field
and would not be stored in the actual data tables.
This demo does not implement generic translation
lists; but if it did, then the Boolean type could
be implemented by it rather than have a dedicated
case statement item for Booleans. It would also make
it easier to change Boolean conventions to match the
different RDBMS vendors. Perhaps the description
and the code could be considered the same if the
"Code" field is left blank. That way we don't need
to have two "types" of lists (translated and
non-translated). In other words, it would default to using
the description if left blank.
Note that although there may be a Translation table, usage of any table to return key-value pairs should probably be permitted on a "high end" system.
crit.preSeg = ">= '" // note single quote crit.postSeg = "'" ..... // construct a value clause clause = " AND " & fieldName & crit.preSeg & value & crit.postSeg // Ampersand is concatenation symbol hereThis approach resembles the second medical example. I narrowly decided against such an approach here because it makes the table harder to understand. But, it would allow more variations, especially with regard to LIKE expressions. Perhaps one would supply common defaults if the first field was blank. That way only the oddballs would need to fill them in.
Another approach is a reference table with a structure something like:
Table: Comparers
----------------
symbol // unique key
beg
mid
fin
strBeg // for strings...
strMid
strFin
Example Values:
x.symbol = "like"
x.beg = "TOSTR("
x.mid = ") LIKE '%"
x.fin = "%'"
x.strBeg = ""
x.strMid = " LIKE '%"
x.strFin = "%'"
Example implementation:
x = search(table="Comparers", where="symbol=" & sngQuote(sym),
nofind="errRaise(foo)")
result = x.beg & fldName & x.mid & theValue & x.fin
// '&' is string concatenation
Note that this allows string and non-string to use
the same command. Kind of "polymorphic" if you will.
(Of course, this wouldn't be needed if the SQL
committee wasn't type-happy to begin with, as described
above.) An entry called "default" (symbol) could be
what is used if no explicit symbol is given (blank).
contactID in (select clientRef from orders)This is a different approach from having an explicit "Customers" table, a "contact type" indicator code, or a role table. It could be argued that such an approach is slower since it involves a set-based calculation. However, it is more "automatic" in that it is based on a person/contact's behavior instead of an internal classification. Note that a given contact record could potentially also serve as a vendor, shipping destination, an employee, sales contact, etc.