We need more genre-sensitive studies and more specialized corpora in addition to the larger representative corpora as a basis for analysis. (Kennedy, 1998, p. 291)
A solid set of data was collected between 1992 and 1998, facilitating a quantitative analysis of the language produced. The approach followed in this chapter is based on the corpus linguistic assumption that the performance of a language community has to be investigated to capture probable features of language behavior, whose statistical and pedagogical significance can then be tested and validated.
Why and how the corpus was first conceived will be discussed in section 4.1, which also explains design principles, data input procedures, text types, and the three types of methods used for the empirical study. Section 4.2 then goes on to present the current composition of the main corpus, followed by the specific compositional details of the five subcorpora. After this presentation, section 4.3 identifies ten hypotheses of this part of the dissertation. Descriptive and contrastive analyses were carried out, involving the full JPU Corpus, its subcorpora, and contrastive analyses based on the results of ICLE investigations.
The chapter then follows up to address the pedagogical uses of the corpus: section 4.4 introduces an application of data-driven learning, whereby students are assisted in submitting their own scripts to analysis. Specific examples will illustrate how this has been done in Language Practice, Elective and WRS courses for group activities and for individual study. The section briefly discusses miscellaneous other applications of the corpus. I hope this presentation will serve as a valid basis on which to draw conclusions, in section 4.5, on the applications and limitations of a corpus-based study of written learner English--besides, I intend to suggest future directions where such endeavors may lead.
I saw in this program and the lexical and syntactic investigations it made possible a wealth of pedagogical applications. Imagining how JPU English majors in the Fall 1992 Language Practice course could benefit from its use, I began to read the literature on corpus linguistics and DDL. Saving my earlier essays and papers as ASCII, I loaded my first own small corpus of my own work and saw, fascinated, features I would not have thought I could see or wanted to see before. But now I could and did. And I was convinced students could and would, too. With two groups in September 1992, I became the first tutor at the ED of JPU to explore the potential of analyzing authentic native speaker (NS) text and non-NS text by computer.
As my primary interest was the analysis of learner English for language education purposes, I proposed to the students in the two groups that they submit their written contributions on computer disk (Bocz & Horváth, 1996). Looking back, the positive response continues to strike me as incredible. After all, those were not the times of wide access to computers--in fact, there were few even in department offices, with the first portable units just arriving. However, students consented, and I made time available for brief practical typing and word processing sessions. From that time on, there have been a growing number of students who have submitted texts on disk, permitting me to save their files onto the hard disk of the computers I used at the time.
The current status of the development of the JPU Corpus may be regarded as satisfactory for a linguistic and language educational study. It is the first to employ a large database of Hungarian learner English for descriptive and analytic purposes, which represent the ultimate rationale for corpus development.
Specifically, collecting students' scripts enables applied linguists to do the following:
In the rest of this chapter, I will restrict the investigation to demonstrating what I considered relevant analyses given the individual undertaking of the project.
In my effort, I was led by the following considerations. I envisaged a corpus that would
As for the third criterion referring to text types, a representative sample of different genres has been collected, with corpus linguistic and pedagogical aims in what can be regarded as sufficient balance. None of the students have been asked to allow me to reveal their authorship of any examples to be shown in this chapter--the names that appear in the Acknowledgments cannot be linked to the scripts. Finally, all text samples that appear in the current version of the JPU Corpus are voluntary contributions--most solicited by asking students to sign a permission form. Details on these six considerations will follow in the rest of the section.
-- Figure could not be converted--
Figure 22: The process of data input
The JPU Corpus is a semi-annotated collection: it has author, gender, year, course, and genre information tagged to it, but it does not take advantage of any of the robust tagging techniques available today. There is a disadvantage and an advantage to this lack. Without word class or grammatical tags, the corpus cannot in its present form allow for fully reliable, automatic processing and information output. However, in the vein of Fillmore's (1992) claim on the "armchair" linguist and the corpus linguist having to exist in the same body, this limitation may be viewed as a potential advantage: the partial reliance on intuition, based on pedagogical practice and observations, and on linguistic evidence may make up for the present lack of the tagging component. (However, as Labov, 1996, suggested, when intuition and introspection are employed, the following principles should be observed: the consensus, the experimenter, the clear case, and the validity principles.)
Not only was the change a result of making the project fully legal, but it was also based on a socialization consideration. I made the move to ask for official permits so as to contribute to the sense of professional community among students and teachers. Familiarizing with the concept and practice of copyright was seen as an additional element of language education at the department. Further, the decision was supplemented by suggesting to students that they submit their printed assignments with a © notice. For one thing, not many students knew what exactly the symbol represented and how this related to academic standards of free expression and of text ownership. Some may even have found the proposal superfluous, thinking that the teacher was making too much fuss. But when one considers the problems of copyright infringement in many subcultures, and specifically the occurrence of plagiarism at Hungarian universities, my approach arguably promoted an authentic experience of being initiated into the scholarly community. 4.1.5 Clean text policy Data capture was done relatively fast. Students who were willing to contribute to the corpus were asked to submit scripts on computer diskette. In the beginning, both standard size DOS-compatible disks were used, with the transition to 3.5-inch disks exclusively taking place in 1994. When I was handed a disk, I checked it for any problems such as viral infection and incompatibility. The former issue had been safely eliminated by early 1995 when I began to store scripts on an Apple Macintosh computer. Fortunately, viruses cannot engage their malicious operation across platforms; this was a crucial technical issue for the sustained development of the corpus. It also meant that once I had saved a student's file to the hard disk, no lurking viral programs were transmitted to the student's disk either.
However, incompatibility of proprietary word processing software code in the text file was harder to overcome. For the first two years, before word processing software became widely available in educational institutions, I had had to exclude texts that could not be converted properly. More recently, I have been using shareware programs for any text file that my word processing programs could not extract.
When the technicalities are taken care of, real work on text preparation for corpus inclusion can begin. This process serves three functions: recording contributor data in the corpus database, ensuring that the content of the file is compatible with the concordancing application, and editing the text for authenticity.
The first function presents no hurdles: I have used the computer's file system hierarchy to maintain the database. Figure 23 illustrates, via a screen shot of a window on the Macintosh desktop, the file hierarchy concept.
As will be detailed in section 4.2.1, the corpus is divided into five subcorpora. The screen shot shows one of the folders highlighted, and the contained folders listed, storing files by semester, then by gender, and finally by text type.
The second function is also relatively straightforward once the file is saved locally: Conc, as most other concordancing software, can process data saved as ASCII, or text-only files.
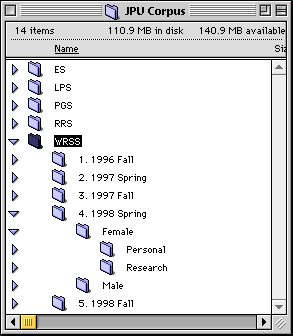
Figure 23: A window of part of the corpus in the Macintosh file system
The third function, however, is much more time-consuming, given the short experience most students have had with word processing. Much as one of the requirements for most submissions in the past five semesters has been for students to check their texts for typing and spelling errors, some have continued to submit files that needed careful editing. Deciding whether an error was a typing or a spelling mistake has not always been easy. Yet, I have worked out a procedure that may be regarded as reliable.
I decided to take action and change text only if the error was clearly a typing mistake. This meant changing words like "langauge" to "language" or "teh" to "the." That is, transposed characters were always amended. The clean text policy of the JPU Corpus project meant that no other mistakes were corrected so that the data would remain as authentic as possible (a similar approach was employed for text handling in the ICLE project see Granger, 1998a). Finally, texts were edited by removing any author identification from the header, such as bylines, and components such as course codes, any graphics, tables and references.
In contrast, a research paper is a submission for which the writer has to follow academic standards: identifying a field of study and a research question, presenting the method for answering the question, and putting forth its data and analysis to answer it. It is typically supplemented by reference materials to be collected on the basis of the readings section of a syllabus and as the writer's own initiative. In most regards, the research paper can be viewed as a small-scale thesis, or as one of the body chapters in a thesis. (Figure 24 illustrates the curricular composition of the scripts.)
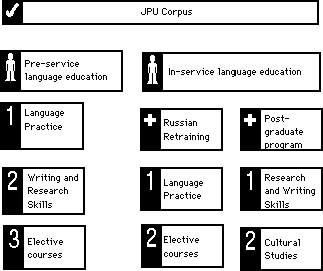
Figure 24: Curricular and course origin divisions of the scripts
In terms of actual procedures used, I have employed two corpus linguistic techniques, two statistical models, and one language educational approach. As for the corpus linguistic techniques, I distinguished between operations on the complete corpus and on various samples. Data processing was carried out via Con 1.7: I opened each of the 332 files in the program, sorted the text alphabetically right to the keyword, and saved the KWIC concordance. This stage provided the raw material for concordance analyses and other techniques. To collect information on the composition of the full corpus, I also saved the alphabetical index that the program can provide, together with information on tokens and types. The same procedure was performed on each of the subcorpora.
A limitation of Conc is that it cannot automatically produce a frequency list. This, however, posed no difficulty as a database application, FileMaker Pro, has this tool. I opened each of the alphabetical index files for the main corpus and the subcorpora and sorted the contents by the frequency of words.
With these operations done, I printed KWIC and frequency list pages to study their content. Online searches were also carried out.
It was at this stage that common corpus linguistic techniques were performed: KWIC analyses, calculating normalized frequencies, comparing most frequent word forms, and drawing up the statistics for lemmatized words in the main corpus and the subcorpora.
These steps were taken to have a large set of materials on which to test hypotheses--of which those that required statistical verification were loaded into a spreadsheet program to obtain significance information via the chi-squared test and ANOVA. The former model, used for observations in the JPU Corpus and between the PGS and the WRSS, makes no assumption about the normal distribution of data and can be applied for frequency comparisons based on different size corpora (McEnery & Wilson, 1996, p. 70). The latter is suitable for studying the effect of variables across three or more populations, using interval scales (Koster, 1996).
Finally, the third type of method used for this study comprised the production and evaluation of classroom worksheets that have been piloted in earlier courses, as well as the development of material to illustrate how such an approach can be exploited for guiding individual study.
With these methodological considerations, we can now move onto the specific details of the current state of the corpus.
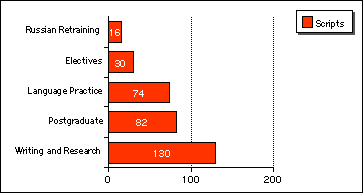
Figure 25: The number of scripts contained in the five subcorpora
The Russian Retraining subcorpus (RRS) is the smallest unit, with two types of text: Language Practice personal descriptive and argumentative essays by twelve female students and one male, and semi-research paper essays by three female students of elective courses. I consider this component of the corpus valuable even though its size is small: it records the performance of students who participated in a study that has been discontinued since. Somewhat larger than the RRS is the Electives subcorpus (ES), comprising 30 scripts. Most were submitted by females: 21 academic essays on CALL, Indian Literature, the application of the internet in language learning, and DDL. The other nine texts, by male students, are of similar types.
A significantly more representative sample is structured in the Language Practice subcorpus (LPS): the texts are personal descriptive, narrative or argumentative essays. This is also the subcorpus with the most significant male student population: 31 male and 43 female authors are represented.
The two most sizable subcorpora are the Postgraduate (PGS) and the Writing and Research Skills (WRSS) collections. In terms of number of scripts and types of words, the WRSS is more representative, with its 130 texts (by 106 female and 24 male contributors). The text types represented by the WRSS are personal essays (23), with the rest of the collection (107 scripts) made up by research papers. (For more details on types of research paper in the subcorpus, see the sections on hypotheses 9 and 10.) However, in terms of tokens, the PGS is larger: with 82 students (68 female, 14 male) contributing to this subcorpus, it is made up by 123,459 words. The relative significance of each of the five subcorpora is demonstrated in Figure 26: it charts the JPU Corpus by number of scripts in them.
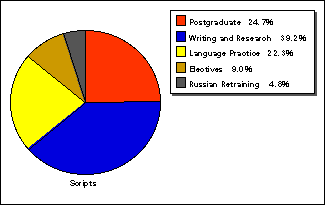
Figure 26: Distribution of texts in the subcorpora according to number of scripts
Figure 27 also illustrates the distribution of texts in the five subcorpora, this time calculated by tokens of words in them.
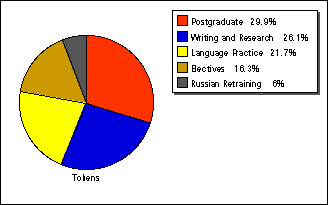
Figure 27: Distribution of the texts according to number of tokens in the subcorpora
Altogether, the five subcorpora are made up by 17,535 types of words (that is, distinct graphic word forms), a relatively high number. The PGS is ranked number one for both number of tokens and ratio (see Table 10); it already appears that the papers in that subcorpus contain relatively more homogeneous texts than the second largest, the WRSS.
Table 10: Statistics of scripts in the five subcorpora

Table 11 shows gender representation in the JPU Corpus. As can be seen, over three-fourths of the students are women: 76.2% as opposed to 23.8% men. This appears to be in line with the general demography of the ED of JPU.
Table 11: Gender representation in the JPU Corpus

To provide a preliminary overview of the content of the corpus, Tables 12 and 13 list the most frequent words and the most frequent content words. In studying Table 13, one has to note that raw word forms do not provide sufficient detail on word class--as a result, tables listing raw frequency data represent only the basis of further analysis (cf. Kennedy, 1998, p. 97). For reliable lexical analysis, lemmatization has to take place.
Table 12: The 20 most frequent words in the JPU Corpus
| Rank | Word | Frequency |
| 1 | the | 32231 |
| 2 | of | 14757 |
| 3 | to | 11602 |
| 4 | and | 10835 |
| 5 | in | 9102 |
| 6 | a | 8526 |
| 7 | is | 6409 |
| 8 | it | 4149 |
| 9 | that | 4123 |
| 10 | I | 3695 |
| 11 | are | 3265 |
| 12 | they | 3195 |
| 13 | not | 3041 |
| 14 | for | 2981 |
| 15 | be | 2916 |
| 16 | this | 2759 |
| 17 | with | 2755 |
| 18 | as | 2732 |
| 19 | was | 2566 |
| 20 | on | 2521 |
Table 13: The 20 most frequent content words in the JPU Corpus
| Rank | Word | Frequency |
| 1 | students | 2164 |
| 2 | writing | 1552 |
| 3 | essay | 945 |
| 4 | language | 898 |
| 5 | people | 773 |
| 6 | English | 747 |
| 7 | different | 746 |
| 8 | time | 729 |
| 9 | use | 680 |
| 10 | words | 660 |
| 11 | like* | 651 |
| 12 | paper | 606 |
| 13 | introduction | 587 |
| 14 | make | 554 |
| 15 | write | 553 |
| 16 | work | 549 |
| 17 | way | 539 |
| 18 | used | 531 |
| 19 | text | 524 |
| 20 | reading | 506 |
Note: Like appears as a preposition and subordinating conjunction 371 times.
The twenty most frequent words total 15,494, or 3.76% of all tokens. In terms of content words, we can see that several words in Table 13 belong to the semantic field of writing; this indicates a marked use of such vocabulary, not surprisingly, in the WRSS and PGS (see also sub-sections on these two subcorpora later).
As attested by all corpus analyses, the most frequent word forms are represented by function words--this can be seen in Table 14, which lists the ten most frequently occurring types across the five subcorpora. The number one position of the definite article and the frequency of prepositions are not surprising; what is worth noting is the high rank of the first person singular pronoun in the PGS and the WRSS; the sections that describe the composition of those units will provide a reason for this occurrence.
Table 14: The ten most frequent words in the five subcorpora
| Rank | Postgraduate | Writing | Language P | Electives | Russian |
| 1 | the (9615) | the (8912) | the (6640) | the (5352) | the (1679) |
| 2 | of (4357) | of (3980) | of (3178) | of (2561) | and (770) |
| 3 | to (3636) | to (2941) | to (2461) | to (1868) | to (691) |
| 4 | and (3297) | and (2835) | and (2174) | and (1758) | of (691) |
| 5 | in (2758) | in (2323) | a (1908) | in (1569) | in (569) |
| 6 | a (2596) | a (2165) | in (1852) | a (1389) | a (468) |
| 7 | is (1930) | is (1318) | is (1615) | is (1127) | is (418) |
| 8 | I (1761) | that (1165) | that (1051) | it (681) | his (273) |
| 9 | are (1180) | I (1127) | it (1018) | that (648) | he (272) |
| 10 | it (1124) | it (1110) | are (835) | be (549) | they (244) |
In developing the JPU Corpus, one of my early aims was to test the accuracy of the use of the definite article, the most frequent word in any corpus; also, the word that appears to be least taught, relative to its importance and frequency. However, the sheer size of the corpus has made it a daunting task to conduct such an analysis on the present untagged corpus--still, as will be shown later in this chapter, such information was obtained on the RRS.
Over seven thousand of the word forms (7,522) occur only once in the JPU Corpus. As Table 15 illustrates, the most significant representation of such lexis can be seen in the Russian Retraining subcorpus--this adds support to the observation that the shorter the text, the most likely it is to be made up by such word forms.
Table 15: Rank order of the five subcorpora according to ratio of hapax legomena
| Subcorpus | Number of hapax legomena | Ratio of hapax legomena |
| RRS | 2070 | 8.41% |
| ES | 3580 | 5.33% |
| LPS | 3814 | 4.26% |
| WRSS | 4163 | 3.86% |
| PGS | 2854 | 2.31% |
This tendency can be further highlighted by comparing the rank order of the subcorpora according to ratio of hapax legomena and number of tokens: see Table 16.
Table 16: Contrasting the rank orders of the subcorpora by hapax legomena (HL) and tokens (T)
| Subcorpus | Rank by HL | Rank by T |
| RRS | 1 | 5 |
| ES | 2 | 4 |
| LPS | 3 | 3 |
| WRSS | 4 | 2 |
| PGS | 5 | 1 |
Although my study cannot be concerned with comparing the lexis of the JPU Corpus with any large non-specialized NS corpus, I submitted the frequency list of the JPU Corpus to a rank-order analysis, based on Kennedy's (1998, pp. 98-99) table of the top fifty words in six corpora. Of these, I selected the rank-order lists for the Birmingham (Bank of English) Corpus, the Brown Corpus, and the LOB Corpus. Then I rank ordered the words that are common to the Birmingham and the JPU Corpus, to identify the word forms whose ranks showed similarity and differences. The two parts of Table 17 list the rank orders for the four corpora.
Table 17, Part 1: The rank orders of the most frequent words in three large corpora and the JPU Corpus: Ranking from 1 to 25 (Based on Kennedy, 1998, p. 98)
| Word | Birmingham | Brown | LOB | JPU |
| the | 1 | 1 | 1 | 1 |
| of | 2 | 2 | 2 | 2 |
| and | 3 | 3 | 3 | 4 |
| to | 4 | 4 | 4 | 3 |
| a | 5 | 5 | 5 | 6 |
| in | 6 | 6 | 6 | 5 |
| that | 7 | 7 | 7 | 9 |
| I | 8 | 20 | 17 | 10 |
| it | 9 | 12 | 10 | 8 |
| was | 10 | 9 | 9 | 19 |
| is | 11 | 8 | 8 | 7 |
| he | 12 | 10 | 12 | 40 |
| for | 13 | 11 | 11 | 14 |
| you | 14 | 33 | 32 | 58 |
| on | 15 | 16 | 16 | 20 |
| with | 16 | 13 | 14 | 17 |
| as | 17 | 14 | 13 | 18 |
| be | 18 | 17 | 15 | 15 |
| had | 19 | 22 | 21 | 47 |
| but | 20 | 25 | 24 | 26 |
| they | 21 | 30 | 33 | 12 |
| at | 22 | 18 | 19 | 34 |
| his | 23 | 15 | 18 | 44 |
| have | 24 | 28 | 26 | 25 |
| not | 25 | 23 | 23 | 13 |
Table 17, Part 2: The rank orders of the most frequent words in three large corpora and the JPU Corpus: Ranking from 26 to 50 (Based on Kennedy, 1998, pp. 98-99)
| Word | Birmingham | Brown | LOB | JPU |
| this | 26 | 21 | 22 | 16 |
| are | 27 | 24 | 27 | 11 |
| or | 28 | 27 | 31 | 22 |
| by | 29 | 19 | 20 | 33 |
| we | 30 | 41 | 40 | 42 |
| she | 31 | 37 | 30 | 70 |
| from | 32 | 26 | 25 | 29 |
| one | 33 | 32 | 38 | 28 |
| all | 34 | 36 | 39 | 45 |
| there | 35 | 38 | 36 | 36 |
| her | 36 | 35 | 29 | 93 |
| were | 37 | 34 | 35 | 39 |
| which | 38 | 31 | 28 | 27 |
| an | 39 | 29 | 34 | 31 |
| so | 40 | 52 | 46 | 65 |
| what | 41 | 54 | 58 | 49 |
| their | 42 | 40 | 41 | 24 |
| if | 43 | 50 | 45 | 60 |
| would | 44 | 39 | 43 | 74 |
| about | 45 | 57 | 54 | 30 |
| no | 46 | 49 | 47 | 84 |
| said | 47 | 53 | 48 | 317 |
| up | 48 | 55 | 52 | 81 |
| when | 49 | 45 | 44 | 54 |
| been | 50 | 43 | 37 | 107 |
One reason to do this was that, although the four corpora represent different language community varieties and text types, I intended to gather data on personal pronoun distribution. In particular, the relative ranking of the masculine and feminine pronouns was an area of interest: as the table shows, in all four corpora, he is ranked over 20 positions higher than she.
After this introduction of major features of the corpus, I will present specific information on each of the five units. (The most frequent word forms occurring at least 100 times in the JPUC appear in Appendix M, pp. 220-222.)
Table 18: Word forms occurring 100 times or more in the ES
| the | (5352) |
| of | (2561) |
| to | (1868) |
| and | (1758) |
| in | (1596) |
| a | (1389) |
| is | (1127) |
| it | (681) |
| that | (648) |
| be | (549) |
| as | (489) |
| for | (489) |
| not | (481) |
| with | (480) |
| are | (473) |
| this | (439) |
| was | (431) |
| can | (411) |
| on | (393) |
| they | (380) |
| their | (349) |
| by | (327) |
| or | (316) |
| but | (284) |
| from | (267) |
| an | (265) |
| which | (263) |
| have | (257) |
| one | (257) |
| language | (252) |
| his | (240) |
| students | (240) |
| he | (215) |
| at | (209) |
| i | (201) |
| there | (188) |
| were | (184) |
| had | (183) |
| more | (181) |
| its | (180) |
| also | (168) |
| all | (165) |
| these | (154) |
| other | (152) |
| about | (149) |
| has | (148) |
| when | (146) |
| time | (142) |
| them | (141) |
| if | (137) |
| most | (137) |
| some | (130) |
| only | (129) |
| may | (127) |
| two | (127) |
| who | (122) |
| would | (121) |
| teacher | (119) |
| teachers | (119) |
| britain | (118) |
| her | (116) |
| out | (116) |
| learners | (112) |
| english | (107) |
| she | (106) |
| you | (104) |
| into | (101) |
| been | (100) |
Table 19: Word forms occurring 100 times or more in the LPSS
| the | (6640) |
| of | (3178) |
| to | (2461) |
| and | (2174) |
| a | (1908) |
| in | (1852) |
| is | (1615) |
| that | (1051) |
| it | (1018) |
| are | (835) |
| not | (779) |
| they | (749) |
| for | (742) |
| be | (729) |
| as | (655) |
| this | (645) |
| with | (620) |
| on | (558) |
| can | (516) |
| have | (515) |
| or | (474) |
| but | (457) |
| i | (457) |
| their | (457) |
| was | (457) |
| one | (377) |
| we | (361) |
| he | (357) |
| from | (351) |
| people | (346) |
| which | (337) |
| about | (331) |
| by | (327) |
| you | (327) |
| at | (323) |
| more | (318) |
| there | (302) |
| all | (300) |
| an | (300) |
| other | (281) |
| she | (281) |
| students | (278) |
| them | (278) |
| his | (264) |
| so | (255) |
| only | (250) |
| these | (248) |
| some | (244) |
| who | (243) |
| group | (242) |
| also | (241) |
| has | (238) |
| do | (237) |
| if | (233) |
| were | (231) |
| will | (226) |
| would | (223) |
| because | (205) |
| what | (205) |
| most | (200) |
| time | (196) |
| her | (194) |
| course | (187) |
| had | (187) |
| like | (187) |
| when | (181) |
| very | (164) |
| dallas | (163) |
| our | (163) |
| life | (162) |
| no | (161) |
| even | (156) |
| student | (155) |
| way | (154) |
| could | (153) |
| well | (151) |
| coffee | (147) |
| than | (143) |
| its | (142) |
| up | (141) |
| my | (138) |
| use | (131) |
| many | (130) |
| should | (129) |
| been | (128) |
| first | (126) |
| out | (126) |
| different | (125) |
| two | (124) |
| language | (123) |
| how | (119) |
| any | (118) |
| always | (115) |
| get | (114) |
| news | (114) |
| cards | (112) |
| much | (111) |
| new | (109) |
| children | (107) |
| good | (107) |
| important | (107) |
| those | (105) |
| world | (104) |
| every | (103) |
| such | (102) |
| your | (102) |
| family | (101) |
| make | (101) |
| after | (100) |
Table 20: Word forms occurring 100 times or more in the WRSS
| the | (8912) |
| of | (3980) |
| to | (2941) |
| and | (2835) |
| in | (2323) |
| a | (2165) |
| is | (1318) |
| that | (1165) |
| i | (1127) |
| it | (1110) |
| they | (880) |
| was | (848) |
| on | (764) |
| not | (761) |
| this | (695) |
| for | (687) |
| students | (682) |
| with | (650) |
| as | (638) |
| be | (620) |
| are | (584) |
| one | (584) |
| essay | (555) |
| or | (547) |
| about | (523) |
| their | (503) |
| writing | (497) |
| were | (489) |
| an | (455) |
| from | (449) |
| which | (444) |
| have | (443) |
| at | (439) |
| can | (427) |
| but | (416) |
| them | (397) |
| by | (381) |
| only | (373) |
| these | (355) |
| essays | (349) |
| how | (341) |
| had | (339) |
| more | (335) |
| there | (332) |
| first | (324) |
| my | (320) |
| two | (316) |
| all | (301) |
| he | (270) |
| also | (261) |
| who | (252) |
| most | (248) |
| other | (248) |
| out | (234) |
| because | (229) |
| news | (225) |
| what | (222) |
| some | (214) |
| you | (208) |
| when | (205) |
| do | (200) |
| if | (197) |
| could | (196) |
| will | (195) |
| three | (194) |
| well | (190) |
| so | (188) |
| did | (187) |
| words | (187) |
| people | (184) |
| student | (182) |
| english | (181) |
| use | (181) |
| we | (181) |
| paper | (179) |
| articles | (177) |
| time | (176) |
| different | (168) |
| research | (168) |
| hungarian | (165) |
| between | (164) |
| has | (163) |
| his | (163) |
| she | (163) |
| write | (162) |
| than | (161) |
| introduction | (157) |
| used | (156) |
| would | (156) |
| make | (154) |
| topic | (151) |
| word | (147) |
| up | (146) |
| verbs | (146) |
| year | (144) |
| many | (143) |
| course | (142) |
| paragraph | (140) |
| work | (139) |
| university | (138) |
| those | (130) |
| found | (129) |
| should | (128) |
| find | (127) |
| like | (127) |
| into | (126) |
| number | (125) |
| page | (125) |
| information | (124) |
| same | (124) |
| four | (122) |
| no | (120) |
| made | (119) |
| question | (119) |
| article | (115) |
| its | (115) |
| second | (115) |
| day | (114) |
| any | (111) |
| five | (111) |
| way | (111) |
| writer | (111) |
| text | (110) |
| events | (109) |
| sentences | (108) |
| after | (107) |
| conclusion | (106) |
| each | (106) |
| papers | (105) |
| results | (104) |
| such | (103) |
| last | (102) |
| reader | (101) |
| sentence | (101) |
| according | (100) |
Table 21: Word forms occurring 100 times or more in the RRS
| the | (1680) |
| and | (770) |
| to | (691) |
| of | (680) |
| in | (569) |
| a | (468) |
| is | (418) |
| his | (273) |
| he | (272) |
| they | (244) |
| it | (210) |
| their | (203) |
| for | (199) |
| that | (199) |
| not | (195) |
| are | (191) |
| as | (191) |
| this | (181) |
| was | (168) |
| with | (168) |
| can | (167) |
| but | (144) |
| i | (139) |
| be | (138) |
| which | (126) |
| or | (122) |
| from | (119) |
| on | (111) |
| about | (110) |
| have | (106) |
| by | (105) |
Table 22: Word forms occurring 100 times or more in the PGS
| the | (9615) |
| of | (4357) |
| to | (3636) |
| and | (3297) |
| in | (2758) |
| a | (2596) |
| is | (1930) |
| i | (1761) |
| are | (1180) |
| it | (1124) |
| that | (1059) |
| they | (942) |
| be | (869) |
| for | (864) |
| writing | (857) |
| with | (837) |
| not | (823) |
| this | (795) |
| my | (769) |
| as | (757) |
| or | (731) |
| on | (694) |
| can | (692) |
| students | (680) |
| was | (662) |
| have | (660) |
| which | (584) |
| their | (569) |
| about | (498) |
| but | (479) |
| an | (476) |
| them | (451) |
| from | (448) |
| we | (448) |
| one | (443) |
| these | (443) |
| there | (442) |
| introduction | (396) |
| more | (393) |
| paper | (379) |
| language | (375) |
| by | (373) |
| what | (371) |
| first | (359) |
| at | (352) |
| how | (341) |
| some | (341) |
| english | (335) |
| words | (335) |
| text | (332) |
| different | (331) |
| were | (328) |
| book | (322) |
| write | (316) |
| reading | (311) |
| when | (309) |
| two | (299) |
| other | (289) |
| tasks | (282) |
| only | (281) |
| will | (254) |
| sentences | (253) |
| do | (252) |
| had | (250) |
| essay | (246) |
| use | (246) |
| if | (244) |
| because | (243) |
| all | (241) |
| style | (234) |
| most | (232) |
| also | (230) |
| sentence | (224) |
| topic | (223) |
| so | (218) |
| has | (215) |
| work | (205) |
| used | (203) |
| research | (202) |
| texts | (202) |
| make | (197) |
| grammar | (196) |
| should | (196) |
| out | (193) |
| exercises | (189) |
| reader | (188) |
| task | (186) |
| find | (185) |
| like | (183) |
| each | (181) |
| you | (177) |
| items | (176) |
| up | (176) |
| very | (176) |
| part | (175) |
| time | (175) |
| paragraph | (170) |
| writer | (170) |
| between | (168) |
| well | (168) |
| new | (167) |
| way | (165) |
| skills | (164) |
| unit | (164) |
| written | (164) |
| papers | (158) |
| conclusion | (157) |
| could | (157) |
| same | (157) |
| teaching | (157) |
| information | (155) |
| after | (153) |
| vocabulary | (153) |
| did | (151) |
| into | (150) |
| three | (149) |
| found | (147) |
| listening | (147) |
| any | (143) |
| no | (143) |
| our | (143) |
| know | (140) |
| questions | (140) |
| word | (140) |
| he | (139) |
| read | (139) |
| teacher | (139) |
| question | (135) |
| content | (134) |
| ideas | (134) |
| essays | (132) |
| its | (132) |
| results | (131) |
| too | (131) |
| activities | (129) |
| category | (129) |
| good | (128) |
| help | (128) |
| letter | (128) |
| subject | (128) |
| main | (126) |
| who | (126) |
| important | (125) |
| would | (125) |
| people | (124) |
| your | (124) |
| me | (123) |
| method | (122) |
| then | (122) |
| his | (121) |
| than | (119) |
| thesis | (119) |
| intermediate | (118) |
| second | (118) |
| present | (117) |
| teachers | (117) |
| number | (116) |
| aim | (115) |
| many | (115) |
| does | (114) |
| order | (114) |
| she | (114) |
| analysis | (113) |
| attention | (113) |
| knowledge | (113) |
| type | (113) |
| get | (112) |
| form | (111) |
| give | (111) |
| school | (111) |
| given | (110) |
| speaking | (110) |
| story | (110) |
| readers | (109) |
| categories | (108) |
| four | (108) |
| another | (107) |
| parts | (107) |
| according | (106) |
| course | (105) |
| general | (105) |
| level | (105) |
| following | (104) |
| types | (104) |
| both | (103) |
| may | (103) |
| exercise | (101) |
| made | (101) |
| mistakes | (101) |
| point | (101) |
| been | (100) |
| paragraphs | (100) |
| units | (100) |
| where | (100) |
To test this hypothesis, I generated the KWIC concordance of the RRS and analyzed the citations for the definite article. Of the 1,680 occurrences, 103 were eliminated, as these were quotations from various sources. Of the remaining 1577 citations, I hypothesized erroneous uses would reach about 100, or about every sixth in one hundred co-texts.
The hypothesis was rejected: the total number of errors in the use of the definite article was 43. (See Appendix N for the erroneous samples, pp. 223-224.) The result shows the effectiveness of students' learning and applying the rules of using the definite article. However, as the study could not investigate the frequency of error of not using a definite article, the finding cannot be regarded as conclusive. Also, as co-texts cannot always provide sufficient information on context, the 1,577 samples may have contained more erroneous uses, which could not be determined on the basis of subjective parsing.
To test the hypothesis, the frequencies of these phrases were tabulated for the main corpus and the three subcorpora. The results are shown in Table 23.
Table 23: The frequencies of contrasting transitional phrases in the JPU Corpus and two subcorpora in sentence-initial position
| Phrase | JPU | WRSS | PGS |
| But | 308 | 75 | 61 |
| However | 138 | 23 | 47 |
| Still | 21 | 7 | 3 |
| Yet | 24 | 3 | 2 |
| On the other hand | 35 | 3 | 13 |
| Nevertheless | 25 | 5 | 7 |
As the table indicates, Hypothesis 2 has been confirmed: in sentence-initial position, the coordinating conjunction is most frequent in the main corpus and in the two writing subcorpora, with four of the transitional phrases represented by much lower frequencies.
One early insight I gained as a writing tutor into both native speaker and non-native speaker academic texts was the frequent use of the phrase "mentioned above," and its many active and passive variants. I identified three potential problems with this usage. First, on many occasions, the act of mentioning appeared to be a form of hedging, referring to an important point in the argument made earlier. Instead of finding a "mention" of these points, I would often locate a discussion, a definition, an illustration. The first problem, then, was that of validity. The second reason I became interested in the phrase was related to the adverbial component. Referring to the antecedent as being "above" appeared to characterize most formal text types, such as those in the legal profession, and in instructions. Its use in academic writing may contain the intentional or unintentional desire to make the text more formal than one may consider necessary. The writing courses aimed to sensitize students to this issue so they could look for alternative expressions. The third problem area was maybe the most relevant from a linguistic and pedagogical point of view: what many authors referred to this way appeared in the previous sentence. While another frequent use of the phrase appears to be in concluding sections of papers, with the adverb being an all-purpose filler for "in this paper," the frequency of the phrase was also high in sentences making an anaphoric reference to a point in the previous sentence. In these contexts, simple deictic phrases would suffice.
Hypothesis 3 suggested that there would be a relatively high frequency of "above" in anaphoric verbal phrases, and that a significant verbal collocate would be mention. Further, the hypothesis claimed that in the PGS and WRSS these frequencies would drop, as a result of the practice students had in those courses. To verify or reject it, the hypothesis was submitted to the following analysis. First, I obtained the KWIC concordances for the variants mentioned above and above mentioned. The frequencies of these expressions were recorded for the main corpus and the two subcorpora, as shown in Table 24.
Table 24: The frequencies of "mentioned above"/ "above mentioned" in the JPU Corpus and two subcorpora
| JPU | WRSS | PGS |
| 24 | 1 | 0 |
The hypothesis has been confirmed by the test, as shown in the table. To determine the level of statistical significance of the finding, however, I ran the chi-square test on the data. As is clear from Table 25, over 23 occurrences of the phrase were observed in the non-writing subcorpora (Rest of JPU). I tabulated this data, as shown in Table 25.
Table 25: Frequencies of the phrase in the non-writing subcorpora (RRS, ES, LPS) and the two writing subcorpora
| WRSS | PGS | Rest of JPU |
| 1 | 0 | 23 |
The chi-square value of 46.45 (df = 2) was significant (p < 0.001), lending support for the hypothesis that students in the non-writing courses used significantly more such phrases than in the writing courses. In this instance, it appears that both pedagogical and statistical significances were present.
In noting these occurrences I located a number of similar variants in the main corpus. These included two main types of phrase: past participle + above and definite article + above + noun phrase (such as listed above, described above, detailed above and the above facts, the above criteria, the above writers, and even, occurring twice, the above paragraph).
This hypothesis was a broad one: it suggested that aims would be primarily identified by the would like + to infinitive structure (Type 1). For statements of method and topic sentences, the I will construction would be more frequent (Type 2). To test this claim, I ran the KWIC concordance on the full corpus and analyzed the keyword I, identifying patterns that suggested significant collocates in the two types. Then I recorded the frequencies of the individual patterns and rank ordered the frequency of collocates. The results are shown in Table 26, with the frequency of the performative in parentheses. (See a sample of the two types of the citations in Appendix O, pp. 225-226.)
There were a total of 44 occurrences of Type 1, whereas 93 of Type 2 patterns. Hypothesis 4 was confirmed: Type 2 expressions were more frequently associated with the modal auxiliary will. These were not only more frequent than Type 1 patters, but also showed a wider variety and more explicitness. (The pedagogical application of the finding will be discussed later in this chapter.)
Table 26: Thesis statements, topic sentences and statements of method expressed by the I would like to structure and I will in the JPU Corpus
| I would like to | I will |
| analyse / ze (11) | |
| examine (10) | |
| present (7) | |
| attempt (6) | |
| show (5) | |
| (4) examine, focus on, point out | point at / out (4) |
| (3) analyse / ze, present | (3) discuss, focus on, give analysis/classification/tips, introduce, show, use |
| (2) emphasise / ze, find out, get answer | (2) check, concentrate on, deal with, demonstrate, describe, evaluate, investigate, provide data/view |
| (1) answer question, call reader's attention, clarify deal with, describe, explore, get to know, give suggestions, highlight, prove, stress, suggest, touch upon, try, write | (1) address, argue, compare, delineate, devote space for, emphasize, draw conclusion, have a look, highlight, list, make analysis, make attempt to find, monitor, report, shed light, study, sum up, summarize, survey, take the mean, tell, try, turn to |
Hypothesis 5 investigated JPU students' use of the stem. The two corpora used in Granger's study (in press) were made up by 251,318 and 234,514 words, respectively. For comparative purposes, the combined subcorpora of the PGS and WRSS were used--these are valid sources for such data both in terms of text types in them and tokens: the combined length of the two subcorpora is 231,211 words. The KWIC concordance of I think [that] was captured for the PGS and the WRSS, and the frequency of the phrase compared with those in the other two samples. The result is tabulated in Table 27 (showing the frequencies normalized for 200,000 words).
The difference between the use of the phrase by EFL learners and native users was confirmed. As can be seen, the difference between frequencies in the L1 and the combined Hungarian learner subcorpora was markedly lower than between the ICLE and the L1 corpus.
Table 27: Frequencies of "I think that" in the three corpora
| ICLE | L1 writers | PGS and WRSS combined |
| 72 | 3 | 21 |
However, one is cautioned not to overgeneralize from the result that both L2 learner corpora contained higher frequencies of the phrase. The main reason for this caveat is that the relative frequency of I think [that] in the individual subcorpora is hardly significant. Also, we know little of the purpose and audience of the individual scripts contained in the ICLE and the native sample. In the PGS and the WRSS, the use of the phrase cannot be regarded as "overuse" unless one further explores these two text organizing principles. As this was not performed on the other two corpora, the hypothesis that learners overuse I think [that] cannot be confirmed--further studies are necessary. For the future analysis, the variables of purpose and audience have to be controlled and validated for both the L1 and the L2 samples.
Hypothesis 6 was based on the experience that introduced to JPU English majors the notion that when aiming at concreteness in academic writing, authors need to review their use of such adverbs so that their intentions may be transparent to readers. As Appendix H shows (p. 213), a component of a WRSS syllabus introduced the "Very-less week" program so as to make students aware of the issue. The hypothesis claimed that the adverb would still have a high frequency in the JPU Corpus, but that it would be less significant in the PGS and the WRSS.
As Appendix M reveals (pp. 220-222), very is ranked 83rd in the raw frequency list of the full corpus. To test the hypothesis on its distribution, I tabulated the frequencies for very in the PGS, the WRSS, and the non-writing subcorpora (RRS, ES, and LPS), and then calculated the chi square index to determine whether differences were statistically significant. When looking at Table 28, we can see that the lowest frequency was found in the WRSS, followed by the PGS, and that the highest figure was obtained for the rest of the corpus.
Table 28: Distribution of the frequency of very in the three subcorpora
| PGS | WRSS | Rest of JPU |
| 176 | 81 | 299 |
The chi square test revealed that the differences were significant (c2 = 128.9, df = 2, p < 0.001), verifying the hypothesis: the WRSS scripts contained much lower frequencies of very than either of the other two subcorpora. Whether or not this tendency can be observed in the long run requires further study, however.
One form of clutter of thought and of expression, in both L1 and L2 writing, is the use of imprecise vocabulary that does not readily lend itself to interpretation. The writing pedagogical experience of the past semesters at JPU has familiarized me with the issue, and by reading and commenting on students' drafts, I aimed to enable participants to work on clarity and specificity. This is a long process. To investigate a part of the related segments of the JPU Corpus, I looked for the occurrence of five words that seemed to be frequent in student writing: two nouns, two adjectives, and an abbreviation: case, thing, good, interesting, and etc. Hypothesis 7 claimed that the frequency of these words would be lower in the PGS and the WRSS than in the rest of the JPU Corpus, as students in the WRS courses had the advantage of practicing learning and revising strategies for the avoidance of these vague terms.
To test the hypothesis, I obtained the frequency of the lemmas CASE and THING, and of the two adjectives and the abbreviation, and calculated the c2 value for each set of distribution. The results appear in Table 29.
Table 29: The distribution of and statistical information for the frequency of each of the five words in the three subcorpora
| Word | PGS | WRSS | Rest of JPU | c2 | df | p |
| case | 121 | 76 | 146 | 8.77 | 2 | < 0.05 |
| thing | 74 | 46 | 159 | 74.46 | 2 | < 0.001 |
| good | 128 | 90 | 163 | 20.97 | 2 | < 0.001 |
| interesting | 68 | 22 | 61 | 26.73 | 2 | < 0.001 |
| etc. | 19 | 5 | 68 | 71.28 | 2 | < 0.001 |
The table reveals that for each word, the differences of frequencies were significant; the lowest level for case, and for each of the other four observations, the high statistical significance level of < 0.001 was obtained. This verifies the overall hypothesis that in the writing subcorpora specificity of expression was not marred by the frequent use of these words.
As far as the fact that is concerned, Granger (in press) noted that L2 student writers demonstrate excessive "over-use" of the phrase, also citing Lindner (1992), who studied a corpus of German EFL texts and suggested that the high frequency of the phrase can be attributed to students' perception that expository and argumentative writing has to carry high "verbal factualness."
The hypothesis claimed that there would be lower frequencies for the fact that and in order to in the PGS and the WRSS than in the rest of the JPU Corpus. To test the hypothesis, the same procedure was applied as for testing the previous one. The results appear in Table 30.
Table 30: The distribution of and statistical information for the frequency of the two phrases in the three subcorpora
| Phrase | PGS | WRSS | Rest of JPU | c2 | df | p |
| the fact that | 24 | 27 | 75 | 38.98 | 2 | < 0.001 |
| in order to | 35 | 50 | 48 | 2.98 | 2 | NS |
Note: NS = not significant
As the table shows, part of the hypothesis was confirmed by the test: the phrase the fact that is significantly more frequently used in the three subcorpora than either the PGS or the WRSS. However, no similar trend was observed for the phrase in order to--the distribution of its frequency being fairly even. The second part of the hypothesis was thus rejected.
Of the 107 papers, 33 discuss aspects of Hungarian newspaper articles published on the day students were born. As section 3.3.3.2.1 suggested, this option was designed to include a personal intrinsic motive for students to begin to want to do research. The high number of such papers seems to prove that the approach was successful. However, a large number of other content and method types are also represented in this subcorpus--these are listed in Table 31.
Table 31: Content and method types in the 107 research papers in the WRSS
| Type | Number |
| Newspaper articles from the day student was born | 33 |
| Analysis of students' writing | 30 |
| Survey among students | 20 |
| Word processing for writers | 4 |
| Types of revision | 3 |
| Analysis of WRS course tasks, readings, procedures | 2 |
| Analysis of Umberto Eco's writing | 2 |
| Survey among teachers | 2 |
| Analysis of teacher's comments on portfolios | 1 |
| Analysis of essay test markers' comments | 1 |
| University syllabus analysis | 1 |
| Analysis of writing textbooks | 1 |
| Introductions in 75 Readings | 1 |
| Analysis of introductions in HUSSE Papers | 1 |
| Analysis of narrative essay | 1 |
| Analysis of Zinsser's notion of simplicity | 1 |
| Models of paragraph | 1 |
| Analysis of structure in research papers | 1 |
| Proficiency test for high-school students | 1 |
The hypothesis claimed that the type of introductory sentence chosen by students would affect the length and vocabulary of the first sentence. Besides, I aimed to gather descriptive information on the frames of the first sentences (Andor, 1985). To test the hypothesis, the first sentence of each introduction was saved as a separate document, which was then processed by the concordancer, also calculating tokens, types, and average sentence length in different groups: in short, the introductory sentences were treated as a mini corpus. Besides these measures, a table was also designed, listing the types of introductions observed.
The mini corpus of these sentences contained 1,946 words, of 579 types, a ratio of 3.36. The average length of a sentence was 18.18 words.
To test the validity of the hypothesis, I performed a content analysis of the sentences, using categories. Initially, I identified five categories to capture the types of frames of the introductions, representing different approaches I knew students employed in their texts. These included
Table 32: The rank order of types of introductory sentences in the WRSS sample
| Rank | Type | Frequency |
| 1 | definition | 47 |
| 2 | personal | 15 |
| 3 | obvious | 12 |
| 4 | historical | 10 |
| 5 | aim | 7 |
| 6 | method | 4 |
| 7 | five | 3 |
| 8 | citation, reader, ? (obvious- definition; obvious-historical) | 2 |
| 9 | narrative, question, title | 1 |
To confirm or refute the hypothesis that the type of introduction affected the length of the first sentence, I devised the following procedure. Of the 107 sentences, I selected the 83 that belonged to the most popular options. As the rest of the sentences were each represented by only seven or fewer examples, they were eliminated from the investigation, as their low frequency would not have given sufficient information on length distribution. After this, I calculated the length of the each of the 83 sentences in the four main groups. When these indices were obtained, I determined the effect of the type on length via one-way analysis of variance (ANOVA). Table 33 presents the statistics.
Table 33: Results of the analysis of variance on the data of length of first sentences
| Source | df | SS | MS | F | Pr[X>F] | |
| Between | 3 | 199.14 | 66.38 | 1.20 | 0.31 | |
| Residual | 80 | 4410.10 | 55.13 | |||
| Total | 83 | 4609.24 | ||||
| Grand Sum = 1504.00 Grand Mean = 17.90 |
According to the figures in the table, the ANOVA findings are inconclusive: no significant differences were found (F = 1.20; p = 0.31). The type of sentence did not affect its length. This result points to the need to analyze the full introductory paragraphs, so as to reveal how type may affect its size and structure.
The mini corpus of the concluding sentences was made up by 105 sentences--two fewer than in the introductory mini corpus, as two students did not include a conclusion in the submission. The sample contained 2,389 words, representing 818 types, resulting in a ratio of 2.92. The rounded average length of sentence was 23 words. When compared with the same statistics for the introductory mini corpus, we can see that concluding sentences tended to be somewhat longer, using more types of words on average than the introductory ones. However, the differences cannot be regarded as marked, as shown in Table 34.
Table 34: Descriptive statistics of the two mini corpora
| Index | Introductions | Conclusions |
| Tokens | 1946 | 2389 |
| Types | 579 | 818 |
| Ratio | 3.36 | 2.92 |
| Average length | 18.18 | 22.75 |
As for the typology of the last sentences, the following eight categories were set up initially:
Table 35: The rank order of types of concluding sentences in the WRSS sample
| Rank | Type | Frequency |
| 1 | qualitative | 47 |
| 2 | practical | 26 |
| 3 | obvious | 9 |
| 4 | unclear | 7 |
| 5 | quantitative | 5 |
| 6 | question | 3 |
| 7 | hypothesis, limitation, non-sequitur | 2 |
| 8 | citation, reader | 1 |
The two most popular last statements in the mini corpus were represented by the qualitative and the practical outcome types. This result is in line with previous pedagogical experience suggesting that student writers favored these options. They also appear to be relevant for the types of research design the scripts were based on. However, the high ranking of the obvious type of sentence and of the unclear category calls attention to the need for more practice in the area of writing conclusions. As the next section on the pedagogical exploitation of the corpus will show, this can be facilitated by channeling back the information on students' scripts to the writing course, using authentic student texts.
Finally, to test the relationship between type of concluding sentence and length, I employed a one-way analysis of variance test for types. I used the sentence-length data for the qualitative and practical groups, and the combined length for the obvious and unclear types. The results appear in Table 36.
Table 36: Results of the analysis of variance on the data of length of last sentences
| Source | df | SS | MS | F | Pr[X>F] | ||
| Between | 2 | 862.29 | 431.14 | 4.34 | 0.02 | ||
| Residual | 86 | 8539.22 | 99.29 | ||||
| Total | 88 | 9401.51 | |||||
| Grand Sum = 1978.00 Grand Mean = 22.22 | |||||||
| Qualitative Mean: 23.36 | |||||||
| Practical Mean: 24.23 | |||||||
| Obvious + Unclear Mean: 15.62 |
The table shows that the analysis revealed a significant effect of type of concluding sentence and length: F = 4.34; p = 0.02. Whereas the mean length of the qualitative and practical type of concluding sentences was almost identical (23.36 vs. 24.23 words), the length of the combined group of obvious and unclear type sentences was 15.62, for which the analysis confirmed significant variation. Thus, Hypothesis 10 claiming that type of sentence affected length was verified.
The statistical finding may imply that students who wrote the type of concluding sentences that were categorized as either unclear or obvious themselves had difficulty ending their papers, and thus they opted to write much shorter sentences than others. This hypothesis, however, does not intend to suggest that there is correlation between quality of conclusion and quantity of concluding sentence. Also, factors such as grammatical accuracy of the sentences, the type of concluding sentence and the full concluding paragraph, and the appropriacy of the type of conclusion in relation to the body text of the research paper are to be investigated in the future.
As Chapter 2 demonstrated, DDL is often used for individual study. Applying the classroom online concordancing technique, the tutor and the student focus on relevant issues, arising from either the student's or the tutor's initiative. Parallel concordances are exploited, as in Johns's (1997b) kibbitzer technique. However, the corpus of students' texts facilitates pair and group work, too. In several WRS courses, students were provided with handouts that featured samples of their own writing, the purpose being that I aimed to draw attention to the importance of lexical and collocational choices. As authorship was hidden in these examples, the affective filter was lowered, yet the studying and discussing of the co-texts allowed for the effective use of the monitor (Krashen, 1985).
The first example posed the question of how appropriate it is to refer to students as "ours." Especially in the RRS and the PGS, authors seemed to prefer the use of the first person possessive pronoun as a collocate of "pupils" and "students." Example 1 aimed to raise the issue and allow for group discussion.
Example 1: Worksheet on possessivesIn academic writing, participants in research and in the wider educational context should always be referred to as that: individuals. No matter how much we like them, students and pupils we teach should not become our property. In the following concordance lines, the authors have appropriated students. With a partner, discuss your views on this issue, and then rewrite the co-texts by replacing the possessives. In a number of instances, several alternatives are possible.
| 1 | tions about the television and most of | my pupils agree with her point of view. Barbar |
| 2 | cially on the introduction part. When | my pupils had finished their works I read each |
| 3 | scussion. It is fascinating for me that | my pupils liked that Barbara - the writer of the |
| 4 | opic's historical background. Some of | my pupils opted for this method. They wrote about t |
| 5 | irstly, I reply on the second question. | My pupils were satisfied with their own introdu |
| 1 | and analyse it. The next step was that | my students had to fill in a questionnaire whi |
| 2 | of the original introduction and what | my students have done. I wanted to know how t |
| 3 | ng the original introduction and using | my students' opinions about this part ot the te |
| 4 | the specific. My last question was for | my students what they think, what is a good int |
| 5 | ussion. I am going to prove it through | my students' works. There was a boy who used |
The purpose of the second example was to present to students the task of reporting the author's aims in a research paper. I had sampled the introductions of their submissions and found a limited lexis of verbs that announced the purpose and method of the paper. Although most of this vocabulary appeared to be relevant to the main texts they were clipped from, I realized there was a need to raise students' consciousness of the importance of using more specific verbs in these sections. The following handout was produced.
Example 2: Worksheet on reporting verbsWhen you read or write a paper, you often find that reporting what the researcher will do greatly facilitates the clarity and relevance of the results. With a partner, list ten verbs, appearing in introduction, that indicate what the paper will "do." After that, skim the worksheet and underline those you listed.
| 1 | and distribution. In this paper | I will address the latter of the issues, |
| 2 | links with the rest of the paper. | I will also scan for the thesis sentences |
| 3 | were written in 1996. | I will analyse my essay's introductions |
| 4 | texts, conclusions and references. | I will check whether there are |
| 5 | and their analyses. In my paper | I will concentrate on semantic relations |
| 6 | are analysed in a text. | I will concentrate on pronouns in the |
| 7 | a foreign language - writing skills. | I will evaluate my essays in terms of |
| 8 | that makes a text coherent. | I will examine repetition in the |
| 9 | and Oleanna - of the chosen essay. | I will examine the text according to |
| 10 | making the writing more effective. | I will introduce different revision |
| 11 | many hyponyms and antonyms, but | I will introduce some here. |
| 12 | The hypothesis that | I will present and discuss in some detail in |
| 13 | in terms of their structures; | I will survey the introductions, the body |
After the task, students discussed the use of verbs they listed but did not find on the worksheet.
In recent JPU ED writing courses, undergraduate and postgraduate students have received such tasks. Combined with the tutor's assessment of their work, these guides aimed to raise students' awareness of discrete features of their writing, positive and negative qualities that I commented on in the final assessment but also regarded as suitable for further study. The use of the guides followed weeks of work on the text: the students and the teacher had consulted the merits of the submission and the latter suggested areas for thematic, structural, and grammatical improvement. It stands to reason that individual students' consciousness of their writing strategies and skills grew as a result--what the study guides added to this process was the opportunity to focus on one factor of their writing. Example 3 presents a study guide for a student who was asked to consider replacing the all-purpose noun "things" for more specific terms in the paper.
Example 3: Replacing things
| 1 | or a comic strip. They are usually funny | things in some connection with the other parts of the |
| 2 | to underline, to write in bold type and other | things. One of the six "Language awareness" sections |
| 3 | language in a variety of forms ( desribing | things, people, places ...; story-telling ...etc). Students |
| 4 | They should be able to inquire about these | things. They should be able to express agreement an |
Example 4 is similar to the previous one: it, too, is concerned with concrete vocabulary, this time challenging the writer to evaluate her data and identify more precise terminology instead of "good."
Example 4: What makes a good ***?
| 1 | revises the essential rules of how to write a | good composition, from a good introduction to a good |
| 2 | composition, from a good introduction to a | good conclusion. In this exercise students are supposed |
| 3 | from what you are trying to say. It's a | good idea to check through your own written work to |
| 4 | feelings; word order; semantic markers; a | good introduction and conclusion. Punctuation is dealt |
| 5 | of how to write a good composition, from a | good introduction to a good conclusion. In this exercise |
Potentially the most intrinsically motivating of this type of study guides are those that invite the student to scan and reflect on the co-texts of the first person singular pronoun. When such use is frequent, the student can discover new contexts for the theme, enabling her to verify a focus.
Example 5: What I could and would
| 1 | I could not cope with the problem of expressing my ideas in an exact way, consequently I | |
| 2 | I could not get rid of my second person sigular personal pronouns. I continuously gave | |
| 3 | I could so as to fulfill the requirements of a good essay which is subjective now I know. At | |
| 4 | I tried to be more careful and accurate as a whole. I managed to eliminate most of those | |
| 5 | I tried to translate expressions word- by-word in lacking an up-to-date dictionary such as | |
| 6 | I tried to use the language as creatively as I could so as to fulfill the requirements of a good | |
| 7 | I used a lot of abbreviations ("can't" or "isn't") and noteforms (underlining important | |
| 8 | I wanted a quick result, therefore the presentation of my work was simply awful | |
| 9 | I wanted to be more wise than I really was. It is best represented by the fact that I wrote a | |
| 10 | I wanted to have my own special style even if it was ridiculous sometimes to read such | |
| 11 | I would be still happy but then came learning to write in the Writing Centre where these | |
| 12 | I would like to develop to be an academic English writer. | |
| 13 | I would like to give a clear chart about the strong and weak points of my methodology | |
| 14 | I would like to point out my mistakes and to give suggestion how I can refine my works in |
Both the classroom and the individual study guides aimed to raise students' awareness of their own writing, so they were in a better position to continue to improve editing and revising skills. By using students' original texts in the early stages of developing a research paper, I aimed to help students from a discourse community in a sheltered environment. Scaffolding and focusing on discrete elements of their writing was not employed to focus on error; rather, the objective was to highlight features that represented choices writers made in the process of exploring a field. The study guides also encouraged exploitation of students' texts after the course ended. The concordance revealed lexical choices that were often subconscious. Used in combination with more traditional task types, the concordance-based study guides can result in increasing levels of learner autonomy, an essential criterion for development in the long run.
The verbs that were shown to collocate with I will can be listed and the following worksheet prepared for pair work:
Example 6: Recycling students' speech actsThe verbs listed below are clipped from previous students' research papers. They were used in the Introductory and Method sections. With your partner, discuss what these verbs indicate in a paper. Then, suggest which three of the verbs were most frequently used by the students.
| address | analyse | analyze | argue | attempt |
| check | compare | concentrate on | deal with | delineate |
| demonstrate | discuss | evaluate | examine | focus on |
| give analysis | point out | present | summarize | survey |
The JPU Corpus sample can facilitate the preparation of a large number of such authentic study guides.
There are limitations, however. The analysis of the corpus could not take advantage of tagging and the use of more sophisticated concordancing software. For future analytic studies, word-class and syntactic tagging has to be added. Another limitation is that the corpus contains no data from courses taught by other teachers at the department. For the corpus to represent such diversity, this avenue also has to be explored.
Yet even with these limitations, the corpus is representative enough for valid linguistic and pedagogical application. In the next phase of its development, I am planning to focus on incorporating first and last versions of personal narrative essays and research papers. A subcorpus will provide data for analyzing lexical and discourse changes a text undergoes during the process of revision. This parallel set of data will enable future research on vocabulary choice and size. Also, a growing corpus will continue to provide the raw material for classroom concordancing and study guides.
A second plan is to include the test essays written in the past six years as part of the proficiency tests. The current size of that handwritten data set is about half a million words. As the conditions of the essay writing test have differed greatly from those that gave rise to scripts currently incorporated in the JPU Corpus, a more refined view of learner written English may emerge. Together with the present structure of the corpus, these two sets of data can also facilitate diachronic studies of various features of language use under different circumstances.
Yet another vista of future work is the incorporation of students' theses in the corpus. The majority of writers who have contributed to the WRS and PGS subcorpora are still at JPU and will be submitting their dissertations in the next few years. Obtaining the electronic version of these texts would enable research to investigate the final outcome of university education.
Finally, to bring about an even more structured synthesis of corpus methods and writing pedagogy, a new type of annotation will be worked out: pedagogical corpus annotation (PCA). PCA is what teachers of writing already do all the time: they mark up text by students, who, in turn, attempt to understand, critique and apply some of the comments. This part of the pedagogical process, however, is often lost to research and pedagogy when the comments are shared. With PCA made part of the corpus, teachers' commentary can be incorporated with the student text, and fine-tuned analysis would be made possible. Applications of PCA could include the testing of the consistency and reliability of types of comments across comments, as well as the validation of the comments teachers make. Another use lies in the contrastive analysis of discourse and style in students' and teachers' texts. Such an incorporation of teacher comments can be managed when learners submit scripts on disk, so that the reader can add comments via either a word processor's annotation or footnote module or a dedicated co-author program, such as Prep 1.0 (Chandhok, Kaufer, Morris, & Neuwirth, Miller, & Erion, 1993). Besides, students' own reflective notes about the purpose and evaluation of their own texts and those of their peers can enhance the data of present-day learner corpus projects.