Language corpora are becoming available cheaply, sometimes free. The likely impact on language teaching will be profound--indeed the whole shape of linguistics may alter at speed. (Sinclair, 1997, p. 38)
One of the leading figures in corpus linguistics applying machine-readable collections, Leech (1997a), defined a corpus as "a body of language material which exists in electronic form, and which may be processed by computer for various purposes such as linguistic research and language engineering" (p. 1). The theoretical underpinnings, the technical development, and the study of such corpora have gained considerable ground in the past decades, signaling a trend away from decontextualized linguistics toward a study of language that takes account of context based on what is often referred to as "real" language. This chapter will review the growing literature that has given evidence of this enterprise.
The chapter is divided into six sections. The first will offer a discussion of the theoretical issue of performance versus competence, focusing on the contrasting views of Chomskyan generative linguistics and corpus-based linguistic analysis (2.1). Section 2.2 will be based on a brief historical overview of major corpora as it clarifies the types that have been established recently. The next section (2.3) identifies the issues of representative design, and some technical details of corpus development. Section 2.4 further narrows the scope by identifying a link between computer-assisted language learning and data-driven learning. Section 2.5 reviews work in the field of learner corpus linguistics, centering on the International Corpus of Learner English project. Finally, I will identify the benefits of applying corpora in language studies in section 2.6.
The concepts, definitions, and processes reviewed in this chapter will be central to the presentation of writing pedagogy at Janus Pannonius University and to the description and analysis of the JPU Corpus.
In the field, two competing traditions have emerged: 'asocial' linguistics that incorporates intuition to capture generic features and universals of language and of particular languages, and 'social' linguistics that investigates generic and language-specific notions based on observations of utterances (Wardhaugh, 1995, pp. 10-12). In the former paradigm, linguistic inquiry springs from a need to establish sufficient elements that can adequately describe the grammar of language; the latter engages the actual language community (or population) and extracts from it a corpus that is then used to test hypotheses. This section will offer a brief evaluation of these two traditions.
The most influential theoretical linguist of the twentieth century is Noam Chomsky, whose generative grammar is embedded in the asocial tradition. In defining linguistics as the study of grammar, he developed a set of strict principles and operators that language employs in generating all possible and grammatical utterances (Chomsky, 1957; 1965). The main focus, then, is on what is possible. This represents one of the main differences between the asocial and the social paradigms. In socially embedded linguistics, it is not only what is possible that is studied, but also what is probable. According to Kennedy (1998) this does not mean that linguistic theory does not benefit or is not "compatible with" (p. 8) the study of a corpus. On the contrary; as science requires evidence with which to refute or support a hypothesis, corpus linguistics provides a rich set of such evidence that allows for generalization.
As Fillmore (1992) noted, the two types of linguist should ideally "exist in the same body" (p. 35). Contrasting the images and concerns of whom he called an "armchair linguist" and a corpus linguist, Fillmore pointed out that no corpora will ever offer all the evidence linguistics needs, but also that corpora have allowed linguistic scholarship to establish new facts about language, facts that one "couldn't imagine finding out about in any other way" (Fillmore, 1992, p. 35). But he also called attention to the importance of introspection and analysis by a native-speaker linguist. Biber (1996) also suggested that both generative linguistics and variation studies looking at linguistic performance derived from corresponding aspects of linguistic competence represent valid positions.
The call for a combination of the two approaches is based on the assumption that native speakers are competent decision-makers on issues of syntax. While the claim may be a perfectly valid one, I would like to raise an issue related to the theoretical limitations of the basis of linguistic inquiry. As no corpora can ever fully represent the language performance of a community (see, for example, Partington, 1996, p. 146), so, too, are introspective linguists limited in their competence (Labov, 1996). This adds further support to the claim that theoretical linguistics and corpus linguistics can and should co-exist.
Such co-existence occurs in a social context. The notion of context (or setting) in which language competences materialize (Hymes, 1974) as well as its central importance, was further highlighted by Sinclair (1991), who claimed that as introspective linguists do not, as a rule, require a discourse context for their own examples, the naturalness of the evidence suffers. Defining this feature of an utterance as a choice of language that is appropriate to the context, Sinclair observed that because of the difficulty of simulating context, examples are often unlikely "ever to occur in speech or writing" (1991, p. 6). This is why, he went on to argue, linguistics should be careful not to misrepresent what it aims to describe. In other words, what may be authentic (in that system, possible) to the individual linguist in a particular context for supporting a particular claim may not be authentic (in that system, probable) to the language community.
In terms of language education, corpus linguistics has helped direct attention to what constitutes authenticity of material, learning experience and classroom language, key factors determining the relevance of learning especially in the communicative language teaching tradition. A direct result of the approach is what data-driven learning and the development of learner corpora have achieved (discussed in detail in 2.4 and 2.5). One of the proponents of this approach, Johns (1991a), posited that learning, especially on advanced levels, can greatly benefit from assisted and direct manipulation of corpus data. He argued against the stance held by such figures of applied linguistics as Widdowson (1979; 1991) who placed the emphasis not on authenticity of material but of learning experience, arguing for the use of simplified texts to help ensure authenticity and comprehensibility at the same time for the learner. As a consequence, he cast doubt on the relevance of corpus findings to the process of teaching and learning foreign languages (Widdowson, 1991). Calling attention to the principle of pedagogic relevance, Widdowson made the following point:
Language prescription for the inducement of learning cannot be based on a database. They cannot be modelled on the description of externalised language, the frequency profiles of text analysis. Such analysis provides us with facts...but they do not of themselves carry any guarantee of pedagogic relevance. (1991, pp. 20-21)As opposed to Widdowson, Johns (1991a) argued that authentic and unmodified language samples were essential in language learning. Widdowson (1979, 1991) focused on the learners' need to exploit materials that represent authenticity of purpose and were within their grasp. In Johns's argument, the requirement of no modification is central. For learning material to represent full authenticity, the original purpose and audience should not be altered. Schmied (1996) took a stance whereby the corpus can be instrumental with pedagogical relevance still maintained. In his view, examples and materials derived, and, as need made this necessary, modified from a corpus still had applicability: Adaptation is possible to various learner development levels, but the example used to illustrate a language pattern may be valid if it comes from a corpus (Schmied, 1996, p. 193).
Taking a position similar to that expressed by Widdowson (1991), Owen (1996) criticized the application of corpus evidence in language education when it negated the appropriacy of intuition. Describing the problem of an advanced FL student who was primarily interested in receiving prescription, rather than description, Owen argued that teachers' experience with language and roles as standard-setters should not be ignored. He went on to claim that teachers can hardly clarify usage problems for their students based entirely on consulting a corpus. In fact, he suggested,
the tension between description and prescription is not automatically relieved by reference to a corpus. Intuitive prescription is fundamental to the psychology of language teaching and learning....Even if teachers had the time to check every prescription they want to make, the corpus would not relieve them of the burden of using their intuition. (Owen, 1996, p. 224)This evaluation of a practical concern is in line with what other experts, such as Fillmore (1992) and Summers (1996), claimed. Biber (1996) summed up the advantages of text-based linguistic study. He identified four features that make the corpus linguistic endeavor particularly relevant. These were the following:
According to Kennedy (1998), there were five main applications of these pre-electronic corpora:
The development of dynamic digital corpora had its theoretical and experiential foundations in the pre-electronic projects, together with a growing awareness of the need to accumulate larger collections that can be captured and stored on computer to facilitate faster access, more refined analyses, and thus more reliable and valid information drawn from these studies. With the simultaneous advance that information technology made, this was a time of convergence of linguistic interest and technological potential.
The Brown Corpus was developed to represent as wide a variety of written American English as was possible at the time. With the enormous task of transferring analog data into an electronic format done manually, the achievement is still considered a major one. The Brown Corpus contains such additional information as origin of each sample and line numbering.
With these two language analysis resources, linguists had the opportunity to compare and contrast written U.S. and U.K. English texts, exploiting frequency and co-text information (for a comparison of frequency, see Kennedy, 1998, p. 98). Besides, the careful study of hapax legomena, word forms that occur once in a corpus, which typically represent the majority of types of words in most large corpora, was now possible, with implications for lexicography, collocation studies and language education.
The influence of these two first-generation corpora proved long-lasting: not only did they set standards for representation and structuring in sampling, but they also gave rise to other corpus projects of regional varieties. These included the Indian English Corpus published in the late 1970s and the New Zealand and Australia Corpora of English, each of which aimed to be modeled on the first two corpora. For the first time in linguistics, a large collection of objective data was available. But this was relative: they also contributed to the realization that the upper word limit of one million words was a restriction that had to be re-assessed and abandoned: for analysis to be based on more representative samples, linguists needed larger sets, especially for studying lexis that occurred less frequently in earlier corpora, and for contrastive analyses across the subcorpora.
Work on corpus development sped up in the eighties, fueled partly by the recognition that studies incorporating objective evidence made investigations more valid and reliable, and partly by the increasing facility with which to store and manipulate data. Innovations such as optical readers and software opened up the new vista of exploiting more spoken language. These developments gave rise to second-generation corpora, each based on earlier work but with different purposes and corresponding sampling principles. Another major difference between first- and second-generation corpora lies in the acceleration with which the results of linguistic analysis were incorporated in applied linguistics and language pedagogy. Of these new efforts, three projects stand out as most influential: the Bank of English, the British National Corpus, and the International Corpus of English. In each project, the activity of a national or international team, the funding of major academic and government organizations, and the economic viability of the results in the publication market continued to be operational factors.
Directed by Sinclair, the corpus was renamed in 1991 the Bank of English, and by now has reached a state whereby every month, some 2 million new words are added. The team repeatedly made "the bigger the better" claim, meaning that for truly reliable accounts of lexis and grammar, large collections are necessary. The current size is 500 million words of written and spoken text, with storage on high-tech media, including the internet. To serve the growing body of researchers and teachers, a sample of 50 million words, together with concordance and collocation search engines, is available via the COBUILD Direct service of the web site at http://titania.cobuild.collins.ac.uk (reviewed by Horváth, 1999a).
As Sinclair noted (1991), data collection, corpus planning, annotation, updating and application continued to challenge the team. Seeking permission of copyright holders has always been among the hurdles, but there are signs of a changing publishing policy that may allow for automatic insertion of a copyrighted text for corpus research purposes.
The Bank of English has continued to innovate in all the related work: in the way corpus evidence is incorporated in learner dictionaries, in study guides and recently in a special series of concordance samplers, in the application of a lexical approach to grammar (Sinclair, 1991), and in the theoretical and technical field of marking up the corpus. Analyzing discrete meanings of words, collocations, phraseological patterning, significant lexical collocates and distributional anomalies makes available a set of new results that shape our understanding of language in use. As the reference materials produced are based on a constantly updated corpus, new revisions of these materials sustain and generate a market, making the venture economically viable, too.
The BNC was among the first megacorpora to adopt the standards of the Standard Generalized Markup Language (SGML more about annotation in Section 2.4) as well as the guidelines of the Text Encoding Initiative, which aims to standardize tagging and encoding across corpora. By so doing, not only has the BNC become a representative of a large corpus that has made use of earlier attempts to allow for comparability, but it also has sought to become a benchmark for other projects (Kennedy, 1998, p. 53; "Composition of the BNC," 1997). A sample of the corpus and its dedicated search engine, SARA (Burnard, 1996), have been made available at the web site http://info.ox. ac.uk/bnc.
The pedagogical use of the BNC has already received much attention, with Aston (1996, 1998) describing and evaluating the benefit advanced FL students in Italy gain in how they conduct linguistic inquiries. Aston reported that by accessing and studying this large corpus, students were highly motivated, primarily because of their critical attitude to published reference works that they can contrast with the results of their own conclusions.
The ICE project assembles text samples that represent educated language use; however, the definition of this notion is not left to the individual (subjective) decision of participating teams. Rather, the corpus will structure the language production of adult users of the national varieties of the regions. According to Greenbaum (1996a, p. 6) the texts included would be by speakers or writers aged 18 or over, with "formal education through the medium of English to the completion of secondary school." As the regional 1-million-word corpora will include written texts, identifying such factors will prove a rather difficult undertaking indeed.
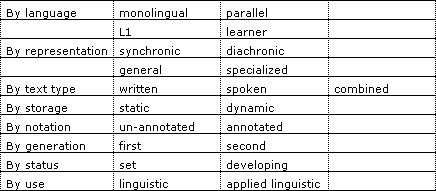
Table 2: A typology of corpora
The steps of developing these corpora and the technology used to maintain them will be reviewed in the following section.
The cyclicity of corpus development is a requirement as often, either the population to be represented or the text types generated cannot be defined strictly in advance. To be able to adjust preliminary concepts, a pilot study is required that can inform the effort of the population and language variables to account for. Theoretical analysis can confirm and refine initial decisions, but it may also introduce new sampling procedures. When this phase has been finished, the next step is corpus design proper. This involves the specification of the length of each component of the text (with minimum and maximum word counts), the number of individual texts, the range of text types, and the identification and testing of a random selection technique that gives each potential text an equal chance of being selected for the corpus.
During the third stage of the cycle, a subcorpus is being collected and the specifications are tested in it. This occurs in the fourth phase when an empirical investigation takes place with specifications studied and compared with the samples, and statistical measurements are taken to determine the reliability of representativeness. For any text that does not meet the requirements of the design, the specifications need to be revised, and either new design principles are identified or the problematic text is omitted. With each new sampling of a smaller unit of the corpus, constant checks and balances are in place to ensure the theoretical and empirical viability of the linguistic study that the corpus aims to serve. The Biber model is summed up in Figure 2.

Figure 2: Biber's (1994, p. 400) model of cyclical corpus designWord frequency counts are strong indicators of reliability. For most general corpora, and especially those that aim to serve as bases of language teaching materials, such as learner dictionaries, establishing the frequencies of words is one of the main concerns. As this information has to be based on reliable sources, studies in representativeness provide a major contribution. According to Summers (1996), this information can then be applied in framing dictionary entries objectively and consistently, providing a dictionary that can list lexical units within a single entry according to frequency. Yet, she added, there is
still a need to temper raw statistical information with intelligence and common sense. The corpus is a massively powerful resource to aid the lexicographer, which must be used judiciously. Our aim at Longman is to be corpus-based, rather than corpus-bound. (Summers, 1996, p. 262)The compilation of small and large corpora was described in detail by Inkster (1997), Krishnamurthy (1987) and Renouf (1987a). One concern after the design principles have been set is that the spoken and written texts to be collected can be stored on computer; another is that what is stored there be authentic. The incorporation of electronic media poses little challenge: besides obtaining the permission of copyright holders, one needs only to ensure that the text is in a compatible format with the program used for accessing the corpus. The capture from CD-ROMs is one such relatively trouble-free area. But the compilation of non-electronic forms of texts, such as the transcription of spoken material and the typing in (or keying in) of manuscripts is far more prone to introducing error into the corpus.
Errors occurring during the entry of a text into the database should be avoided as this would defeat the purpose of representation. This is why developers need to put in place and regularly check procedures that help maintain an error-free corpus. The clean-text policy is one such procedure (Sinclair, 1991): manuscripts and other texts to be input are double-checked in the corpus.
Besides the procedural approach of designing a corpus and the need for limiting errors, the markup of the raw corpus is the third crucial area of dealing with general and specialized corpora. Most present-day corpora make extensive use of some annotation system that assigns one tag from a set of categories to units occurring in individual texts (Garside, Leech & McEnery, 1997). This process, the annotation of the corpus, aims to interpret the data objectively. Annotation can be viewed as adding a metalanguage to the language sample in the corpus, often in some form of the Standard Generalized Markup Language (SGML), an international standard.
By adding linguistic data to the raw text, a subjective element is incorporated in an otherwise objective entity. According to Leech (1997a, p. 2), there "is no purely objective, mechanistic way of deciding what label or labels should be applied to a given linguistic phenomenon." Leech focused on three purposes of corpus annotation:
Origin/NN of /IN state/NN automobile/NN practices/NNS ./. The/DT practice/NN of/IN state-owned/JJ vehicles/NNS for/IN use/NN of/IN employees/NNS on/IN business/NN dates/VVS back/RP over/IN forty/CD years/NNS ./.Grammatical notation generally makes use of both automatic and manual techniques: special parsing computer software can be programmed to apply probabilistic techniques in determining classes of words. A second-generation megacorpus, the BNC, was annotated in such a way. It consists of two types of labels: header information (such as source of text) and the tagged text, using the system known as Claws (Constituent Likelihood Automatic Word-tagging System), which resulted in fairly reliable notation; according to Garside (1997), the accuracy rate was 95 percent or higher.
As an innovative empirical effort, Garside, Fligelstone and Botley (1997) provided an example of annotating discourse information in a corpus. Whereas most other levels of tagging can benefit from high technology, the area of cohesive relations poses major difficulties. Reviewing models of markup, the team worked out a fairly consistent method and an additional set of guidelines that may be further trialed and adjusted. Already, the notation system can describe such elements as antecedents and noun phrase co-reference, central pronouns, substitute forms, ellipses, implied antecedents, metatextual references, and noun phrase predications. Any unit not adequately captured is noted by a question mark. Although the authors recognized that the field of discourse annotation "is at a fairly immature stage of development" (Garside, Fligelstone, & Botley, 1997, p. 83), exploiting SGML and refining the tagging algorithm may achieve the sophistication of other levels of annotation.
The program used for this dissertation was Conc 1.7, a Macintosh application that can process text files limited only by the size of the computer's hard disk and memory allocation. Minimally, the program requires 512 kilobytes of memory, and 160 KB of hard disk space. Conc was developed by the Summer Institute of Linguistics in Texas in 1992. I selected this shareware utility for its user-friendliness and reliability: during the five years of using it, it has proved stable. As the corpus analyst inevitably will have to share disks with others, another consideration was that of platform stability: In the Windows/Intel world, shutdowns resulting from malicious computer viruses have become a frequent occurrence. By contrast, the Macintosh system is virtually free of such troubles. Here is a description of the features Conc offers, together with screen shots that illustrate them.
For the description, I selected an earlier version of the first paragraph of this chapter: a 153-word minitext. After saving this paragraph in text-only format, I launched the concordancer and opened the file. The window presented in Figure 3 appeared.

Figure 3: The example text in Conc's main windowWhen generating a word concordance output to screen, the user has the option of sorting identical words (types) according to the words that follow them or according to their position in the original file. As Figure 4 shows, I selected the former choice.

Figure 4: Part of the Sorting Parameters dialog window in ConcAs users may not wish to display all words occurring in a text, the program lets them deselect words from the concordance. Three options are available for this, as Figure 5 demonstrates. When none of the options are selected, the program performs a full concordancing of the text. A combination of word omission features, however, makes it possible to focus, for example, on hapax legomena (by selecting the Omit words occurring more than 1 times option) or on words that occur a number of times and which are longer than six letters.

Figure 5: The dialog window where words may be omitted from the concordanceAnother module lets the user define the filling of the display space, given in radio button options: all of it could be filled with the concordance lines, resulting in truncated words; only full words could be shown; or the program could compute a compromise between the two options. A typographical standard is presented in the check box to show key words in bold face (see Figure 6).

Figure 6: Part of the Display dialog box on the Options menu in ConcWhen such parameters have been set, the program is ready to sort the text file accordingly. A new window appears as a result, of which Figure 7 presents a part.

Figure 7: Part of the Concordance window of the programIt is in the Concordance screen that the user can first study the co-texts of the keywords, shown in bold face, and centered as key word in context (KWIC) concordances. When a co-text does not reveal sufficient information, and thus should be enhanced with the fuller context, one can switch between the main window and the Concordance window. With the appropriate line of the concordance output selected, the main window can be superimposed and the full sentence studied. This is shown in Figure 8.

Figure 8: The Concordance and the main windowsConc 1.7 can provide one type of index for texts: alphabetical. As this can be saved to a text file, a database program can be used for sorting words by frequency. (This procedure will be described in Chapter 4). Figure 9 displays a screen shot of part of the Index window. First-occurrence word lists and frequency lists can be generated directly in other programs.
Figure 9: The Index window's scrolling list of the alphabetical index of the fileSimple statistical word count information is also provided. The example paragraph used contained 153 tokens, 90 types (see Figure 10).
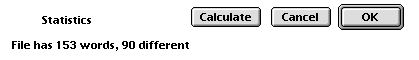
Figure 10: Part of the Statistics window on the Build menuThere are several file management options that Conc 1.7 provides. New files can be added to texts, another may be opened, a selected concordance can be saved or printed, current parameters can be saved as default options. Of course, the full concordance can be exported, too (see the menu selection screen shot in Figure 11).
Figure 11: The File menu of Conc
To achieve this aim in a comparative study that investigates a set of linguistic features across texts in a corpus or between corpora, Biber, Conrad and Reppen (1998) described the procedure whereby a so-called normalization of linguistic variables is performed. In essence, this involves the identification of a unit of the text that will serve as the basis of comparison. Table 3 shows one example of such a normalized comparative analysis. In this analysis of three news items and three conversations (identified as text files in the first column and as labels in the second), the length of each text is given in a word count (in column 3). For each of the three observations (verbs, adjectives and pronouns), the unit of analysis was one thousand words; the numbers indicate the occurrence of these types in each of the six texts per 1,000 words. Normalization applies a simple formula. The frequency of the observation is divided by the word count and multiplied by the unit in which the linguistic feature is analyzed. Normalization, then, refers to the process of establishing comparability among observations. According to Biber, Conrad and Reppen (1998 p. 263), it is a "statistical process of norming raw frequency counts of texts of different lengths." The results of normalization (the rates) for these observations are the quantitative data that can be compared across the texts, using statistical methods.
Table 3: An example of normalized comparative analysis (based on Biber, Conrad & Reppen, 1998, p. 273)

One type of the frequently extracted statistical information is the mean score of individual items. Not only can the normalized frequency information on individual variables within a text be informative, but also the mean score, for example, of text length within a register and across registers. Once mean averages are computed, comparisons can be done. Studying Table 3, for example, we have evidence to suggest that news tends to have more past tense than do conversation text types.
Statistical measures such as the mutual information score and the T-score, the analysis of variance (ANOVA) of lexical collocation, and chi-squared counts are used to determine whether a linguistic phenomenon occurs merely by chance or whether it is statistically significant. Corpus linguists have increasingly sought to establish whether any observed difference between normalized frequency counts is the result of chance, or whether there is statistically significant correlation between them. Such measurements have long been applied in other social sciences, and there has been growing linguistic interest in them (Biber, Conrad, & Reppen, 1998; Clear, 1993; Kennedy, 1998; Koster, 1996; McEnery & Wilson, 1996).
In both the language software and its way of delivery, many CALL practitioners assumed that extended time spent online would result in better performance. Although there was little scholarly attention focusing on the effectiveness of CALL in the 70s and early 80s (reviewed by Chapelle & Jamieson, 1989), anecdotal evidence and the enthusiasm of scores of language educators and of students continued to attract financial and pedagogical investment. Stevens (1989), however, remarked that much CALL experience in the U.S. and elsewhere failed to revitalize the behaviorist orientation that assumed that learning will take place when discrete steps are planned properly. This is somewhat surprising, considering the amount of work put in this enterprise, and the expansion of the approach supported by such organizations as TESOL and IATEFL. Arguing for a shift in this paradigm, Stevens called for computers and software in language education to be viewed and applied as facilitators of what he called humanistic learning.
This call for a pedagogical change meant that CALL software and its application had to be based on much more concrete applied linguistic principles. Although attention to sound methodological grounding was called for as early as 1986 by Jones, much CALL business remained within the confines of the grammar-translation tradition. Stevens (1989), aiming to synthesize SLA theory, specifically the hypotheses of Krashen (1985), summed up the features that were worth exploiting as follows. First of all, CALL software had to be able to create intrinsic motivation for the learner. In other words, such courseware would need to be relevant to student needs, offer authentic tasks, and create a no-risk environment, resulting in a low affective filter. Second, he proposed that CALL applications develop more fully the interactive potential of the technology. For example, programs can do this by adjusting their routines based on the input of the individual student, a principle gaining ground in computer-adaptive testing much more effectively than in teaching. Finally, Stevens made a call for non-CALL programs; the value of eclecticism lay, he argued, in that software "designed for other audiences and purposes" (1989, p. 35) could and should be adopted in the language class.
Wolff (1993) shared this view of applicable technologies in language learning. Also concerned with more direct integration of SLA research, he identified four principles for exploiting information technology in language education (p. 27):
DDL is viewed (Farrington, 1996; Sinclair, 1996, 1997) as a possible "new horizon" in CALL because it offers the foreign language student opportunities to engage in authentic tasks in a low-risk environment, truly interacting with authentic texts, and using appropriate tools. In short: DDL, in many ways, incorporates the values Stevens (1989) set forth. Without the rapid development in the field of corpus linguistics, however, and without its many lexicographic and grammar applications, the approach would not have become so effective. Johns (1991a) attributed the growing interest in DDL specifically to the COBUILD project.
DDL, which may be regarded as a subdivision of CALL, first appeared in the late 80s, early nineties in Johns' work with international students studying at British colleges (1991a, 1991b). Drawing on the results that CALL had established in the U.S. and the U.K. (Higgins & Johns, 1984; Pennington, 1989), he helped set up a program that would provide what he called "remedial grammar" tools and training for science students. Johns argued that advanced EFL students had a need to directly exploit the growing evidence a corpus was able to provide. He offered a model (shown in Figure 12) to explain the nature of language awareness processes taking place in such a context.

Figure 12: Johns's model of data-driven learning (1991a, p. 27)As Johns was primarily concerned with the development of language awareness as it related to the needs of advanced students, he hypothesized that those who aimed to develop accuracy in the foreign language had to be able to understand the relationship between how functions of discourse are realized in forms, and how these forms are interpreted to satisfy them. Data is crucial in such a process: rather than inventing examples to explain to students how this happens, students and teachers need hard evidence of how forms are used in context. This is the rationale for the central position of data, with the roles of the student enriched by that of the researcher during the participation in classroom concordancing activities (such as those described in Tribble & Jones, 1990).
Data is authentic unmodified language extracted from a corpus (Johns, 1991b, p. 28). In Johns's remedial grammar and academic writing classes, students were actively involved in accessing, manipulating and exploring this data, partly by online classroom concordancing, and partly by participating in individual and pair work activities based on new types of exercises developed to take account of the data. One corpus used in the project was a 760,000-word sample of the journal New Scientist.
Data drives learning in the sense that questions are formed in relation to what the evidence suggests. Hypotheses are tested, examples are reviewed, patterns and co-texts are noted. The collaboration that evolves between students and the teacher who may not know the answer without also consulting the corpus carries a further innovative element of this approach. Students also have the opportunity to focus on clearly defined units in the data (Higgins, 1991; Kowitz & Carroll, 1991; Stevens, 1991). A spin-off of the approach was presented by Johns (1997a): new CALL programs, such as his Contexts, can be designed by incorporating concordance tasks piloted in the classroom.
The materials developed are another outcome of the approach. The technique of on-line concordancing has allowed for the generation of new task types, such as the one keyword, many co-texts activity, or the concordance-based vocabulary tasks described by Stevens (1991). Corpora also allow for the development of innovative and potentially effective approaches to and applications of pedagogical grammars (see, for example, "The Internet Grammar of English," 1997 Hunston & Francis, 1998). Also, research investigates how what is presented in traditional language coursebooks may or may not be supported by the evidence of the corpus (Sinclair, 1997; Mindt, 1996, 1997). As DDL and corpus evidence in general become mainstream, as was suggested by Svartvik (1996), new FL materials, too, will benefit from the approach.
Gavioli's (1997) example offered yet another insight into the application of concordancing activities in language education. She introduced multilingual corpus analysis processes and interpretation tasks designed for a course of translators in Italy. Gavioli emphasized the importance of consulting reference materials to test hypotheses about language use. By analyzing and interpreting data in a corpus, and by corroborating their own discoveries, students can become the ones who describe features of language, rather than being offered such descriptions. The singular contribution of these applications of corpus materials in language education is the exploration of authentic texts that raise awareness of significant patterns used in natural contexts. As suggested by Kennedy (1998), such inductive use of corpus texts in classroom concordancing helps FL students to "locate...all the tokens of a particular type which occur in a text...and note the most frequent senses" (p. 293), thus discovering collocational and colligational features. Leech (1997b) and Kirk (1996) were among those positing such applications as experimentation with real language, besides recognizing their value in academic study. Kirk underscored the change this brought in language teachers' roles: as teachers' roles are enriched by being providers of an authentic resource, they can co-ordinate research initiated by students (1996, p. 234). Clearly, this has the additional benefit of empowering students, mostly on intermediate and advanced levels, so they can gain experience in a new skill, too.
Another value of DDL lies in the manner in which teachers can establish and maintain a classroom-based research interest themselves. By applying corpora in their syllabus design and class materials development efforts, they are bridging the gap between research and pedagogic activities, a trend welcomed by Dörnyei (1997) and Ellis (1995, 1998), among others. One example of such involvement was offered by Tribble (1997), who described an innovative use of a multimedia product whose text component was used as a corpus. The author proposed that teachers who find it difficult to access large corpora or who do not regard the use of a one as relevant can use multimedia encyclopedias as language learning resources. Targeting EFL students beginning to work with academic writing, the syllabus incorporated the multimedia product Encarta, a set of hypertexts, movies and graphics containing such diverse text types as, for example, articles by experts in the fields of physical science, geography, history, social science, language and performing arts. Tribble claimed that using this resource not only caters for diverse student interests in the writing course but can result in their recognition of different text organization and lexical preferences in descriptive and discursive essays, process descriptions, physical descriptions and biographies.
The main objective is to gather objective data for the description of learner language, which Granger (1998a; in press) saw as crucial for valid theory and research. Besides, the ICLE's contribution has been in directing attention to the need for observation of this language so that the notion of L1 transfer may be analyzed under stricter data control. The obvious potential outcome is for materials development projects, which will help specific classroom practices. (Longman Essential Activator, 1997, was among the first dictionaries to incorporate learner data derived from the LonLC.) Focusing on error analysis, and interlanguage (Selinker, 1992), the ICLE-based project enables researchers and educators to directly analyze and compare the written output of students from such countries as France, Germany, the Netherlands, Spain, Sweden, Finland, Poland, the Czech Republic, Bulgaria, Russia, Italy, Israel, Japan and China.
Part of the ICE project, the developers of ICLE identify the origins of interest in the analysis of learner language in early error analysis SLA studies. Granger pointed out (1998a) that although the investigations and theoretical explanations made about learner errors were grounded in data observation, the corpora for those studies did not take full account of the variables that affected the samples. For example, the number of students, their learning experience and often non-comparable test elicitation techniques raised doubts about the reliability of some of those observations. By contrast, the ICLE project has worked out a system of sampling scripts that allows for more reliable studies in the description phase as well as in contrasting individual subcorpora and a subcorpus with an L1 corpus. With each script, detailed information is recorded in the contributor's profile. This not only ensures that the data comes from a valid source, but also allows for specific analyses of types of language use in clearly defined subcorpora. The descriptors include, according to Granger (1996, p. 16):
First, as a number of the assignments do not appear to involve much of the students' own deliberation as they present an argument that they need to support, no matter what their own positions, the validity of a text being a student's "own" is dubious. Even if students have the chance of choosing a title or a theme, they cannot "entirely own" their writing as they play a limited role in deciding on the focus of their essays. For this reason, the title "Europe" may be regarded of the suggested ones as the most authentic: it does define a clear enough focus, allowing students to develop an argument which is truly their own, yet specific for any lexical or rhetorical analysis when the text becomes part of the corpus.
As for the pedagogical implications of the preferred mode of submitting a student's "own" essay with "no help...sought from third parties," the authenticity of the task may be lessened. With so much written production viewed and undertaken as a collaborative process effort in the L1 field, it is somewhat surprising that no peer or teacher involvement is allowed. The specification also raises the issue of audience: the themes appear to favor the production of writer-based prose; yet the task is defined as an argumentative one where awareness of the position of the audience is crucial. Furthermore, why deny the opportunity of consulting a reader before the script is finalized if one were to follow, even for such a basically product-oriented enterprise as corpus development, a process syllabus? Considering the role that editors, colleagues and publishers play in the finalization of the written work of L1 authors (represented in L1 corpora), it stands to reason that such restriction in the development of L2 corpora may bias the comparative analyses.
These constraints notwithstanding, the ICLE has ushered in the time of interest in more specific analyses of learner language. Each of the national subcorpora will be about 200,000 words, allowing for grammatical and lexical investigations, but small for research into words and phrases of lower frequencies (Granger, 1996, p. 16). However, the project has been instrumental in helping an international team of researchers and teachers to join forces in the field, and in leading the way to new inquiries: for the development of more specialized ESL and ESP corpora. Another area where the ICLE has motivated research is the advanced spoken learner corpus and the intermediate corpus, both under development. Work on L2 corpora is gaining recognition, and the practical implications of these efforts may be seen shortly in the new reference and teaching materials that take account of L2 learners' language use (Gillard & Gadsby, 1998; Granger, 1998a, 1998b; Granger & Tribble, 1998; Kaszubski, 1997, 1998).
Interest in applying corpora in linguistic analysis and materials development is on the rise in Hungary, too. Studies that are partly or entirely based on such corpora as the Bank of English represent a new trend in current Hungarian linguistics. Among these, Andor (1998), for example, applied a sample from this corpus, together with data elicited from forty native speakers of English, in the study of the mental representation and contextual basis of ellipsis and suggested that a combined use of psycholinguistic and corpus linguistic research methods would enable linguists to arrive at more valid and reliable conclusions. Csapó (1997) studied the viability of the convergence of pedagogical grammars and learner dictionaries, whereas Hollósy (1996, 1998) reported on work to develop a corpus-based dictionary of academic English.
The framework of DDL and the increasing interest in analyzing learner English on the basis of learner corpora will be applied in the following chapters: the next describing and analyzing writing pedagogy at the English Department of Janus Pannonius University, and the fourth giving an account and analysis of the JPU Corpus. The study of learner scripts contributes to the authenticity of writing pedagogy: those who collect, describe, and analyze L2 texts can test, in a valid and reliable way, hypotheses of the effectiveness of writing pedagogy. Also, such collections can serve as a basis of an innovative type of learning material that can be applied directly in the writing classroom.