
Updated: 4/18/2004
I will also explore what I consider to be trees' main competitor: sets. Sets are more general-purpose than trees because any tree can also be represented as a set. Although in a "pure tree" situation, sets have more organizational overhead than a dedicated tree, in the real world, sets are often more appropriate because the actual patterns encountered often do not fit nicely into a tree organizational structure. (Almost any structure can technically be forced into a tree. However, the result is often less than optimum.)
I did not start out skeptical of heavy-usage of trees. I had a software-engineering professor in college who always preached the power of trees. Almost every structure and chart was reduced into a tree. It seemed the "Ultimate Universal Structure" at the time.
However, outside the classroom I started seeing drawbacks and limitations to trees. Strangely, people seem to tolerate what to me are runaway vines with no practical way to turn back and clean up. Past a certain size and complexity, trees seem a tangled dead-end. I have since began looking into sets and path-free references as an alternative or supplement to trees.
If sets are so powerful, then what has kept them from wider adoption? Part of the problem is lack of good interface conventions for set management. Suggestions for improving this situation are presented later below.
Let's consider a slide-show file in a hypothetical hierarchical directory:
Server3/Corp/SpecialProjects/Triberium/Bob/slides.shwSuppose this file was the result of a special corporate (main) office research project on a metal alloy initially dubbed "triberium" that process workers suspect may simplify company machinery. The company does not normally do metal R&D, but this discovery was too promising to pass up. Bob was in charge of creating the slide-show to present to investors and partners.
Later, the research project turns into a successful product that the company uses in many of its own products to save money, and licenses it to outside firms also.
That is wonderful news. However, there are some problems with our directory path:
However, it is discovered that the directory structure cannot simply be moved and cleaned up. When they first tried, people complained that they could not find files that they were looking for, such as the Bob's original slide-show. The corporate office got tired of phone calls about the path change, so they put the files back to the original directory, despite the outdated structure of the path.
The path was "book-marked" in various browsers, scripts, personal directory lists, and in people's heads. Moving the files to a different directory will make these paths nearly useless. This is called creating "dead links".
Sometimes one can create a "link directory" from the new path back to the old, so that the new path points to the same place as the old path. However, this is simply a Band-Aid on the problem rather than a real fix. Plus, it just adds more spaghetti to the creeping vine.There is a concept in computer-science called "Law of Demeter" which warns against heavy dependence on the "path" to an item.
Let's assume that the unique identifier is a machine-generated number. Some suggest that a textual name is more user-friendly, but this creates other problems. For one, the name may change. For example, the metal name in our hypothetical case had a name change. Clients sometimes have company name changes, and so do people when they get married. Thus, we'll stick with numbers for now.
In case two file servers are ever merged, perhaps any numbered reference should be required to be preceded by a server identifier. If two servers are later merged, then (at least) one of the prior server identifiers becomes virtual, but still legitimate.
westsrvr:4251/slides.shw
or perhaps something like
westsrvr:4251$slides.shw
Note that this approach does not exclude
the use of hierarchical directories. Using
the Folder-ID is not mutually-exclusive
to other file reference views. It just
allows a more move-friendly reference,
similar to referencing a person via their
social-security-number instead of their
street address. When a person moves into
a different residence, their social-security-number
generally does not change.
Approach A:
Marketing
Horris_Ramen
Brady_Inc
Canada_Travel
Winston_Lauder
Websites
Brady_Inc
Canada_Travel
Winston_Lauder
Approach B:
Horris_Ramen
Marketing
Brady_Inc
Marketing
Website
Canada_Travel
Marketing
Website
Winston_Lauder
Marketing
Website
Good arguments can be made for either arrangement. The
problem here is that we have two orthogonal traits:
internal department and client. Each department
potentially deals with each client.
I have also seen this happen with product category taxonomies. A university bookstore sold many kinds of items: books, mascot clothing, lab and medical equipment, basic medicines (pain relievers, antacids), snacks, etc. The issue came up whether lab coats and medical coats and should go under "clothing" or lab/medical supplies. It is indeed both. However, under a strict tree, it has to go under one or the other.
A non-strict tree may duplicate higher-level categories as lower-level branches. For example, a sub-branch under "Clothing" could be "Lab Supplies", even though there is already a top-level category called "Lab Supplies". This practice of duplicating nodes or node names is often a sign that your tree is out-growing itself.
There was also an annual Halloween sale in which various items were put on sale. (They have a twisted sense of humor since they put real medical supplies into the Halloween sale.) They tried to somehow use the existing product classification tree to propagate which items "inherit" being part of the Halloween sale. Added to this were other discounting conditions and periodic sales.
Managing all these traits via trees was proving to be a can of worms. The problems with large-scale taxonomies and run-away file directories appear to have similar problem patterns, in my experience.
In the above lab coat example, the lab coat products can safely belong to both "clothing" and "lab/medical supplies". It can also belong to the "Halloween sale" set.
Similarly, an anatomy book can belong in both "medical supplies" and "books". We don't have to make any mutually-exclusive (either/or) choices. We are free to include any product in any set we want. (There are times when some sets may be mutually-exclusive; however, this is more related to validation in sets than to classification.)
There are a few issues which set sets back (pun), however. The first is familiarity, and the second is an effective user interface to manage them. The user interface issues will be addressed later.
Thinking in terms of trees is easier for most people it seems. However, I don't know if this is because of exposure to hierarchical file directories and organizational charts (management levels), or some in-born human trait. Some people are initially confused with hierarchical file directories when they first encounter them, but later get used to them. Perhaps the same could happen with sets. More research is needed on this topic.
Now lets move on to the technical guts of sets. How do we represent them internally? Here are some sample tables that illustrate a possible RDBMS arrangement for handling product sets.
CATEGORIES Categ. ID Title --- ---------- 12 Clothing 13 Lab Equipment 14 Medical Supplies 18 Halloween Sale 22 Mascot ... ...etc... STORE ITEMS Item ID Title --- --------------- 351 Scalpel 4A 420 Lab Coat 421 Medical Coat (Doctor's) 630 Mascot T-shirt 657 Mascot Key Chain ... ...etc... CATEGORY CROSS-REFERENCE Item Categ. ID ID --- ---- 351 13 351 14 420 12 420 13 420 18 421 12 421 14 421 18 630 12 630 22 657 22 ... ...
Another way to do it is have a "membership" field in the StoreItems table that lists the set ID's (category) separated by commas. Example: "12,13,18,22". However, this approach is controversial and requires that certain conventions be followed. I find such lists easier to parse if parentheses are used instead of commas. Example: "(12)(13)(18)(22)". However, that takes up more space. Although this approach should be used with caution, it is a technique to keep in mind for certain situations. See also tabled trees.The primary table to pay attention to here is the category cross-reference table. This links the sale items to the category list.I did not show a direct name for the cross-reference table. One possible name for such a table is "category_item_xref". The convention is "tableA_tableB_xref". Naming conventions for such tables can take other forms.
Being a member of "Halloween Sale" does not mean that the item is always on sale. The "rule trigger" should also take into account the date. Example:
HALLOWEEN = 18 // See example tables above if memberOf(item,HALLOWEEN) and month(today()) = "October" then item.price = item.price * 0.9 end if
Another touch-up you may want to consider is a "see also" list for the categories. If somebody is hunting for categories or items, providing a list of other similar categories may help them consider alternatives. Such a list may resemble the cross-reference table in structure.
We can further modify such a table to record multiple kinds of relationships. For example, a relationship between any two categories could be classified as 1) Related ("see also"), 2) subordinate (hierarchy), and 3) Mutually-exclusive. These "hints" can be used to validate the relationship between sets, and may help in navigating them. (More on this later.)
The table layout may resemble:
Table: CategoryRelations ------------------------ Categ_1 (ID of category) Categ_2 RelationCode (r=related,s=subordinate,m=mut.exl.) Rank (float)In our store example, "Earring" could be made subordinate to the "Jewelry" category. "Subordinate" would need to decide on the ordering convention of the parameters. For example, it may be decided that a subordinate code means that category 1 is subordinate to category 2. One may want to also run a periodic or "trigger" check to make sure contradictory relationships are not in the table and to make sure that all parent categories are also included in any product set.

Sets also need a set of agreed-upon (de facto) interface standards before they are more widely accepted. Below are some preliminary suggestions. First, here is one approach to assigning sets to a given item:

This is a typical "picker list" where items from the left side are moved to right side. (We had no budget for alphabetical sorting in our example.) The primary buttons are as follows:
> - Copy selected item(s) to the right < - Remove selected item(s) from the right >> - Copy all items from left to the right << - Remove all items from the rightNote that such a screen is not meant to add or remove the available categories (the ones on the left). It is only meant to assign categories to a given item, such as a directory folder or a store product item. (In a file system, perhaps one could assign categories to individual files, and not just at the folder level, but we will assume folder-level here.)
Next we need a way to search and browse for items based on sets. In the pre-GUI era, some systems used Boolean expressions based on key-words. (Key-words are roughly similar to our categories.) Thus, to search for what we are looking for we could enter Boolean queries resembling:
("Medical Supplies" or "Lab Equipment") and
"Halloween Sale" and not "Books"
This query would search for medical and
lab stuff that is part of the Halloween
sale, except that we don't want any books.
Often times clauses like "not books" are added
after we do our first search, but get
mostly books when we aren't interested
in books. Rather that try to visually
ignore all the books in the search results,
we can add the "not books" clause to our
prior query and re-issue it.
One may notice that many Web search engines allow Boolean searches resembling our example. However, Boolean expressions are generally not required on them, and seem to be falling out of favor as the search engine companies focus on a wider audience who may not be familiar with Boolean expressions.
Boolean expressions are very powerful and flexible. However, in their raw form, they are not very user-friendly. Rather than directly key in Boolean expressions, a "Boolean Search Grid" can instead be used. Here is an example of a 3 x 3 (plus excludes) Boolean Search Grid:
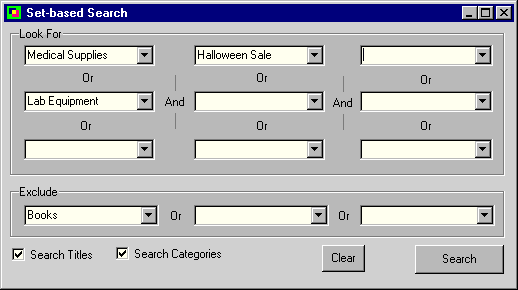
(3 x 3 is not the only possible size.) The chart below shows how to translate the search grid entries into a Boolean search expression.
_________________
A D G
B E H
C F I
_________________
J K L
_________________
(A or B or C) and (D or E or F) and (G or H or I)
and not J and not K and not L
If we eliminate the non-filled letters, you can
see that the example translates to:
("Medical Supplies" or "Lab Equipment") and
"Halloween Sale" and not "Books"
Note the two check-boxes on the above form.
The "Search Titles" check-box indicates what
we want to also search titles for the given
category names (as words). Titles could be
the store product name in the store example,
or folder name, or even file name in the
directory example. In other words, it could
also allow text searching in addition
to set searches. The second check-box
("Search Categories") would allow one to
perform only text searching if they wanted.
Perhaps a pull-down selection list could be used instead of these two check-boxes. However, it may confuse or distract the user because there are already a bunch of pull-down lists. Further complicating this issue is the potential usage of key-words as search parameters. More on this is presented below.If title searches are also allowed, then the drop-down boxes should be "combo-boxes", which also allow words to be keyed in by the user, in addition to being selected from a pre-defined list.
One thing is still missing in that the tree browser has is a visual representation. The outline format visually resembles the actual structure. Our Boolean Search Grid is still mostly based on words and not on any visual layout that relates to something about the categories themselves. This is an area that needs more research. I am not sure how a visual representation of set relationships would work in a practical setting. Something resembling Entity-Relationship GUI tools for RDBMS management come to mind. The "hint" fields (described above under "Getting Fancy") could perhaps be used to determine the distance, positioning, and/or strength of drawn relationships between categories and/or items.
Fortunately, trees views and sets are not mutually-exclusive. A tree can still be set up in which each tree node references a category (set). The drawback is that such a tree would probably have to be manually maintained. The "hints" fields (described above) may assist with such a task, but in the end a human needs to keep such a tree clean.
One advantage of sets is that it is generally easier to rearrange a tree view without upsetting existing set-based classifications. One can change the levels and branches around any way they want. They only have to make sure that each tree node points to the right set.
Trees may also be helpful at organizing the classifications (sets) themselves if the category list gets large. It might be that each department in an organization can have custom trees. After all, the marketing department way not want to by default see stuff in the "Human Resources" category.
Picture the above "Set Picker" screen-shot with an outline-format tree browser in the left panel.
However, keep in mind that a tree view should not be the only view. One should also be able to view by alphabetical order, recency (by date-time), sub-string, etc. In other words, all the typical "table browser" operations.
Let's revisit the slide-show example introduced earlier. How would it play out in a set-based classification environment? Looking at the original tree path, we see these candidates for sets:
Of these original candidates, only "Metal" would remain after the change-over; which is fine because the others have ceased to apply, at least from a formal set perspective.
Key-words are also a form of sets. Perhaps rather than make a distinction between key-words and sets, some way can be made to consolidate them. Keywords tend to be more specific than what I envisioned as sets. Perhaps the distinction does not have to be Boolean. A "specificity" rating could perhaps be used. For example, 0 for general, 1 for specific, and 0.5 for something in-between. This may make it easier to present top-level "directories" without specific sets cluttering up such lists. The viewing specificity threshold could be altered to fine-tune what is being looked at. Of course, more research is needed in this area.
Whether and how individual persons, such as Bob, would be related to formal sets also still needs some study and experimentation. Because people's roles often change, perhaps more generic titles should be used as sets, and not individuals.
For example, different departments may store information about a given client or product. Often times one may want to search by client regardless of which department it is in. In fact, entire products have been created to address specific information grouping issues, such as "Customer Relationship Management". Perhaps if organizations used set-based information management, they would not need to implement aspect-dedicated systems such as these.
Greater power and flexibility often comes at the expense of greater training. Getting used to sets may take a while. Perhaps sets may initially suffer from the QWERTY Effect. The original QWERTY keyboard, the lettering layout in the most common usage today, is not the most efficient. However, learning alternatives may not pay off if very few offices use it. It may take a few brave pioneers to take the first steps and break in set technology. Perhaps large content management companies may be the first to try it. Key-word based systems are already in fairly wide usage in such companies.
The amount of information that companies need to manage is only going to increase. The cost of obtaining and storing information is constantly going down. However, the techniques for managing such information have remained fairly static. New techniques are going to be needed in order to more effectively manage all this information. Tree's best days are behind them.
Table: Articles --------------- articleID articleTitle content authorRef // reference to Authors table (not shown) postedDate Table: Categories ----------------- catID catTitle catNotes Table: ArticleCategories -------------- articleRef catRef acRank // optional Table: SeeAlso -------------- articleRef1 articleRef2 saRank // optionalThe last two tables are many-to-many tables, which allow a given article to belong to multiple categories and have multiple "see also" links to other articles. Ideally, the Category links would be enough such that we would not need "see also" links, but in practice I have still found a need for such links.
Also, perhaps some approach to making a primary category for a given article should be supplied. One approach is to put an "isPrimary" flag in the ArticleCategories table; another is to have a "PrimaryCatRef" foreign key in the Articles table. A 3rd alternative is a "link rank" value (usually floating point or decimal), as shown above. The highest value is the "primary". (RDBMS constraints may be needed if we don't want ties. Decimal is safer to compare for ties than floating point. Generally one should never compare for equality using floating point values.)